摘要
Pandas是数据分析的得力助手,它是基于NumPy的专用工具。它集成了许多库和规范的数据库系统,为处理大型数据提供了高效的工具。Pandas提供了许多方便快捷的方法来解决数据问题,本章将通过案例详细介绍Pandas的使用。
正文
Python 初级教程 —— Pandas 库常见方式案例表明
 pandas 是根据NumPy 的一种专用工具,该专用工具是为处理数据统计分析每日任务而建立的。Pandas 列入了很多库和一些规范的数据库系统,给予了高效率地实际操作大中型数据需要的专用工具。pandas给予了很多能使大家迅速方便快捷地解决数据信息的涵数和方式。此章将以案例方法详细介绍 panads 库的一些常见方式MultiIndex、 loc、iloc等,还会继续解读DataFrame的插进 insert、排列 sort、连接 merge、统计分析describe 、排序 groupby 等方式,期待对大伙儿的开发设计有一定的协助。
pandas 是根据NumPy 的一种专用工具,该专用工具是为处理数据统计分析每日任务而建立的。Pandas 列入了很多库和一些规范的数据库系统,给予了高效率地实际操作大中型数据需要的专用工具。pandas给予了很多能使大家迅速方便快捷地解决数据信息的涵数和方式。此章将以案例方法详细介绍 panads 库的一些常见方式MultiIndex、 loc、iloc等,还会继续解读DataFrame的插进 insert、排列 sort、连接 merge、统计分析describe 、排序 groupby 等方式,期待对大伙儿的开发设计有一定的协助。
文件目录
1. 常见方式 pandas.Series
2. pandas.DataFrame ([data],[index]) 依据行创建数据信息
3. pandas.DataFrame ({dic}) 依据列创建数据信息
4. pandas.DataFrame([list])依据数据信息创建列数据信息
5. loc / iloc 数据筛选
6. 多级别行数据库索引
7. 应用 pandas.MultiIndex 显式建立多级别行数据库索引
8. 多级别行数据库索引的升维及特征提取
9. 在DataFrame 中加上列 insert
10. 排列 sort
11. 依据多级别数据库索引开展数据分析
12. 简单合拼 pandas.concat
13. pandas.merge 合拼与连接
14. 列统计函数 describe
15. groupby 排序计算
16. pivot_table 数据透视
1. pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False )
data:适用多种多样基本数据类型
index:可选主要参数,数据信息数据库索引,若为空则是由0逐渐的整数金额排列,数据库索引明确后只有查询不可以改动
dtype: 基本数据类型,能为空
name: 字段名,能为空
1 # index 为空时,默认设置由0逐渐排列顺序 2 list=pd.Series(['a','b','c']) 3 print(list) 4 -------------------------------------------------------- 5 out: 6 1 a 7 2 b 8 3 c 9 ======================================================= 10 11 #应用 index 键入 12 list=pd.Series(['Leslie','Jack','Mike'],[2,1,3]) 13 print(list) 14 -------------------------------------------------------- 15 out: 16 2 Leslie 17 1 Jack 18 3 Mike 19 ======================================================== 20 21 # 以dic字典键入数据信息 22 list=pd.Series({2:'Leslie',1:'Jack',3:'Mike'}) 23 print(list) 24 -------------------------------------------------------- 25 out: 26 2 Leslie 27 1 Jack 28 3 Mike 29 ======================================================== 30 31 #表明挑选結果 32 list=pd.Series({2:'Leslie',1:'Jack',3:'Mike'},[2,3]) 33 print(list) 34 -------------------------------------------------------- 35 out: 36 2 Leslie 37 3 Mike 38 ========================================================= 39 40 #特定字段名name 41 price=pd.Series(['68','90'],name='price',index=['JAVA IN ACTION','Python Data Science Handbook']) 42 print(price) 43 -------------------------------------------------------- 44 out: 45 JAVA IN ACTION 68 46 Python Data Science Handbook 90 47 Name: price, dtype: object
留意:字段名默认设置以0逐渐的整数金额
返回文件目录
2. pandas.DataFrame ([data],[index]) 依据行创建数据信息
DataFrame可当作panads的行数据库索引,最基本是根据单独现有的series目标建立DataFrame
data: 被panads实例化的行数据
index:行数据库索引结合,为空时将由0逐渐按整数金额排序
1 java=pd.Series({'price':68,'count':1}) 2 python=pd.Series({'price':90,'count':1}) 3 frame=pd.DataFrame(data=[java,python],index=['JAVA IN ACTION','Python Data Science Handbook']) 4 print(frame)
輸出

留意:data, index 主要参数务必是结合,不然会出错
返回文件目录
3. pandas.DataFrame ({dic}) 依据列创建数据信息
可根据此方式运用词典创建列数据信息
1 #每这书的价钱列 2 price=pd.Series({'JAVA IN ACTION':68,'Python Data Science Handbook':90}) 3 #每这书的数据信息列 4 count=pd.Series({'JAVA IN ACTION':1,'Python Data Science Handbook':1}) 5 #应用词典创建DataFrame 6 frame=pd.DataFrame({'price':price,'count':count}) 7 print(frame)
結果与上边一样,系统软件会依据行数据库索引关联数据信息
返回文件目录
4. pandas.DataFrame([list])依据数据信息创建列数据信息
留意:应用 list 与 dic 较大 不一样在 dic 在调用以转化成列时先根据 index 特定行数据库索引
1 price1=pd.Series(['68','90'],name='price1',index=['JAVA IN ACTION','Python Data Science Handbook']) 2 count1=pd.Series(['1','1'],name='count1',index=['JAVA IN ACTION','Python Data Science Handbook']) 3 frame1=pd.DataFrame([price1,count1]) 4 print(frame1)
比照上边事例,当以二维数组创建 DataFrame 时,二维数组内的数据信息默认设置为行数据信息

