摘要
C 20的协同程序比物理学进程还要强大,它是量化策略的编码实体模型,能够持续接收事情并解决问题。它广泛应用于手机软件、GUI、内嵌式机器设备和互联网服务器端等领域。华为云服务小区分享了这个强大的工具。
正文
比物理学进程都功能强大的C 20的协同程序,你能用吗?
引言:量化策略(event driven)是一种普遍的编码实体模型,其一般会有一个主循环系统(mainloop)持续的从序列中接受事情,随后分发送给相对应的涵数/控制模块解决。普遍应用量化策略实体模型的手机软件包含图形界面设计(GUI),内嵌式机器设备手机软件,互联网服务器端等。
文中共享自华为云服务小区《C 20的协程在事件驱动代码中的应用》,全文创作者:能飞乐 。
内嵌式量化策略编码的难点
量化策略(event driven)是一种普遍的编码实体模型,其一般会有一个主循环系统(mainloop)持续的从序列中接受事情,随后分发送给相对应的涵数/控制模块解决。普遍应用量化策略实体模型的手机软件包含图形界面设计(GUI),内嵌式机器设备手机软件,互联网服务器端等。
文中以一个高宽比简单化的内嵌式解决控制模块作为量化策略编码的事例:假定该控制模块必须解决客户指令、外界信息、报警等各种各样事情,并在主循环系统中开展派发,那麼实例编码以下:
#include <iostream> #include <vector> enum class EventType { COMMAND, MESSAGE, ALARM }; // 仅用以仿真模拟接受的事情编码序列 std::vector<EventType> g_events{EventType::MESSAGE, EventType::COMMAND, EventType::MESSAGE}; void ProcessCmd() { std::cout << "Processing Command" << std::endl; } void ProcessMsg() { std::cout << "Processing Message" << std::endl; } void ProcessAlm() { std::cout << "Processing Alarm" << std::endl; } int main() { for (auto event : g_events) { switch (event) { case EventType::COMMAND: ProcessCmd(); break; case EventType::MESSAGE: ProcessMsg(); break; case EventType::ALARM: ProcessAlm(); break; } } return 0; }
这仅仅一个简约的实体模型实例,真正的编码要远比它繁杂得多,很有可能还会继续包括:从特殊插口获得事情,分析不一样的事情种类,应用表驱动器方式 开展派发……但是这种和文中没有太大的关系,可临时先忽视。
用顺序图表明这一实体模型,大致是那样:

在具体新项目中,经常遇到的一个难题是:有一些事情的解决時间较长,例如某一指令很有可能必须大批量的开展上一千次硬件配置实际操作:
void ProcessCmd() { for (int i{0}; i < 1000; i) { // 实际操作硬件配置插口…… } }
这类事故处理涵数会生长時间的堵塞主循环系统,造成别的事情一直排长队等候。假如全部事情对响应时间也没有规定,那也不会导致难题。可是具体情景中常常会有一些事情是必须立即回应的,例如一些报警事情发生后,必须迅速的实行业务流程调换,不然便会给客户导致损害。这个时候,解决時间较长的事情便会造成难题。
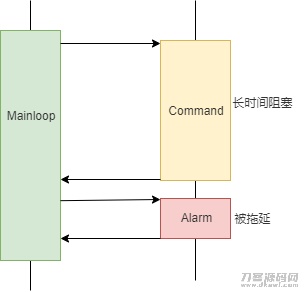
有些人会想起附加提升一个进程专用型于解决高优先事情,实践活动中这的确是个常见方式 。殊不知在嵌入式操作系统中,事故处理涵数会读写能力许多公共性算法设计,还会继续实际操作硬件配置插口,假如高并发启用,很容易造成各种数据信息市场竞争和硬件配置实际操作矛盾,并且这种难题经常难以精准定位和处理。那在线程同步的基本上上锁呢?——设计方案什么锁,加在什么地方,也是十分非常烧脑并且非常容易打错的工作中,假如相互独立等候太多,还会继续危害特性,乃至发生死锁等不便的难题。
另一种解决方法是:把解决時间较长的每日任务切成许多个日常任务,并重进到事件队列中。那样就不容易长期的堵塞主循环系统。这一计划方案防止了并发编程造成的各种各样头痛难题,可是却产生另一个难点:怎样把一个大步骤切成许多单独小步骤?在编号时,这必须程序猿解析函数步骤的全部前后文信息内容,设计方案算法设计独立储存,并创建关系这种算法设计的独特事情。这通常会产生好几倍的附加编码量和劳动量。
这个问题基本上在全部量化策略型手机软件上都会存有,但在嵌入式开发中尤其突显。这是由于内嵌式自然环境下的CPU、进程等資源受到限制,而实用性规定高,并发编程受到限制。
C 20语言表达给这个问题给予了一种新的解决方法:协同程序。
C 20的协同程序介绍
有关协同程序(coroutine)是啥,在wikipedia[1]等材料中有非常好的详细介绍,文中也不过多阐释了。在C 20中,协同程序的关键词仅仅语法糖:c语言编译器会将涵数实行的前后文(包含静态变量等)装包成一个目标,并让未实行完的涵数先回到给入参。以后,入参应用这一目标,能够 让涵数从原先的“中断点”处再次向下实行。
