摘要
InfluxDB是最火热的时序数据库,它的高并发写入、数据压缩存储和低查询延时让人心动不已。它就像一位优秀的情人,始终陪伴着你,让你感到温暖和安心。
正文
通过Python将监控数据由influxdb写入到MySQL
一.项目背景
我们知道InfluxDB是最受欢迎的时序数据库(TSDB)。InfluxDB具有 持续高并发写入、无更新;数据压缩存储;低查询延时 的特点。从下面这个权威的统计图中,就可以看出InfluxDB的热度。

InfluxDB可以作为 性能监控、应用程序指标、物联网传感器数据和实时分析等的后端存储。
我们的DB性能监控体系是基于Telegraf+InfluxDB+Grafana组件搭建,如下图所示。
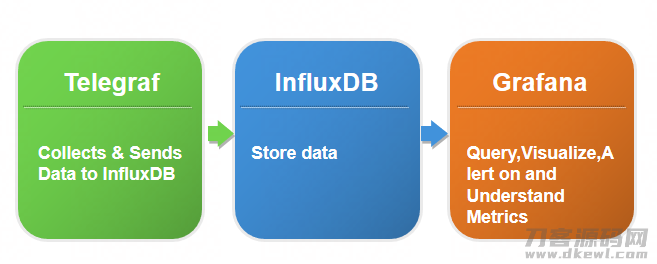
但是这个体系没有和既有的CMDB打通,例如,不清楚公司目前有多少台数据库实例已部署了监控?是不是有部分实例的监控漏掉了?而目前公司CMDB的信息都保存在了MySQL数据库中,所以,需要先实现 Influxdb 与 MySQL DB 的数据互通互联 。此功能的实现时借助Python完成的。
在此项目中,为便于说明演示,抽象简化后,需求概况为:将InfluxDB中保存的各个服务器的IP查询出来保存到指定的MySQL数据库中。进一步分解任务,因为measurement(表)为disk 存储有 Server host的数据,根据其命名规则,可host逆向拼凑出Server IP数据。
所以,此需求简化为:从InfluxDB的disk【measurement、表】中找出host【tag】对应的value,加工处理后,保存到MySQL。
二.安装运行环境遇到的错误
1.TypeError: Struct() 错误
调试时,报如下错误,查找资料发现,和python版本有关。
错误信息如下:
...... File "/usr/lib/python2.7/site-packages/influxdb/client.py", line 527, in query expected_response_code=expected_response_code File "/usr/lib/python2.7/site-packages/influxdb/client.py", line 361, in request raw=False) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 129, in unpackb ret = unpacker._unpack() File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 671, in _unpack ret[key] = self._unpack(EX_CONSTRUCT) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 644, in _unpack ret.append(self._unpack(EX_CONSTRUCT)) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 671, in _unpack ret[key] = self._unpack(EX_CONSTRUCT) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 644, in _unpack ret.append(self._unpack(EX_CONSTRUCT)) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 671, in _unpack ret[key] = self._unpack(EX_CONSTRUCT) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 644, in _unpack ret.append(self._unpack(EX_CONSTRUCT)) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 644, in _unpack ret.append(self._unpack(EX_CONSTRUCT)) File "/usr/lib/python2.7/site-packages/msgpack/fallback.py", line 697, in _unpack return self._ext_hook(n, bytes(obj)) File "/usr/lib/python2.7/site-packages/influxdb/client.py", line 1247, in _msgpack_parse_hook (epoch_s, epoch_ns) = struct.unpack(">QI", data) TypeError: Struct() argument 1 must be string, not unicode
报错的python版本为Python 2.7.5,查看资料,建议升级到2.7.7以上。为规避这个错误,我们将版本升级到了Python 3.6.8
2.升级安装Python 3.6.8
安装执行make install时报错,错误信息如下:
zipimport.ZipImportError: can’t decompress data; zlib not available make: * [install] Error 1
原因是缺少了zlib的解压缩类库,
解决方案,执行以下命令
yum -y install zlib*