返回文件目录
5. loc 、iloc数据筛选
data=pandas.Series([‘Leslie’,‘Rose’,’Jack’,’Mike’])
显式数据库索引即 data[ ‘Leslie’ : ‘Jack’] 作切成片时,結果包括最后一个数据库索引即 Jack
隐式数据库索引即 data[ 0 : 2 ]作切成片时,結果不包含最后一个
为了更好地防止搞混,提议应用 loc(显式)、iloc(隐式)
data[ ‘Leslie’ : ‘Jack’] 等效于 data.loc[ ‘Leslie’ : ‘Jack’]
data[ 0 : 2 ]等效于data.iloc[ 0 : 2 ]
另外,loc 也可做为数据信息的挑选标准
1 age=pd.Series({'Leslie':28,'Jack':32,'Rose':18}) 2 address=pd.Series({'Jack':'Beijing','Rose':'Shanghai','Leslie':'Guangzhou'}) 3 person=pd.DataFrame({'address':address,'age':age}) 4 print(person.loc[person['age']<30])
表明結果

多条件筛选
1 age=pd.Series({'Leslie':28,'Jack':32,'Rose':18}) 2 address=pd.Series({'Jack':'Beijing','Rose':'Shanghai','Leslie':'Guangzhou'}) 3 person=pd.DataFrame({'address':address,'age':age}) 4 print(person.loc[(person['age']<30) & (person['age']>20)])
![]()
返回文件目录
6. 多级别行数据库索引
将 index 行数据库索引分为多维等级
1 test=pd.DataFrame(data=np.random.rand(4,2), 2 index=[['index0','index0','index1','index1'],[0,1,0,1]], 3 columns=['column0','column1']) 4 print(test)
結果
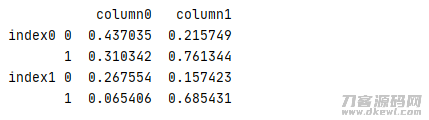
能为多级别行数据库索引创建名字,非常容易管理方法
1 test1=pd.DataFrame(data=np.random.rand(4,2), 2 index=[['index0','index0','index1','index1'],[0,1,0,1]], 3 columns=['column0','column1']) 4 test1.index.names=['indexName0','indexName1'] 5 print(test1)
結果
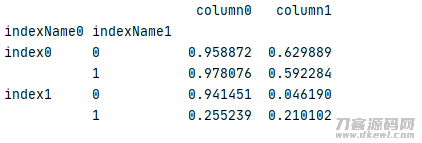
返回文件目录
7. 应用 pandas.MultiIndex 显式建立多级别行数据库索引
应用数组方法 MultiIndex.from_arrays ()
1 data=[['Python Learning from Scratch','1','68'],['Pro Apahe Hadoop','1','105'],['Python Crash Course','2','89'] 2 ,['Beginning Python From Novice','1','76'],['Python Appclications','2','120'],['Deep Learning with TensorFlow','1','58']] 3 index=pd.MultiIndex.from_arrays([['Leslie','Leslie','Jack','Jack','Mike','Mike'],[2020,2021,2020,2021,2020,2021]]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column)
应用数据库索引值的元组方式 MultiIndex.from_tuples()
1 data=[['Python Learning from Scratch','1','68'],['Pro Apahe Hadoop','1','105'],['Python Crash Course','2','89'] 2 ,['Beginning Python From Novice','1','76'],['Python Appclications','2','120'],['Deep Learning with TensorFlow','1','58']] 3 index=pd.MultiIndex.from_tuples([('Leslie',2020),('Leslie',2021),('Jack',2020),('Jack',2021),('Mike',2020),('Mike',2021)]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column)
应用笛爱朵积方式 MultiIndex.from_product ()
1 data=[['Python Learning from Scratch','1','68'],['Pro Apahe Hadoop','1','105'],['Python Crash Course','2','89'] 2 ,['Beginning Python From Novice','1','76'],['Python Appclications','2','120'],['Deep Learning with TensorFlow','1','58']] 3 index=pd.MultiIndex.from_product([['Leslie','Jack','Mike'],[2020,2021]]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column)
上边3种方式可获得同样結果,3种方式有不一样的应用情景

返回文件目录
8. 多级别行数据库索引的升维及特征提取
再次以上边事例为例子,应用 stack(level) 能够把 DataFrame 升维,应用 unstack(level) 很有可能把 DataFrame 特征提取
留意:数据信息升维特征提取后都将回到一个数据的团本,改动其值不容易危害原数据信息
1 data=[['Python Learning from Scratch',1,68],['Pro Apahe Hadoop',1,105],['Python Crash Course',2,89] 2 ,['Beginning Python From Novice',1,76],['Python Appclications',2,120],['Deep Learning with TensorFlow',1,58]] 3 index=pd.MultiIndex.from_tuples([('Leslie',2020),('Leslie',2021),('Jack',2020),('Jack',2021),('Mike',2020),('Mike',2021)]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column) 6 //测算整体价钱 7 total=book['Price']*book['Count'] 8 print(str(total) '\n') 9 //特征提取表明,把二维的行数据库索引转换为列 10 print(total.unstack())
結果

应用 level 主要参数能够设定特征提取的等级,level 为 0 即把多维行的第一层面开展变换 ( 即name主要参数 ),level 为 1 即把多维行的第二层面开展变换 ( 即 year 主要参数 )
1 data=[['Python Learning from Scratch',1,68],['Pro Apahe Hadoop',1,105],['Python Crash Course',2,89] 2 ,['Beginning Python From Novice',1,76],['Python Appclications',2,120],['Deep Learning with TensorFlow',1,58]] 3 index=pd.MultiIndex.from_tuples([('Leslie',2020),('Leslie',2021),('Jack',2020),('Jack',2021),('Mike',2020),('Mike',2021)]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column) 6 //测算总价格 7 total=book['Price']*book['Count'] 8 //把第一维name开展特征提取 9 print(total.unstack(level=0))
由此可见結果恰好与上边的事例反过来,若把level设定为1,则結果跟上边同样

