摘要
MySQL索引,就像字典的部首和笔画,能快速找到匹配的数据,让数据库查询更高效。
正文
浅入浅出 MySQL 数据库索引
简易掌握数据库索引
最先,数据库索引(Index)是啥?假如立即对你说数据库索引是数据库查询智能管理系统中的一个井然有序的算法设计,你很有可能会有点儿懵圈。

为了更好地防止这类状况,我准备举好多个事例来协助你更非常容易的了解数据库索引。
大家查看词典的情况下能够 依据字的部首、字的笔画来搜索到相匹配的字,那样能够 迅速的寻找相匹配的字所属页,在词典开始那玩意就叫数据库索引
也有一本书的文件目录,能够 帮大家迅速的跳至不一样的章节目录,这时这儿的文件目录也是数据库索引
乃至,旅游景区的地形图,会对你说你现在做什么,别的旅游景点在哪里,这个地图从一些层面而言也是数据库索引
再融合开场较技术专业的表述,你很有可能就可以了解索引是什么了。

为何必须数据库索引
了解了数据库索引的定义,大家就必须了解为何大家必须数据库索引?从刚的事例能看出去,数据库索引的存有的目地便是:

-
词典中的数据库索引协助大家迅速的寻找相匹配的字
-
书的文件目录协助大家迅速的跳至大家必须看的章节目录
-
旅游景区的地形图协助大家迅速的寻找要想去的旅游景区的路
在数据库查询中,数据库索引能够 协助大家迅速的查看到相匹配的数据信息行,进而顺利的取下全部列的数据信息。这一全过程务必要快,针对如今的 Web 运用而言,DB 假如回应慢,可能立即危害到全部要求的响应速度,而这对客户体验而言是毁灭性的。
针对点个按键,等个好几秒才有回到,那麼以后客户大概率是不容易再应用你开发设计的运用了。
MySQL中的数据库索引
最先,MySQL 和数据库索引实际上沒有立即的关联。数据库索引实际上是 MySQL 中应用的储存模块 InnoDB 中的定义。在 InnoDB 中,数据库索引分成:
-
聚簇索引 -
非聚簇索引
针对聚簇索引,是 InnoDB 依据外键约束(Primary Key)搭建的数据库索引。你能临时了解为 key 为主导键,value 则是整行数据信息。而且一张表只有有一个聚簇索引。

自然,你能不界定外键约束。可是一切正常状况下大家都是会建立一个单调递增的外键约束,或是是根据统一的 ID 转化成优化算法转化成。要是没有界定一切外键约束,InnoDB 会出现自身的兜底对策。InnoDB 会挑选大家界定的第一个全部值的都不以空的唯一索引做为聚簇索引。

但是具体的工作环境中,确实会出现那样的 Corner Case。InnoDB 还有一个究极兜底,假如连仅存的唯一索引都不符合规定,InnoDB 会自身建立一个掩藏的6个字节数的外键约束 RowID,随后依据这一掩藏的外键约束来转化成聚簇索引。
而针对非聚簇索引,是依据特定的列建立的数据库索引,也叫二级数据库索引(Secondary Index),一张表数最多能够 建立64个二级数据库索引。key 为建立二级数据库索引的列的值,value 为主导键。也就是说,假如根据非聚簇索引查看,最后只有获得数据库索引列自身的值 外键约束的值,假如要想获得到详细的列数据信息,还必须依据获得的外键约束去聚簇索引中再查看一次,这一全过程叫回表。
这儿表明一下,现在有许多的blog说,MySQL 应用 InnoDB 时,一张表数最多只有建立 16 个数据库索引,最先它是错的,显著是以别的的地区立即抄过来的,自身沒有去做一切的认证。
在 MySQL 的官方网文章内容中,确立的表明了,一张表数最多能够 建立 64 个非聚簇索引,并且建立非聚簇索引时,列的总数不可以超出16个。
留意,是建立非聚簇索引的列不可以超出16个!

这也顺带提一下题外话,说白了的技术性认真细致,什么是认真细致?对你根据别的方式获得到的专业知识,它数最多叫创作者的见解,大家持一种猜疑心态,并想办法自身去证实。证实后,它才会变为客观事实。
而不是对一些专有名词死记硬背的,如今的新东西五花八门,但如果你溯其根本原因,你能发觉就那回事。
数据库索引最底层基本原理
前边提及了 InnoDB 中数据库索引的种类,简易的了解了其分类和区别,那 InnoDB 中的数据库索引是怎样保证加快查看的呢?其最底层的基本原理是啥呢?InnoDB 中的数据库索引的最底层构造为 B 树,是B树的一个变异。

