摘要
ES是全能的数据产品,它在各行各业都有广泛应用。本文分享了华为云服务小区的ES数据库加速实践,让你的ES飞起来!
正文
Elasticsearch数据库优化实战演练:使你的ES飞起来
引言:ES早已变成了全能的数据产品,在许多 行业愈来愈火爆,文中致力于从数据库查询行业剖析ES的应用。
文中共享自华为云服务小区《Elasticsearch数据库加速实践》,全文创作者:css_blog 。
一、计划方案表明
Elasticsearch关键作用是啥,不一样的情景有不一样的精准定位,在日志情景大家可以用ELK绿色生态构建日志数据分析系统,在检索行业ES是当今最受欢迎的百度搜索引擎。在互联网大数据行业,ES能够对比Hbase给予大量日志的数据库管理;在数据库查询行业ES能够做为查看剖析型的剖析型数据库查询应用。ES早已变成了全能的数据产品,在许多 行业愈来愈火爆,文中致力于从数据库查询行业剖析ES的应用。
ES并不是关联型数据库查询,数据信息升级选用乐观锁,根据版本信息操纵,不兼容事务管理,这也是ES差别于传统式数据库查询(Mysql)的地区;可是ES适用精准查看加快,多标准随意组成查看,多种多样汇聚查看,查看速率迅速,能够取代数据库查询繁杂标准查看的情景要求,乃至能够替代数据库查询做二级数据库索引。
在数据库查询加快情景一般的作法是顾客造成的产品订单信息数据信息会载入Mysql类关联型数据库查询,数据库查询载入确保事务性工作,可是伴随着产品订单信息的数据信息愈来愈多,另外顾客查看的标准变化多端,没法全部字段名都创建数据库索引,数据库查询的查看工作能力远远地不可以达到查看需求。大家考虑到用ES全量同歩数据库查询数据信息,在ES中开多标准汇聚查看,查看的結果能够在Mysql中做关系检索,在查看产品订单信息展现, Mysql数据信息和ES数据信息可以不规定即时一致,能够通canal消費Mysql binlog日志信息内容, 同歩到ES,完成一次载入,确保数据一致性。下列数据库查询都以Mysql为例子开展表明。
二、数据库索引基本原理剖析
ES为何查看工作能力远远地超出Mysql关联型数据库查询,主要是她们的完成基本原理和最底层储存的算法设计差别决策的,下列较为二种商品的完成基本原理。
Elasticsearch会对全部键入的文字开展解决,创建数据库索引放进运行内存中,进而提升检索高效率。在这里一点上ES要好于MySQL的B 树的结构,MySQL必须将数据库索引放进硬盘,每一次载入必须先从硬盘载入数据库索引随后找寻相匹配的数据信息连接点,可是ES可以立即在运行内存中就寻找总体目标文本文档相匹配的大概部位,利润最大化提高工作效率。而且在开展组成查看的情况下MySQL的缺点更为显著,它不兼容繁杂的组成查看例如汇聚实际操作,即便要组成查看还要事前建好数据库索引,可是ES就可以进行这类繁杂的实际操作,默认设置每一个字段名全是有数据库索引的,在查看的情况下能够各种各样相互之间组成。
(1)sql索引B 树
数据库查询中数据库索引全是以树来机构的,常见的有B tree,B-tree,B tree,下列详细介绍B tree的组织架构。
最先大家先想像下为何必须创建数据库索引,假定大家有一张表book,储存了大家维持的书本信息内容,名字,创作者,发布时间等,大家有10000条纪录,如果我们必须找一本为《database》的书,那大家的SQL为:
select name,author form book where name = ‘database’;
大家必须扫描仪全部表,全量较为才能够,如果我们对name创建数据库索引,小说名字早已依照次序排列,查看时只必须寻找相匹配部位就可以迅速获得結果。
数据库索引的实质是根据不断变小要想读取数据的范畴来挑选出最后要想的結果,另外把任意的事情变为次序的事情,换句话说,拥有这类数据库索引体制,我们可以一直用同一种搜索方法来锁住数据信息。
数据库查询选用B tree创建数据库索引:
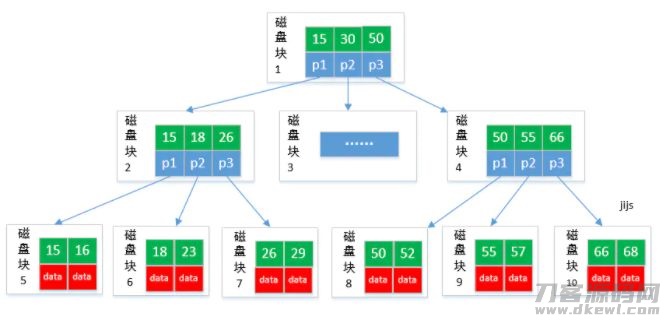
B tree 数据信息只储存在叶子节点中。那样在B树的基本上每一个连接点储存的重要篇幅大量,树的等级更少因此 查看数据信息更快,全部指关键词表针都存有叶子节点,因此 每一次搜索的频次都同样因此 查看速率更平稳。
(2)Elasticsearch数据库索引基本原理
ES创建数据库索引选用全文索引的方法储存。