应用 stack 把数据信息开展升维,level 应用与 unstack 相近
1 data=[['Python Learning from Scratch',1,68],['Pro Apahe Hadoop',1,105],['Python Crash Course',2,89] 2 ,['Beginning Python From Novice',1,76],['Python Appclications',2,120],['Deep Learning with TensorFlow',1,58]] 3 index=pd.MultiIndex.from_tuples([('Leslie',2020),('Leslie',2021),('Jack',2020),('Jack',2021),('Mike',2020),('Mike',2021)]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column) 6 print(book.stack())
結果
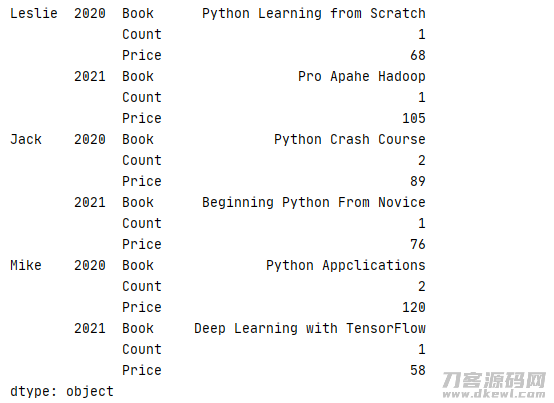
数据库索引重设的此外2个常见方式 reset_index() 与 set_index()
reset_index(self,level, drop: bool = False, inplace: bool = False, col_level: Hashable = 0, col_fill: Label = “”) 把行标识转化成列
level:默认设置为 None,从数据库索引中删掉给出的等级,默认设置状况下删掉全部等级。
drop: 默认设置为 False 不必试着将数据库索引插进 DataFrame 列,这会将数据库索引重设为默认设置的整数金额数据库索引。
inplace:bool, 默认设置为 False,改动DataFrame及时(不必建立新目标)。
col_level:int 或 str, 默认设置为 0,假如列有好几个等级,请明确将标识插进到哪一个等级。默认设置状况下,它被插进到第一级。
col_fill:object, 默认设置为空,假如列具备好几个等级,请明确怎样取名别的等级。假如为None,则反复数据库索引名字。
1 age=pd.Series({'Leslie':28,'Jack':32,'Rose':18}) 2 address=pd.Series({'Jack':'Beijing','Rose':'Shanghai','Leslie':'Guangzhou'}) 3 person=pd.DataFrame({'address':address,'age':age}) 4 print(str(person) "\n") 5 #把name转化成列,变换后字段名默认设置为index 6 person=person.reset_index() 7 #把字段名改成name 8 person.rename(columns={'index':'name'},inplace=True) 9 print(person)
表明結果

set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
keys:label or array-like or list of labels/arrays,这个是必须设定为数据库索引的字段名,能够是单独字段名,或是是好几个字段名
drop:bool, default True,删掉要作为新数据库索引的列
append:bool, default False,加上新数据库索引
inplace:bool, default False,是不是要遮盖数据
verify_integrity:bool, default False,查验新数据库索引是不是反复
1 age=pd.Series({'Leslie':28,'Jack':32,'Rose':18}) 2 address=pd.Series({'Jack':'Beijing','Rose':'Shanghai','Leslie':'Guangzhou'}) 3 person=pd.DataFrame({'address':address,'age':age}) 4 print(str(person) "\n") 5 #把行数据库索引name转化成列,默认设置字段名为index 6 person=person.reset_index() 7 #把字段名改成name 8 person.rename(columns={'index':'name'},inplace=True) 9 print(str(person) "\n") 10 #再次把列name变换成形数据库索引 11 person=person.set_index(['name'],append=True) 12 print(person)
运作結果

返回文件目录
9. 在DataFrame 中加上列 insert
def insert(loc, column, value, allow_duplicates=False) 能够立即组DataFrame加上列
- loc: 所加上的部位数据库索引,加上到哪一列
- column:列名字
- value: 加上的数据
1 age=pd.Series({'Leslie':28,'Jack':32,'Rose':18}) 2 address=pd.Series({'Jack':'Beijing','Rose':'Shanghai','Leslie':'Guangzhou'}) 3 person=pd.DataFrame({'address':address,'age':age}) 4 person.insert(2,'sex',[’male','male','female'])
运作結果

返回文件目录
10. 排列 sort
假如在应用 MultiIndex 并不是井然有序数据库索引,那在切成片情况下系统软件常常会报下列不正确(留意:数据信息排列后回到的将是原数据信息的一个团本,团本值改动始终不变原数据信息值)

这时可应用 sort_index() 或 sortlevel() 先向数据信息开展排列再开展切成片
1 data=[['Python Learning from Scratch',1,68],['Pro Apahe Hadoop',1,105],['Python Crash Course',2,89] 2 ,['Beginning Python From Novice',1,76],['Python Appclications',2,120],['Deep Learning with TensorFlow',1,58]] 3 index=pd.MultiIndex.from_tuples([('Leslie',2020),('Leslie',2021),('Jack',2020),('Jack',2021),('Mike',2020),('Mike',2021)]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column) 6 #先按 index 开展排列 7 book=book.sort_index() 8 print(str(book.loc['Leslie':,:]) '\n') 9 print(book.loc[('Leslie',2021):,:'Count'])
运作結果