3.引入influxdb插件报错
运行报错,提示信息如下:
.......... from influxdb import InfluxDBClient ModuleNotFoundError: No module named 'influxdb'
解决方案:
git clone https://GitHub.com/influxdb/influxdb-python.git cd influxdb-python pip3 install -r requirements.txt python3 setup.py install
成功安装的记录如下:
。。。。。。。。。。。。 Using /usr/local/lib/python3.6/site-packages Searching for urllib3==1.25.6 Best match: urllib3 1.25.6 Adding urllib3 1.25.6 to easy-install.pth file Using /usr/lib/python3.6/site-packages Finished processing dependencies for influxdb==5.3.1
验证是否成功安装,打开python输入
from influxdb import client as influxdb
如果没有错误信息,则表示安装成功
4.Python3 环境执行mysql报错
... import MySQLdb ModuleNotFoundError: No module named 'MySQLdb'
环境测试
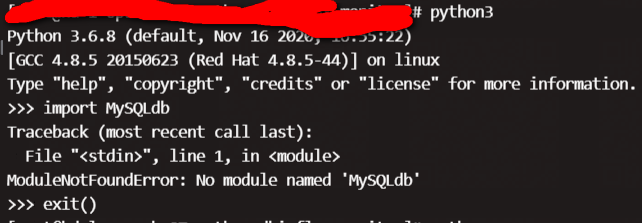
原因分析: Python 2安装的是mysql-python,而Python 3应该安装mysqlclient。
因此需要:
pip3 install mysqlclient
但是报错,错误信息如下:
Traceback (most recent call last): File "/usr/local/bin/pip3", line 11, in <module> load_entry_point('pip==1.5.4', 'console_scripts', 'pip3')() File "/usr/local/lib/python3.6/site-packages/setuptools-39.2.0-py3.6.egg/pkg_resources/__init__.py", line 476, in load_entry_point File "/usr/local/lib/python3.6/site-packages/setuptools-39.2.0-py3.6.egg/pkg_resources/__init__.py", line 2700, in load_entry_point File "/usr/local/lib/python3.6/site-packages/setuptools-39.2.0-py3.6.egg/pkg_resources/__init__.py", line 2318, in load File "/usr/local/lib/python3.6/site-packages/setuptools-39.2.0-py3.6.egg/pkg_resources/__init__.py", line 2324, in resolve File "/usr/local/lib/python3.6/site-packages/pip-1.5.4-py3.6.egg/pip/__init__.py", line 9, in <module> from pip.log import logger File "/usr/local/lib/python3.6/site-packages/pip-1.5.4-py3.6.egg/pip/log.py", line 9, in <module> from pip._vendor import colorama, pkg_resources File "/usr/local/lib/python3.6/site-packages/pip-1.5.4-py3.6.egg/pip/_vendor/pkg_resources.py", line 1423, in <module> register_loader_type(importlib_bootstrap.SourceFileLoader, DefaultProvider) AttributeError: module 'importlib._bootstrap' has no attribute 'SourceFileLoader'
原因分析:
pip-1.5.4,远低于pip目前的版本,
解决方案:
下载新的版本安装更新pip,下载网址https://pypi.org/project/pip/#files
例如下载了pip-21.1.1.tar.gz,安装步骤如下:
step 1
tar -zxvf pip-21.1.1.tar.gz
step 2
cd pip-21.1.1
step 3
python3 setup.py build
step 4
python3 setup.py install
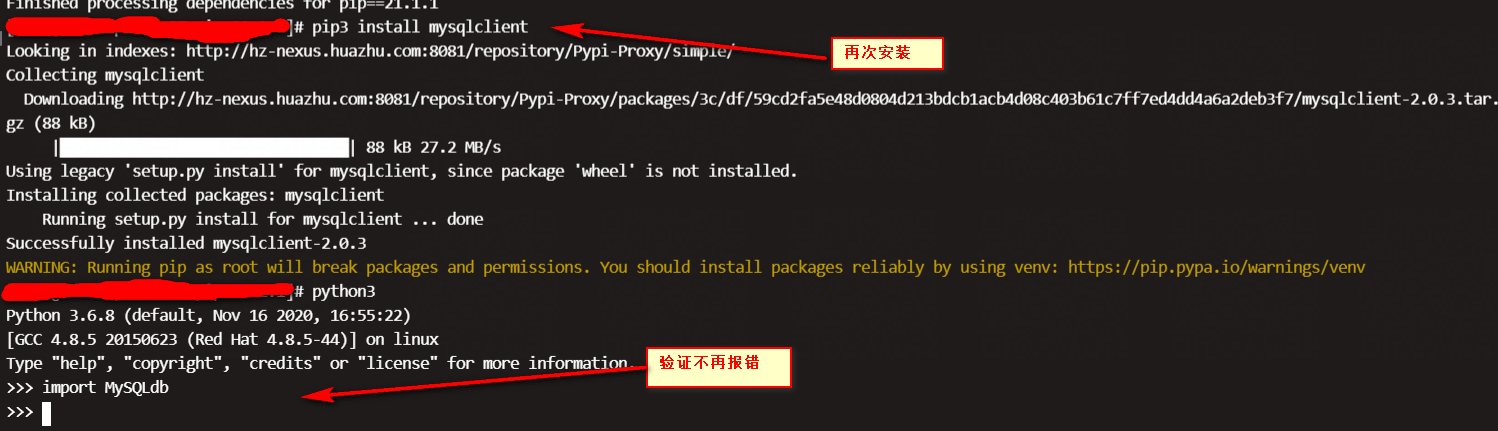
再次安装 mysqlclient
pip3 install mysqlclient
安装过程不再报错,验证安装OK。
三.部分代码说明
1.对象类型及属性查看–print(type(?))和print(dir(?))