应用协同程序,编号时就不会再必须劳神费劲的去把涵数“激光切割”成好几个日常任务,仅用依照习惯性的步骤写涵数內部编码,并在容许临时终断实行的地区再加上co_yield句子,c语言编译器就可以将该涵数解决为可“按段实行”。
协同程序用起來的觉得有些像进程转换,由于涵数的栈帧(stack frame)被c语言编译器储存变成目标,能够 随时随地修复出去然后向下运作。可是具体实行时,协同程序实际上或是并行处理次序运作的,并沒有物理学进程转换,一切都仅仅c语言编译器的“法术”。因此 用协同程序能够 避免线程同步转换的特性花销及其資源占有,也不必担心数据信息市场竞争等难题。
遗憾的是,C 20规范只给予了协同程序基本体制,仍未给予真真正正好用的协同程序库(在C 23中很有可能会改进)。现阶段要用协同程序写具体业务流程得话,能够 依靠开源系统库,例如知名的cppcoro[2]。殊不知针对文中上述的情景,cppcoro都没有立即给予相匹配的专用工具(generator历经适度的包裝能够 处理这个问题,可是不太形象化),因而自己写了一个激光切割每日任务的协同程序java工具用以实例。
自定的协同程序专用工具
下边就是我写的SegmentedTaskjava工具的编码。这一段编码看上去非常繁杂,可是它做为可器重的专用工具存有,沒有必需让程序猿都了解它的內部完成,一般只需了解它如何使用就可以了。SegmentedTask的应用非常容易:它仅有3个对外开放插口:Resume、IsFinished和GetReturnValue,其作用可依据插口名称自表述。
#include <optional> #include <coroutine> template<typename T> class SegmentedTask { public: struct promise_type { SegmentedTask<T> get_return_object() { return SegmentedTask{Handle::from_promise(*this)}; } static std::suspend_never initial_suspend() noexcept { return {}; } static std::suspend_always final_suspend() noexcept { return {}; } std::suspend_always yield_value(std::nullopt_t) noexcept { return {}; } std::suspend_never return_value(T value) noexcept { returnValue = value; return {}; } static void unhandled_exception() { throw; } std::optional<T> returnValue; }; using Handle = std::coroutine_handle<promise_type>; explicit SegmentedTask(const Handle coroutine) : coroutine{coroutine} {} ~SegmentedTask() { if (coroutine) { coroutine.destroy(); } } SegmentedTask(const SegmentedTask&) = delete; SegmentedTask& operator=(const SegmentedTask&) = delete; SegmentedTask(SegmentedTask&& other) noexcept : coroutine(other.coroutine) { other.coroutine = {}; } SegmentedTask& operator=(SegmentedTask&& other) noexcept { if (this != &other) { if (coroutine) { coroutine.destroy(); } coroutine = other.coroutine; other.coroutine = {}; } return *this; } void Resume() const { coroutine.resume(); } bool IsFinished() const { return coroutine.promise().returnValue.has_value(); } T GetReturnValue() const { return coroutine.promise().returnValue.value(); } private: Handle coroutine; };
自身撰写协同程序的java工具不仅必须深入了解C 协同程序体制,并且非常容易造成悬在空中引入等未定义个人行为。因而强烈要求团队统一应用撰写好的协同程序类。假如阅读者想加强学习协同程序专用工具的撰写方式 ,能够 参照Rainer Grimm的网络文章[3]。