返回文件目录
11. 依据多级别数据库索引开展数据分析
客户还能够应用 mean()、sum()、max() 等方式对多级别数据库索引开展数据分析,也可应用 level 基本参数所统计分析的层面
1 data=[['Python Learning from Scratch',1,68],['Pro Apahe Hadoop',1,105],['Python Crash Course',2,89] 2 ,['Beginning Python From Novice',1,76],['Python Appclications',2,120],['Deep Learning with TensorFlow',1,58]] 3 index=pd.MultiIndex.from_tuples([('Leslie',2020),('Leslie',2021),('Jack',2020),('Jack',2021),('Mike',2020),('Mike',2021)]) 4 column=['Book','Count','Price'] 5 book=pd.DataFrame(data=data,index=index,columns=column) 6 book=book.sort_index() 7 #原始记录 8 print(str(book) '\n') 9 #以name为层面测算每一年总价格 10 print(str(book.sum(level=0)) '\n') 11 #以year为层面设计方案平均值 12 print(str(book.mean(level=1)) '\n') 13 #以year为层面测算最高值 14 print(book.max(level=1))
运作結果,由此可见在预估均值和总价值时有关Book等不配对的字段名系统软件自动式忽视
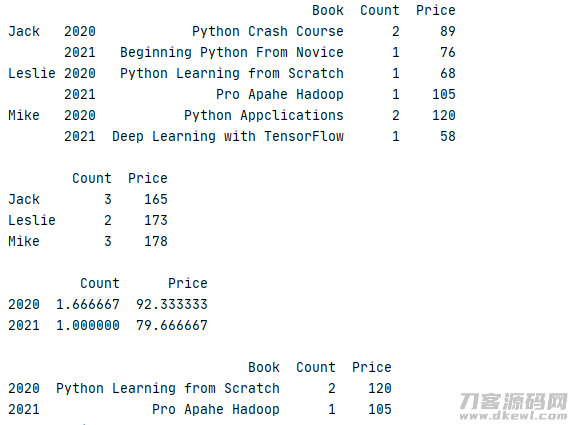
返回文件目录
12. 简单合拼 pandas.concat
pd.concat( objs: Union[Iterable[“NDFrame”], Mapping[Label, “NDFrame”]],axis=0,join=”outer”,
ignore_index: bool = False,keys=None,levels=None,names=None,
verify_integrity: bool = False,sort: bool = False,copy: bool = True,)
- objs: series,dataframe或是是panel组成的编码序列lsit
- axis: 必须合拼连接的轴,0是行,1是列
- join:联接的方法 inner,或是outer
- ignore_index: 是不是把数据库索引重设
- verify_intergrity: 捕获反复数据库索引的不正确
concat 默认设置会将所属列开展合拼,确失列默认设置为 NaN 表明,index 默认设置容许反复(若不要想反复数据库索引,能够把 ignore_index 设定为 True)
若把 verify_intergrity 设定为 True,一旦发生反复数据库索引,系统软件就抛出异常
1 data2=[['Python Learning from Scratch',68,'Eric Matthes'],['Pro Apahe Hadoop',72,'Magnus Lie'],['Python Crash Course',98,'Wes Mckinney']] 2 data3=[['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen'],['Deep Learning with TensorFlow','Md Rezaul']] 3 4 column2=['Book','Price','Author'] 5 column3=['Book','Author'] 6 7 book2=pd.DataFrame(data=data2,columns=column2).sort_index() 8 book3=pd.DataFrame(data=data3,columns=column3).sort_index() 9 10 print(pd.concat([book2,book3]))
运作結果
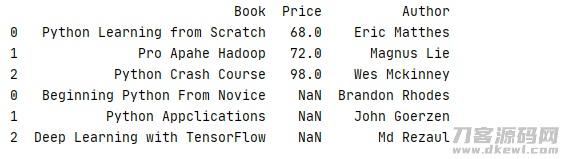
若要想除掉缺少列,能够把主要参数 join 设定为 ‘ inner ‘
1 data2=[['Python Learning from Scratch',68,'Eric Matthes'],['Pro Apahe Hadoop',72,'Magnus Lie'],['Python Crash Course',98,'Wes Mckinney']] 2 data3=[['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen'],['Deep Learning with TensorFlow','Md Rezaul']] 3 4 column2=['Book','Price','Author'] 5 column3=['Book','Author'] 6 7 book2=pd.DataFrame(data=data2,columns=column2).sort_index() 8 book3=pd.DataFrame(data=data3,columns=column3).sort_index() 9 10 print(pd.concat([book2,book3],join='inner'))
运作結果

返回文件目录
13. merge 合拼与联接
pandas.merge (left, right, how: str = “inner”, on=None, left_on=None, right_on=None,
left_index: bool = False, right_index: bool = False, sort: bool = False,
suffixes=(“_x”, “_y”), copy: bool = True, indicator: bool = False, validate=None)
- left: 结合数据信息
- right: 结合数据信息
- how: 接口方式,默认设置为 inner 内连接,还能够是 outer 外连接, left 左连接, right 右连接
- on:连接标准,若是为空时,默认设置为left/right 的相交做为连接标准
- left_on: 特定连接标准的字段名
- right_on: 特定连接标准的字段名
- left_index: 是不是用数据库索引为连接标准
- right_index: 是不是用数据库索引为连接标准
- sort: 是不是排列
- suffixes: 当发生反复字段名时可再加上后缀名
- copy:默认设置是True, 合拼数据信息为拷贝数据信息
- indicator:
- validate: 相匹配方法 (一对一为 1:1) ( 一对多为1:m )(多对一为m:1) (多对多见m:m )
merge 是最常见的合拼联接,使用方法与SQL数据库查询中的操作方法极其类似,适用一对一,一对多,多对多方法
在缺少值时,merge也会用 NaN 替代,与 concat 不一样的是 merge 默认设置会自动生成新的数据库索引
方式可根据on主要参数与配备关系列,若是为空时,则默认设置为 left / right 的相交做为连接标准,此类中即是 Book 列
1 _book=[['Python Learning from Scratch','Eric Matthes'],['Pro Apahe Hadoop','Magnus Lie'],['Python Crash Course','Wes Mckinney'], 2 ['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen'],['Deep Learning with TensorFlow','Md Rezaul']] 3 column1=['Book','Author'] 4 book=pd.DataFrame(data=_book,columns=column1) 5 6 _price=[['Python Learning from Scratch',68,2],['Pro Apahe Hadoop',105,3],['Python Crash Course',89,1] 7 ,['Beginning Python From Novice',76,2],['Python Appclications',120],['Deep Learning with TensorFlow',58,3]] 8 9 column2=['Book','Price','Count'] 10 price=pd.DataFrame(data=_price,columns=column2) 11 12 print(pd.merge(book,price,on='Book'))
运作結果,index=4 的书籍沒有设置 Count 时,系统软件默认设置为 NaN