先给大伙儿看一下B 树究竟涨个什么鸟样,下面的图是一颗储存了数据「1-7」的B 树。
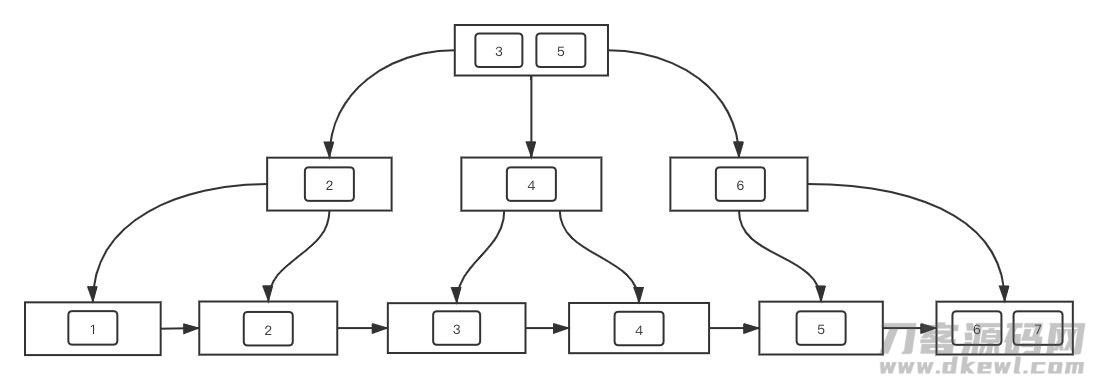
能够 见到,B 树中,每一个连接点能够 有好几个子连接点,而像大家平时了解的二叉树中,每一个连接点数最多只有有两个。而且,B 树中,连接点的储存数据信息是井然有序的,而井然有序的数据信息构造就可以使我们开展迅速的精准配对和范畴查看。并且B 树中的叶子结点中间有偏向下一个连接点的表针,而B树中的叶子节点是沒有的。
在 MySQL InnoDB 的具体完成中,页连接点中间实际上是个双链表,储存了各自偏向上一个、下一个连接点的表针
下面的图是包括了整数金额「1-7」的B树,这一图应当会协助你加重对二者差别的了解。
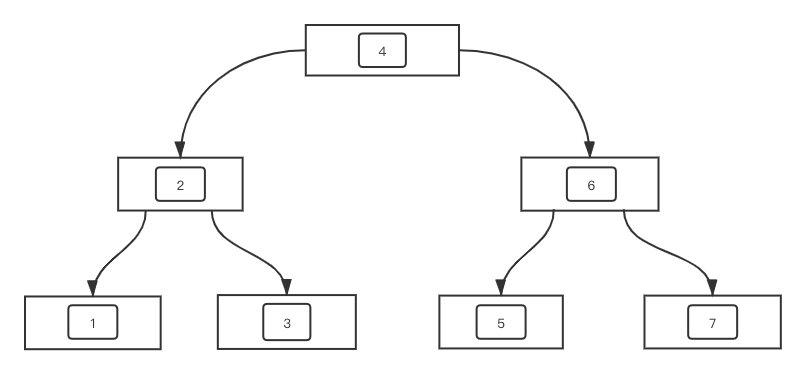
而且,在B 树中,除开叶子节点储存了真正的数据信息以外,其他的连接点都只储存了偏向下一连接点的表针。也就是说,数据信息所有都是在叶子节点上。而在B树中,全部的连接点都能够储存数据信息,这是一个最关键的差别。
知道B树和B 树的基本构造长啥样以后,大家必须再深入了解 InnoDB 是怎样运用B 树来储存数据信息的。最先,MySQL 并不会把数据储存在运行内存中,运行内存仅仅做为运作时的一种提升,有关 InnoDB 运行内存构架有关的物品,以前早已写了一篇文章,有兴趣的能够 先看一看。
InnoDB 会将数据储存在硬盘上,而在我们查看数据信息的情况下,OS 会将储存在硬盘上的数据信息一页一页的载入到运行内存里。这儿的页是 OS 管理方法运行内存的一种方法,当其载入数据信息到运行内存时,会将某一硬盘块上的数据信息依照页的尺寸载入。在这儿,你能了解为B树中每一个连接点便是一个硬盘块。
那即然B树和B 树在搜索的情况下都必须开展 I/O 实际操作将必须的连接点载入到运行内存,B 树相对性于B树的优点究竟在哪里?