下面,大家应用SegmentedTask来更新改造前边的事故处理编码。当一个C 涵数中应用了co_await、co_yield、co_return中的一切一个关键词时,这一涵数就变成了协同程序,其传参也会变为相匹配的协同程序java工具。在实例编码中,必须里层涵数提早回到时,应用的是co_yield。可是C 20的co_yield后务必追随一个关系式,这一关系式在实例情景下并没必要,就用了std::nullopt让其能编译程序根据。具体业务流程自然环境下,co_yield能够 回到一个数据或是目标用以表明当前任务实行的进展,便捷表层查看。
协同程序不可以应用一般return句子,务必应用co_return来传参,并且其回到种类都不立即相当于co_return后边的关系式种类。
enum class EventType { COMMAND, MESSAGE, ALARM }; std::vector<EventType> g_events{EventType::COMMAND, EventType::ALARM}; std::optional<SegmentedTask<int>> suspended; // 沒有实行完的每日任务储存在这儿 SegmentedTask<int> ProcessCmd() { for (int i{0}; i < 10; i) { std::cout << "Processing step " << i << std::endl; co_yield std::nullopt; } co_return 0; } void ProcessMsg() { std::cout << "Processing Message" << std::endl; } void ProcessAlm() { std::cout << "Processing Alarm" << std::endl; } int main() { for (auto event : g_events) { switch (event) { case EventType::COMMAND: suspended = ProcessCmd(); break; case EventType::MESSAGE: ProcessMsg(); break; case EventType::ALARM: ProcessAlm(); break; } } while (suspended.has_value() && !suspended->IsFinished()) { suspended->Resume(); } if (suspended.has_value()) { std::cout << "Final return: " << suspended->GetReturnValue() << endl; } return 0; }
出自于让实例简易的目地,事件队列中只放进了一个COMMAND和一个ALARM,COMMAND是能够 按段实行的协同程序,实行完第一段后,主循环系统会优先选择实行序列中剩余的事情,最终再说执行COMMAND剩下的一部分。具体情景下,可依据必须灵便挑选各种各样生产调度对策,例如专业用一个序列储放全部未实行完的按段每日任务,并在空余时先后实行。
文中中的编码应用gcc 10.3版本号编译程序运作,编译程序时必须另外再加上-std=c 20和-fcoroutines2个主要参数才可以适用协同程序。程序执行結果以下:
Processing step 0 Processing Alarm Processing step 1 Processing step 2 Processing step 3 Processing step 4 Processing step 5 Processing step 6 Processing step 7 Processing step 8 Processing step 9 Final return: 0
能够 见到ProcessCmd涵数(协同程序)的for循环句子并沒有一次实行完,在中间插入了ProcessAlm的实行。假如剖析运作进程还会继续发觉,全部全过程中并沒有物理学进程的转换,全部编码全是在同一个进程上次序实行的。
应用了协同程序的顺序图变成了那样:
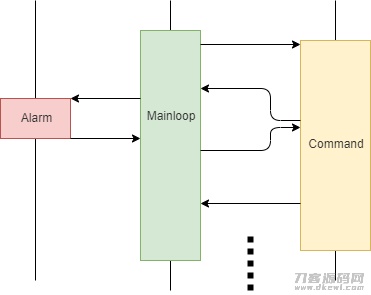
事故处理涵数的实行时间长不会再是难题,由于能够 半途“插进”别的的涵数运作,以后再回到中断点再次往下运作。
汇总
一个较广泛的了解错误观念是:应用线程同步能够 提高手机软件特性。但实际上,只需CPU沒有空跑,那麼当物理学线程数超出了CPU核数,就不会再会提高特性,反过来还会继续因为进程的转换花销而减少特性。大部分开发设计实践活动中,并发编程的关键益处并不是为了更好地提高特性,只是为了更好地编号的便捷,由于实际中的场景模型许多全是高并发的,非常容易立即相匹配成线程同步编码。
协同程序能够 像线程同步那般便捷形象化的编号,可是另外又沒有物理学进程的花销,更沒有相互独立、同歩等并发编程中让人头疼的设计方案压力,在嵌入式开发等许多情景下,经常是比物理学进程更强的挑选。
坚信伴随着C 20的逐渐普及化,协同程序未来会获得愈来愈普遍的应用。
尾注
[1] https://en.wikipedia.org/wiki/Coroutine
[2] https://GitHub.com/lewissbaker/cppcoro
[3] https://www.modernescpp.com/index.php/tag/coroutines
加关注,第一时间掌握华为云服务新鮮技术性~
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0