当关系列的名字不另外,可根据 left_on 和 right_on 分离特定字段名
1 _book=[['Python Learning from Scratch','Eric Matthes'],['Pro Apahe Hadoop','Magnus Lie'],['Python Crash Course','Wes Mckinney'], 2 ['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen'],['Deep Learning with TensorFlow','Md Rezaul']] 3 column1=['Name','Author'] 4 book=pd.DataFrame(data=_book,columns=column1) 5 6 _price=[['Python Learning from Scratch',68,2],['Pro Apahe Hadoop',105,3],['Python Crash Course',89,1] 7 ,['Beginning Python From Novice',76,2],['Python Appclications',120],['Deep Learning with TensorFlow',58,3]] 8 price=pd.DataFrame(data=_price,columns=column2) 9 10 pd.set_option('display.max_columns',None) 11 print(pd.merge(book,price,left_on='Name',right_on='Book'))
运作結果
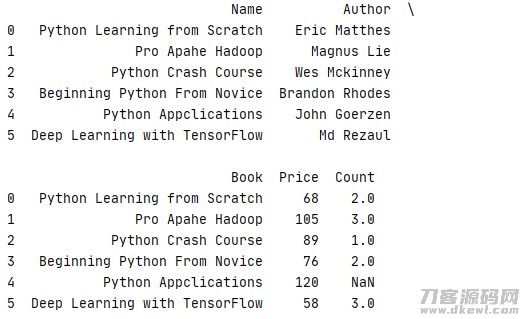
为了更好地防止关联列Name与Book另外表明,能够根据 drop()方式把反复列除掉
1 _book=[['Python Learning from Scratch','Eric Matthes'],['Pro Apahe Hadoop','Magnus Lie'],['Python Crash Course','Wes Mckinney'], 2 ['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen'],['Deep Learning with TensorFlow','Md Rezaul']] 3 column1=['Name','Author'] 4 book=pd.DataFrame(data=_book,columns=column1) 5 6 _price=[['Python Learning from Scratch',68,2],['Pro Apahe Hadoop',105,3],['Python Crash Course',89,1] 7 ,['Beginning Python From Novice',76,2],['Python Appclications',120],['Deep Learning with TensorFlow',58,3]] 8 column2=['Book','Price','Count'] 9 price=pd.DataFrame(data=_price,columns=column2) 10 11 pd.set_option('display.max_columns',None) 12 print(pd.merge(book,price,left_on='Name',right_on='Book').drop('Name',axis=1))
运作結果

也很有可能根据 left_index 和 right_index 来根据数据库索引开展合拼
1 _book=[['Python Learning from Scratch','Eric Matthes'],['Pro Apahe Hadoop','Magnus Lie'],['Python Crash Course','Wes Mckinney'], 2 ['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen'],['Deep Learning with TensorFlow','Md Rezaul']] 3 column1=['Name','Author'] 4 book=pd.DataFrame(data=_book,columns=column1) 5 6 _price=[['Python Learning from Scratch',68,2],['Pro Apahe Hadoop',105,3],['Python Crash Course',89,1] 7 ,['Beginning Python From Novice',76,2],['Python Appclications',120,1],['Deep Learning with TensorFlow',58,3]] 8 column2=['Book','Price','Count'] 9 price=pd.DataFrame(data=_price,columns=column2) 10 11 pd.set_option('display.max_columns',None) 12 print(pd.merge(book,price,left_index=True,right_index=True).drop('Name',axis=1))
运作結果

之上事例上都是默认设置应用内连接 how=’inner’ 回到数据信息的相交, 也可根据设定 how=’outer’ 回到或且
book 结合中不会有书籍 Deep Learning with TensorFlow 的信息内容,因此 默认设置状况下,合拼数据信息后应当只剩余5行数据信息
1 _book=[['Python Learning from Scratch','Eric Matthes'],['Pro Apahe Hadoop','Magnus Lie'],['Python Crash Course','Wes Mckinney'], 2 ['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen']] 3 column1=['Name','Author'] 4 book=pd.DataFrame(data=_book,columns=column1) 5 6 _price=[['Python Learning from Scratch',68,2],['Pro Apahe Hadoop',105,3],['Python Crash Course',89,1] 7 ,['Beginning Python From Novice',76,2],['Python Appclications',120,1],['Deep Learning with TensorFlow',58,3]] 8 column2=['Book','Price','Count'] 9 price=pd.DataFrame(data=_price,columns=column2) 10 11 pd.set_option('display.max_columns',None) 12 print(pd.merge(book,price,left_index=True,right_index=True,how='inner').drop('Name',axis=1))
运作結果