因为我们平常对influxdb使用的相对较少,不像关系型数据库那么熟练,通过python查看influxdb数据,比较陌生,不知道返回值对象的类型是什么或者怎么操作。这时候可以通过print(type(?)) 和print(dir(?))来查看。
如下图,假如response是influxdb的query返回值。

print显示的返回信息如下:

注意 上面有一个 get_points 方法,不知道你找到了吗? 这个需要特别注意,后面我们就会讲到。
2. Getting all points
Using query() that returns data in ‘influxdb.resultset.ResultSet’ format.This is the sample output of the query():
Result: ResultSet({'(u'cpu', None)': [{u'usage_guest_nice': 0, u'usage_user': 0.90783871790308868, u'usage_nice': 0, u'usage_steal': 0, u'usage_iowait': 0.056348610076366427, u'host': u'xxx.xxx.hostname.com', u'usage_guest': 0, u'usage_idle': 98.184322579062794, u'usage_softirq': 0.0062609566755314457, u'time': u'2016-06-26T16:25:00Z', u'usage_irq': 0, u'cpu': u'cpu-total', u'usage_system': 0.84522915123660536}]})
Using rs.get_points() will return a generator for all the points in the ResultSet.
you can Filtering by measurement
rs = cli.query("SELECT * from cpu") cpu_points = list(rs.get_points(measurement='cpu'))
or you can Filtering by tags
rs = cli.query("SELECT * from cpu") cpu_influxdb_com_points = list(rs.get_points(tags={"host_name": "influxdb.com"}))
or you can Filtering by measurement and tags
rs = cli.query("SELECT * from cpu") points = list(rs.get_points(measurement='cpu', tags={'host_name': 'influxdb.com'}))
3.telegraf模板中关于host的命名
我们知道telegraf 模板中有host参数(默认在/etc/telegraf.conf设置),在grafana界面上可以根据这个host参数进行刷选,进一步定位到想要查看的 Server 或 DB 实例。因为公司有多个项目组,每个项目组负责不同的系统,有各自的DB Server 、实例。为了区分这个Server究竟属于那个项目组(Team),所以,我们在定义Host时,不是简单的赋值Server IP,而是 产品线 + Server IP的后两位。如此,也方便 监控、研发、运维的同学快速找到Server,判断相应的业务项目组。
例如 订单中心 所在的 DB Server 为 18.19.20.21 其host为 order_20_21;CRM 所在的 DB Server 为 18.19.22.23 其host为crm_22_23;ERP所在的DB Server 为 18.19.24.25其host为erp_24_25;app所在的DB Server 为 18.19.34.35其host为app_34_35;等等。
四 主要代码
1.在MySQL实例上创建保存Server信息的表
CREATE TABLE `monitor_serverdb` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ip_address` varchar(255) NOT NULL DEFAULT '', `datetime_created` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据行创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.连接MySQL的python文件db_conn.py
代码如下:
#!/usr/bin/python3 # -*- coding: UTF-8 -*- import MySQLdb # 打开数据库连接 db = MySQLdb.connect("server DB实例IP","DB 用户名","DB PWD","DB Name",charset='utf8mb4',port=数据库端口号)
3.连接InfluxDB的python文件collect_dbhost_telegraf_info.py
主要代码:
#!/usr/bin/python # -*- coding: UTF-8 -*- from influxdb import InfluxDBClient import pytz import time import dateutil.parser import datetime class DBApi(object): """ 通过infludb获取数据 """ def __init__(self, ip, port): """ 初始化数据 :param ip:influxdb地址 :param port: 端口 """ self.db_name = 'telegraf' self.use_cpu_table = 'cpu' # cpu使用率表 self.phy_mem_table = 'mem'# 物理内存表 self.traffic_table = 'net'# 接收流量表 self.disk_table = 'disk'# 磁盘表 self.client = InfluxDBClient(ip, port, 'DB UID', 'DB PWD', self.db_name) # 连接influxdb数据库 print ('test link influxdb') def get_telegraf_list(self): """ :param host: 查询的主机host (telegraf 配置参数中的host栏位) """ print ('step 1 check get deployment') response = {} telegraf_list = self.client.query('SHOW TAG VALUES FROM disk WITH KEY = "host";') return telegraf_list
4.执行文件collect_monitordb_info.py
#!/usr/bin/python # -*- coding: UTF-8 -*- import os import time from collect_dbhost_telegraf_info.py import DBApi ## get mysqldb connection import db_conn mysqldb = db_conn.db # use cursor cursor = mysqldb.cursor() ###数据收集前,清除之前收集的数据 sql_delete = "delete from monitor_serverdb " cursor.execute(sql_delete) mysqldb.commit() # 连接 influxdb # INFLUXDB_IP influxdb所在主机 # INFLUXDB_PROT influxdb端口 db = DBApi(ip='influxdb 所在主机', port='端口号') ###print(db) response = db.get_telegraf_list() #print (response) #print(type(response)) #print(dir(response)) disk_points = list(response.get_points(measurement='disk')) #print(disk_points) #print(dir(disk_points)) for disk_check in disk_points: ##print(disk_check) for host_key in disk_check.keys(): if host_key == "value": ##print(disk_check[host_key]) ##基于host的命名进行切割,分割符为_,返回值为列表 diskhost_split = disk_check[host_key].split('_') ##将列表中的后两个元素提取出来,组成server IP,因为集团IP前两位一样,所以如此拼凑。 ##print(type(diskhost_split)) ##print(diskhost_split) ##print(diskhost_split[-2:-3:-1][0]) disk_ip = '110.' + '120.' + diskhost_split[-2:-3:-1][0] + '.' + diskhost_split[-1:-2:-1][0] print(disk_ip) sql_insert = "insert into monitor_serverdb(ip_address) " \ "values('%s')" % \ (disk_ip) cursor.execute(sql_insert) mysqldb.commit()
5.执行命令如下
python3 collect_monitordb_info.py
五.参考资料
1.https://stackoverflow.com/questions/38040644/processing-influx-db-output-of-influxdb-resultset-resultset/38055771
2.python 获取指定字符前面或后面的所有字符
https://www.cnblogs.com/syw20170419/p/10969191.html
3.https://www.cnblogs.com/jadexia/p/7797791.html
4.https://blog.csdn.net/Linking_sea/article/details/112690038
5.InfluxDB 入门
https://www.jianshu.com/p/f0905f36e9c3
6.https://grafana.com/grafana/
7.https://github.com/dbarun/mysql_archiver#readme
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0