对键入的全部数据信息都创建数据库索引,而且把全部和文本文档相匹配起來,在大家搜索数据信息的情况下大家立即搜索字典(Term),在寻找Term相匹配的文本文档ID,从而寻找数据信息。这和Mysql应用B tree树创建数据库索引的方法相近,可是假如字典Term非常大,对Term的检索便会比较慢,ES进一步提议了字典数据库索引(FST),提高字典的检索工作能力。
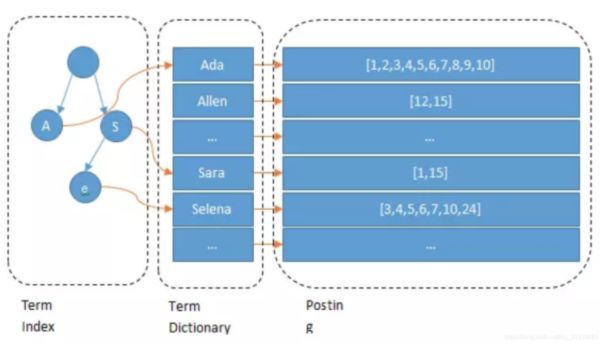
Term Index 以树的方式储存在运行内存中,应用了FST 缩小公共性作为前缀方式巨大的节约了运行内存,根据Term Index查看到Term Dictionary所属的block再去硬盘上找term降低了IO频次。
Term Dictionary 排列后根据二分法将查找的算法复杂度从原先N减少为logN。
三、查看数据分析
下列针对数据库查询检索常见的情景比照ES和数据库查询:
- 全文搜索
ES适用全文搜索,能够对数据信息词性标注,每一个词根据FSP创建字典数据库索引,而Mysql关系型数据库则不兼容,想像下假如检索的并不是全部字段名只是字段名中的好多个关键字,应用Mysql检索务必全表扫描仪。
- 精准检索
假如Mysql对该字段名创建过数据库索引,应用ES检索和Mysql检索特性差别并不大,很有可能Mysql更快点儿,可是ES是分布式架构,能够适用PB等级的数据信息检索,对大表检索ES优点更显著。
- 多标准查看
我们知道Mysql必须对字段名创建数据库索引才可以加快检索全过程,而ES默认设置是全数据库索引的,针对多标准查看,开启Mysql创建联合索引,不然好几个字段名检索,Mysql 先挑选一个字段名检索,結果在应用第二个字段名过虑获得最后結果。
ES则选用好几个字段名結果集交并实际操作,应用bitmap或是skiplist加速检索速率,对比Mysql优点显著。
- 聚合搜索
Mysql聚合搜索要是没有创建数据库索引必须全表扫描仪排列,假如创建数据库索引在B tree上开展范畴查看。
ES为了更好地加速聚合搜索速率,根据Doc value来处理聚合搜索难题。DocValue便是列式储存。
储存結果以下:

Docvalue数据信息依照文本文档ID排列,DocValue将任意载入变成了次序载入,
在es中,由于分块的存有,数据信息被拆分为好几份,放到不一样设备上。可是给客户体验却仿佛只有一个库一样。针对汇聚查看,其解决是分两环节进行的:
- Shard 当地的 Lucene Index 并行处理出部分的汇聚結果。
- 接到全部的 Shard 的部分汇聚結果,汇聚出最后的汇聚結果。
这类两环节汇聚的构架促使每一个 shard 无需把原数据信息回到,而仅用回到信息量小得多的汇聚結果。那样巨大的降低了服务器带宽的耗费。
- 多团本加快
我们知道ES有shard和replica的定义,团本一方面能够确保数据的稳定性,另一方面多团本能够加速检索速率提升检索高并发工作能力。
四、数据库查询到Elasticsearch同歩计划方案
融合客户具体的应用方法和信息量的尺寸,Mysql数据信息到ES能够有各种不同的方法挑选。
- Canal=>Elasticsearch
应用Canal立即消費Mysql binlog日志载入ES,这类方法假如Mysql载入量大,会遭遇Canal载入堵塞难题。
- Canal =>Kafka=>Elasticsearch
Canal数据信息载入到Kafka,应用此外的app消費Kafka数据库同步到ES
五、难题归纳
1.数据库索引shard难题
在Mysql数据库同步到ES中遭遇数据库索引的创建的难题,在数据信息载入ES以前大家必须提早整体规划数据信息的shards和replicas的数量,replicas 能够动态性改动,可是shards数建立进行后不可以改动。
伴随着Mysql信息量的提升,假如shard太少,便会造成每一个shard的信息量很大的难题。
假如一个数据库索引600G,仅有3 个shard,每一个shard就200G,会巨大的耗损查看工作能力,也不利数据备份转移。
我们可以依照月来翻转创建索引,根据数据库索引别称把全部数据库索引关系起來应用。
test_data-202101 test_data-202102
2.查看加快难题
在应用ES对数据库查询开展加快的情景,大家期待的是ES查看工作能力尽量快。在ES查看不符合要求的情况下大家必须对查看开展调优。
常见的方式有:

加关注,第一时间掌握华为云服务新鮮技术性~
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0