把 how设定为 outer后,运作結果

同样,根据把 how 设定为 left / right,能够应用上下连接
1 _book=[['Python Learning from Scratch','Eric Matthes'],['Pro Apahe Hadoop','Magnus Lie'],['Python Crash Course','Wes Mckinney'], 2 ['Beginning Python From Novice','Brandon Rhodes'],['Python Appclications','John Goerzen']] 3 column1=['Name','Author'] 4 book=pd.DataFrame(data=_book,columns=column1) 5 6 _price=[['Python Learning from Scratch',68,2],['Pro Apahe Hadoop',105,3],['Python Crash Course',89,1] 7 ,['Beginning Python From Novice',76,2],['Deep Learning with TensorFlow',58,3]] 8 column2=['Book','Price','Count'] 9 price=pd.DataFrame(data=_price,columns=column2) 10 11 pd.set_option('display.max_columns',None) 12 print(pd.merge(book,price,left_on='Name',right_on='Book',how='left').drop('Name',axis=1))
运作結果
返回文件目录
14. 列统计函数 describe
panads 中还有一个十分便捷统计分析的 describe 涵数,它功效是对每一列的数个常见统计函数(count、mean、std、min 等)开展测算
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column) 5 print(book.describe())
运作結果
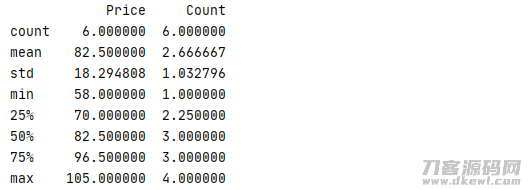
返回文件目录
15. groupby 排序计算
groupby能够使数据信息开展排序后再测算,常见的总计方法有 count 测算行总数、mean 均值 、median中位值 、min 极小值 、max 最高值、std 标准偏差 、var 标准差 、mad 平均值绝对偏差 、prod 全部项相乘 、sum 全部项求饶等方式
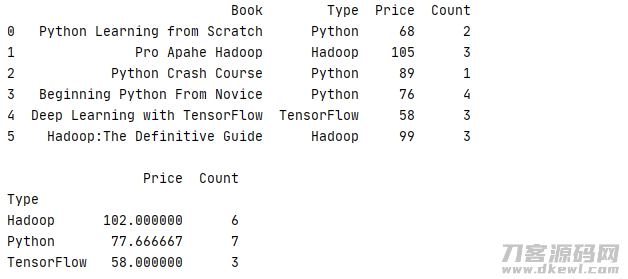
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,2],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column) 5 6 print(book.groupby('Type').sum())
运作結果