本人觉得关键有三点。
一是B 树可以降低 I/O 的频次。为啥呢?凭啥算法设计长的类似,B 树就可以降低 I/O 的频次?以前说到,单独连接点就意味着了一个硬盘块,而单独硬盘块的尺寸是固定不动的。B 树仅有叶子结点才储存值,相对性于全部连接点都存详细数据信息的B树来讲,B 树中单独硬盘块可以容下大量的数据信息。

单独硬盘块,容积固定不动的前提条件下,储存的原素尺寸越小,则可以储存的原素的总数便会大量。也就是说,一次 I/O 可以把大量的数据加载进运行内存,而这种多载入的原素很可能就是你会采用的,而这就一定水平可以降低 I/O 的频次。
此外,单独连接点可以储存的原素增加了,还可以具有降低树的高宽比的功效。
二是查看高效率更为平稳。什么是更平稳呢?那么就在信息量同样的状况下,不容易由于你查看的数据信息 ID 不一样而导致查看所消耗時间截然不同,也就是说,此次要求很有可能花了十米s,下一次一样的要求啪的一下花了50ms,这就要人很不可以接纳,合着插口的特性也要看着你数据库查询的情绪?
那为什么说应用B 树就可以保证查看高效率平稳呢?由于B 树非叶子结点不容易储存数据信息,因此 假如要获得到最后的数据信息,必定会查出叶子结点,也就是说,每一次查看的 I/O 频次是同样的。而B树因为全部节点均可储存数据信息,有的数据信息很有可能1次 I/O 就查看到,而有的则必须查看到叶子结点才寻找数据信息,而这就会产生查看高效率的不稳定。
三是可以更强的适用范畴查看。那B树为什么就不可以非常好的适用呢?使我们返回B树这幅图。
假定大家必须查看 [3, 5] 这一区段内的数据信息,会历经什么?不空话,立即把图给出去。
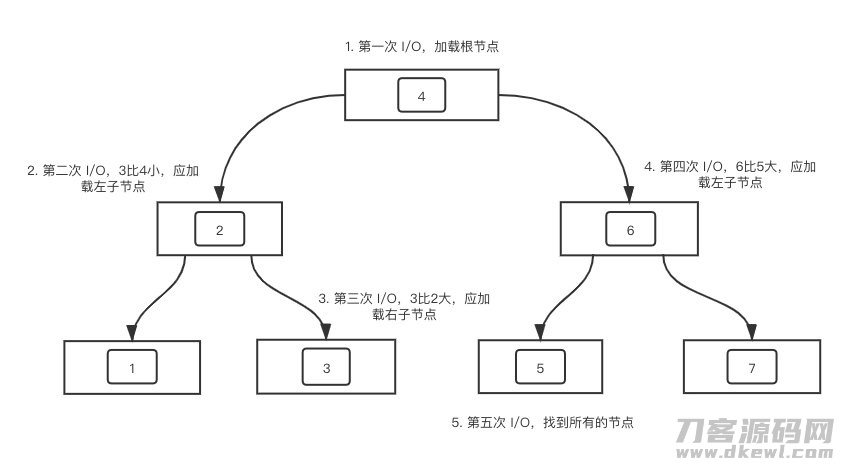
能够 见到,假如到叶子结点依然沒有查看到详细的数据信息,会再次回到到根结点再度开展解析xml。而回过头看 B 树,当找到叶子结点以后就可以根据叶子结点中间的表针立即开展链表解析xml,能够 极大地提高范畴查看的高效率。
知道这一点以后,举一反三就可以了解,为何 InnoDB 不应用 Hash 在做最底层的算法设计了。即便查看时 Hash 的算法复杂度乃至能保证 O(1)
最终聊一聊 I/O
全文提及了很数次 I/O,及其在 MySQL 的数据库索引设计方案中,必须尽可能的降低 I/O 频次,为啥呢?是由于 I/O 很价格昂贵。在我们实行一次 I/O,究竟发生什么事?
原本像详尽讲下硬盘构造的,可是看过一眼篇数,早已快超了,因此 这儿就简易的聊一聊就行
固态硬盘中,一次 I/O 实际操作,由三个流程构成:
最先必须寻道,寻道就是指硬盘的磁带机挪动道硬盘上的磁盘上边,这一時间一般在3-15ms内。
随后是转动,硬盘会将储存相匹配数据信息的盘体转动至磁带机下边,这又用掉1ms上下,实际的延迟与硬盘的转速比相关。
最终是传输数据。
一波实际操作出来,耗费就在十米s上下。不必认为十米s还行…比照于SSD(固态盘)和运行内存的分秒、纳秒而言,真是拥有 天差地别。

这也是为什么在 MySQL 中,任意 I/O 对其查看的特性危害非常大的缘故。
好啦之上便是这篇blog的所有内容了,热烈欢迎搜索微信关心【SH的全栈开发手记】,回应【序列】获得MQ学习材料,包括基本定义分析和RocketMQ详尽的源代码分析,不断升级中。
如果你觉得本文对您有协助,还不便点个赞,关个注,分出享,留个言。

关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0