也可专业对于某一列进排序计算
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column) 5 print(str(book) '\n') 6 print(book.groupby('Type')['Count'].describe())
运作結果
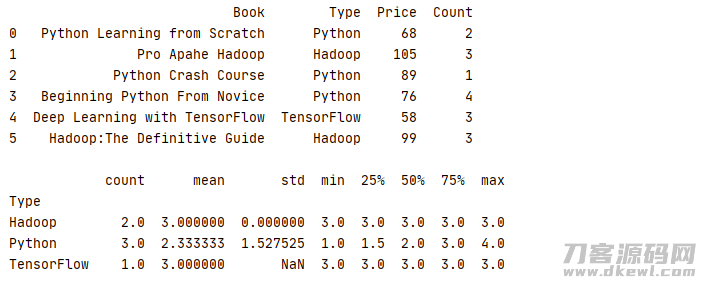
除开一般测算,在排序后还能够开展 aggregate 总计、filter 过虑、transform 变换、apply 运用等实际操作
根据 aggregate 可对于不一样列开展不一样的总计实际操作,事例中便是测算各种书籍的均价与市场销售数量
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column) 5 print(str(book) '\n') 6 print(book.groupby('Type').aggregate({'Price':'mean','Count':'sum'}))
运作結果
应用 filter 便是常见的标准过虑,仅有合乎过虑标准的数据信息才会被算入排序测算之中
func传到的主要参数是 group 的排序的数据,而回到是 bool,根据传参分辨此组数据信息是不是合乎挑选标准
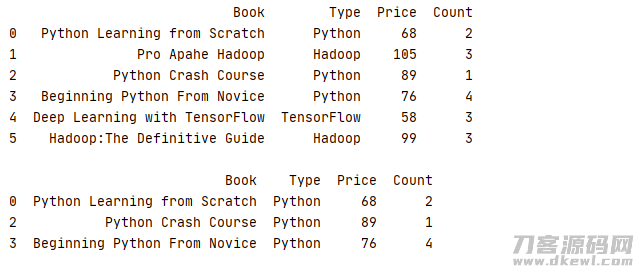
下边的事例便是找到销售量数量超过 6 的书籍
1 def func(x): 2 return sum(x['Count'])>6 3 4 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 5 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 6 column=['Book','Type','Price','Count'] 7 book=pd.DataFrame(data=_book,columns=column) 8 print(str(book) '\n') 9 print(book.groupby('Type').filter(func))
运作結果
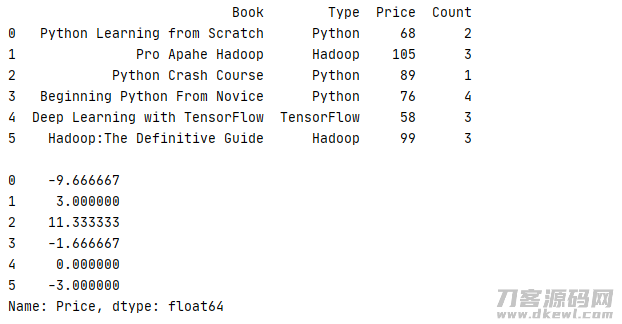
transform 能够对排序内所有数据信息开展计算后回到一个全新升级的数据信息组,最普遍的便是测算数据信息与均值的区别
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column) 5 print(str(book) '\n') 6 print(book.groupby('Type')['Price'].transform(lambda x:x-x.mean()))
运作結果
apply 能够对每一个排序里的数据信息开展随意方式实际操作,唯一不一样的是它键入的主要参数是一个 DataFrame,回到的则是一个数据
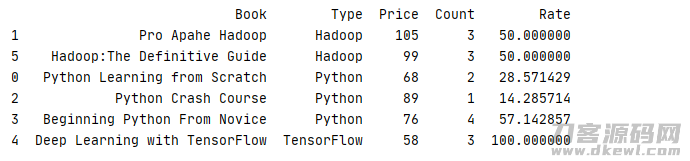
下边事例便是统计分析每一组数据信息内不一样书籍所占的市场销售占有率
1 def data(x): 2 x.insert(4,'Rate','') 3 x['Rate'] = x['Count']/sum(x['Count'])*100 4 return x 5 6 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 7 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 8 column=['Book','Type','Price','Count'] 9 book=pd.DataFrame(data=_book,columns=column) 10 11 print(book.groupby('Type').apply(data).sort_values('Type'))
运作結果
groupby 除开能够依据列等排序外,能够依据数据库索引,数据信息,目录等多种多样方法开展排序,前提条件是数组长度务必与DataFrame的长短一致
下边的事例数据信息便是依据事先界定的二维数组开展排序的
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column) 5 print(str(book) '\n') 6 index=[0,1,0,2,1,3] 7 print(book.groupby(index).sum())
运作結果
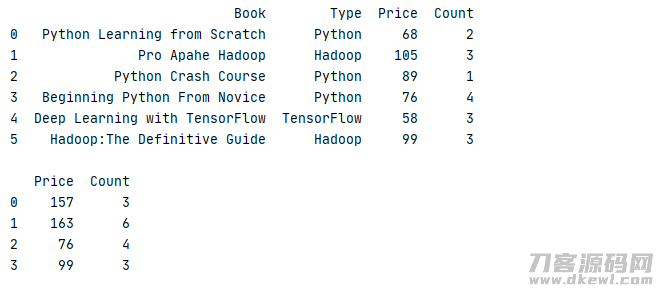
除开应用二维数组之外,还能够应用词典对数据信息开展排序
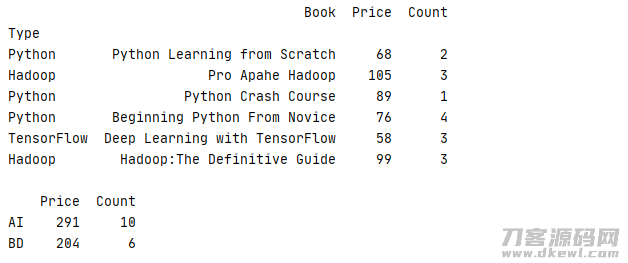
下边的事例把Type为 Python、TensorFlow的书籍归于AI类,把Type为Hadoop归于BD类再开展统计分析
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column).set_index('Type') 5 print(str(book) '\n') 6 mapping={'Python':'AI','TensorFlow':'AI','Hadoop':'BD'} 7 print(book.groupby(mapping).sum())
运作結果
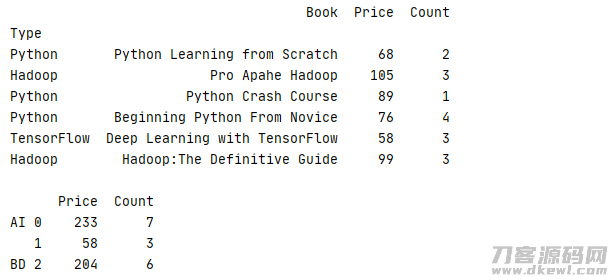
此外,数据信息还能够依据键盘快捷键开展排序,进而回到一个多级别数据库索引的結果
下边的事例把Type为 Python、TensorFlow的书籍归于AI类,把Type为Hadoop归于BD类再开展统计分析,在AI中再各自统计分析 Python、TesnsorFlow数据信息
1 _book=[['Python Learning from Scratch','Python',68,2],['Pro Apahe Hadoop','Hadoop',105,3],['Python Crash Course','Python',89,1] 2 ,['Beginning Python From Novice','Python',76,4],['Deep Learning with TensorFlow','TensorFlow',58,3],['Hadoop:The Definitive Guide','Hadoop',99,3]] 3 column=['Book','Type','Price','Count'] 4 book=pd.DataFrame(data=_book,columns=column).set_index('Type') 5 print(str(book) '\n') 6 index=[0,2,0,0,1,2] 7 mapping={'Python':'AI','TensorFlow':'AI','Hadoop':'BD'} 8 print(book.groupby([mapping,index]).sum())
运作結果
返回文件目录
16. pivot_table 数据透视
设想一下,如果有一组数据信息,它包括了书籍的编程语言(Language)、种类(Tpye)、价格(Price)、市场销售总数(Count),如今想依据书籍的的Language、Type去统计分析书籍的均价 Price,假如用回上一节的事例,我们可以根据 groupby 来完成
1 _book=[['Python Learning from Scratch','Python','AI',68,2],['Pro Apahe Hadoop','Hadoop','BG',105,3],['Python Crash Course','Python','AI',89,1] 2 ,['Beginning Python From Novice','Python','AI',76,4],['Deep Learning with TensorFlow','TensorFlow','AI',58,3] 3 ,['Hadoop:The Definitive Guide','Hadoop','BG',99,3],['HBase: The Definitive Guide','HBase','BG',108,2],['HBase In Action','HBase','BG',79,2]] 4 column=['Book','Language','Type','Price','Count'] 5 book=pd.DataFrame(data=_book,columns=column) 6 print(str(book) '\n') 7 8 print(str(book.groupby(['Language','Type'])['Price'].mean().unstack()) '\n')
运作結果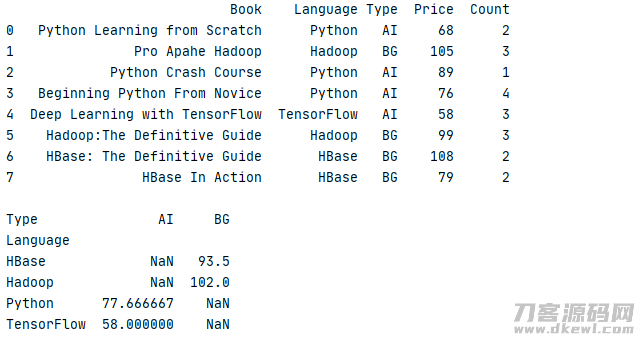
殊不知这类实际操作看上去较为繁杂,并且易读性差,通常开发者必须细心看一段时间才可以搞清楚在其中作用,有见及此系统软件为开发者提前准备了一个方式去完成此作用
pivot_table(values=None,index=None, columns=None,aggfunc=”mean”,
fill_value=None,margins=False,dropna=True, margins_name=”All”,observed=False)
- values:可选主要参数,用于做结合的值,其使用方法与pivot的values相近。默认设置是表明全部的值。
- index:首选主要参数,用于特定行数据库索引。假如用二维数组做行数据库索引,数据信息务必等长。
- columns:首选主要参数,用于特定列数据库索引。
- aggfunc:聚合函数, pivot_table后新dataframe的值都是会根据aggfunc开展计算,默认设置应用mean优化算法求平均值,aggfunc有多种多样书写格式:
aggfunc = [ np.mean ]
- aggfunc = [ np.sum,np.mean ]
- aggfunc = { ‘Price’:’mean’ }
- aggfunc = { ‘Price’:[np.mean] }
- aggfunc = { ‘Price’:np.mean,’Count’:np.sum }
- aggfunc = { ‘Price’:’mean’,’Count’:’sum’}
- fill_value:添充NA值。默认设置不添充
- margins:加上队伍的累计,默认设置无法显示。
- dropna:假如整行都为NA值,则开展丢掉,默认设置丢掉。
- margins_name:在margins主要参数为ture时,用于改动margins的名字
应用下列方式,能够更简易获得同样的实际效果,并且易读性更强,由于 aggfunc 默认设置是测算均值,因此 假如统计分析的是列项,能够无需键入 aggfunc
1 _book=[['Python Learning from Scratch','Python','AI',68,2],['Pro Apahe Hadoop','Hadoop','BG',105,3],['Python Crash Course','Python','AI',89,1] 2 ,['Beginning Python From Novice','Python','AI',76,4],['Deep Learning with TensorFlow','TensorFlow','AI',58,3] 3 ,['Hadoop:The Definitive Guide','Hadoop','BG',99,3],['HBase: The Definitive Guide','HBase','BG',108,2],['HBase In Action','HBase','BG',79,2]] 4 column=['Book','Language','Type','Price','Count'] 5 book=pd.DataFrame(data=_book,columns=column) 6 print(str(book) '\n') 7 print(book.pivot_table(values='Price',index='Language',columns='Type'))
运作結果
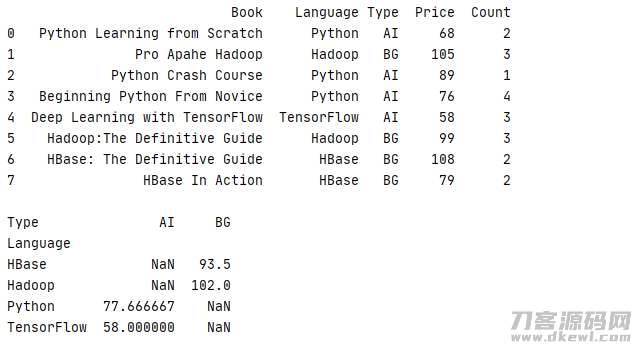
假如必须开展两列测算,刚能够根据 aggfunc 主要参数为不一样的列设定不一样的优化算法,下边的事例便是统计分析均价 Price 和整体总数 Count
1 _book=[['Python Learning from Scratch','Python','AI',68,2],['Pro Apahe Hadoop','Hadoop','BG',105,3],['Python Crash Course','Python','AI',89,1] 2 ,['Beginning Python From Novice','Python','AI',76,4],['Deep Learning with TensorFlow','TensorFlow','AI',58,3] 3 ,['Hadoop:The Definitive Guide','Hadoop','BG',99,3],['HBase: The Definitive Guide','HBase','BG',108,2],['HBase In Action','HBase','BG',79,2]] 4 column=['Book','Language','Type','Price','Count'] 5 book=pd.DataFrame(data=_book,columns=column) 6 print(str(book) '\n') 7 print(book.pivot_table(index='Language',columns='Type',aggfunc={'Price':np.mean,'Count':'sum'}))
运作結果
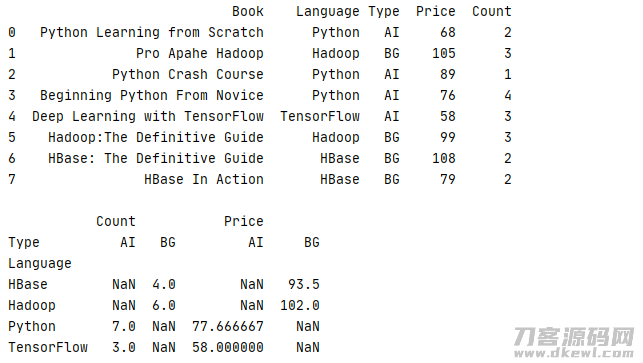
返回文件目录
此章仅仅对 Pandas 常见方式的开展简易详细介绍,期待对诸位的开发设计有一定的协助,要想更深层次地掌握其使用方法,能够参照 pandas 的官方网站表明 https://pandas.pydata.org/
因为時间匆忙,文章内容免不了有发生疏漏的地区,烦请评价
对 .Python 开发设计有兴趣爱好的盆友加入我们QQ群:790518786 一同讨论 !
对 JAVA 开发设计有兴趣爱好的盆友加入我们QQ群:174850571 一同讨论!
对 .NET 开发设计有兴趣爱好的盆友加入我们QQ群:162338858 一同讨论 !
Python 初级教程
爬虫技术入门篇
Pandas 库常见方式案例表明
创作者:尘事天涯浪子
https://www.cnblogs.com/leslies2/p/14764130.html
原创作品,转截时请标明创作者及来源
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0