摘要
深度聚类算法,是我热爱的研究领域。通过不断的探索和实验,我深刻认识到了它的重要性和挑战性。我将继续努力,为这个领域做出更多的贡献。
正文
深层聚类算法叙谈
文件目录
序言
1 根据自标识的协作聚类算法和表示学习(ICLR, 2020)
1.1 主观因素
1.2 奉献
1.3 试验剖析
1.4 我的想法
2 无标识的图像分类学习培训 (ECCV, 2020)
2.1 主观因素
2.2 奉献
2.3 试验剖析
2.4 我的想法
3 根据词义伪标识的图象聚类算法 (arXiv, 2021)
3.1 主观因素
3.2 奉献
3.3 试验剖析
3.4 我的想法
4 比照聚类算法 (AAAI, 2021)
4.1 主观因素
4.2 奉献
5 根据系统分区利润最大化信度的深层词义聚类算法 (CVPR, 2020)
5.1 主观因素
5.2 奉献
论文参考文献
序言
传统式的K-means聚类算法,针对层面高、量级大的数据不可以非常好地实行聚类算法,乃至没法获得合理的聚类算法实际效果,在具体情景中无法运用。对于以上难题,2016年Deep Embedding Clustering (DEC)[1]深层聚类算法被明确提出,进而推动了深层聚类算法科学研究的风潮。
DEC实质上能够当作是一个自动编码器预训炼获得低维的特点表明 无监督学习调整的一个全过程。在其中,预训练模型的设计方案和挑选对中下游聚类算法每日任务的特性危害非常大(PS:有关DEC的关键点,及其早期的有关科学研究动态性,提议参照:深层聚类算法探讨)。对于该难题,近些年的科学研究选用了自监管的学习方法,即选用聚类算法获得的伪标识来具体指导深度神经网络网络教学一个更为具备辨别性的特点表明,进而解决实体模型对预训练模型的过多依靠。除此之外,小编根据现有的毕业论文阅读文章,发觉在深层聚类算法的研究领域,其发展趋向由时间范围能够简易地区划为下列三点:
1) 以DEC[1]为意味着的预训炼 调整的实体模型
2) 以聚类算法获得伪代码具体指导深层神经元网络开展学习培训的自监督学习[2] (ECCV, 2018, Deep Cluster)的实体模型
3) 依靠预训炼表明聚类算法获得伪代码,选用设计方案的交叉熵损失实行自监管聚类算法选择可预测性标识,最终根据可预测性标识具体指导自监管支持向量机实行半自监督学习[3][4]的实体模型
除此之外,在图象行业的深层聚类算法,深层神经元网络的实体模型挑选,数据增强对策的选择,都是会对中下游的聚类算法每日任务特性造成很大的危害[5]。假如简易地将深层聚类算法转移到一般化的数据上实行聚类算法,必须融合实际难题做实际的对策提升,不然其聚类算法特性并不可以担任K-means。
文中关键纪录自身最近阅读文章的五篇相关深层聚类算法文章内容,每章文章内容都是有给予源代码,若有同学们有兴趣, 能够自主去免费下载有关源代码剖析。
1 根据自标识的协作聚类算法和表示学习(ICLR, 2020)
全文连接
编码
文章内容见刊评分:三分(Weak Reject),8分(Accept),8分(Accept)
文章内容审稿意见
1.1 主观因素
根据深层神经元网络的聚类算法和表示学习是当今的流行方式。殊不知,简易地协同聚类算法和表示学习会造成最后造成衰退的結果。
文中科学研究的基本主要是2018年发布在ECCV上的Deep Cluster模型[2]。该实体模型降到最低归类交叉熵并融合K-means优化算法给予的伪标识开展协同表明和聚类算法,殊不知该全过程因为K-means给予的伪标识存有较多不正确标识的难题,会造成实体模型最后造成一个衰退的解决方法,而且许多 数据信息点非常容易被区划到同一个簇中。
1.2 奉献
为了更好地处理简易地选用协同聚类算法和表示学习造成中下游每日任务特性衰退的难题,文中明确提出了利润最大化标识和键入数据信息引导中间信息内容的方式(下边给得出毕业论文的基础理论证实和表明)。该方式的关键奉献:
1) 证实了将利润最大化标识和键入数据信息引导中间信息内容引进到规范交叉熵降到最低难题中,能够被视作一个最佳运送难题,而且可以在上百万级图象数据信息中高效率地运作;
2) 与ECCV2018文章内容中独立降到最低交叉熵对比,文中根据利润最大化标识和键入数据信息引导中间信息内容,可以防止中下游每日任务造成退解决;
3) 对比ECCV2018另外实行无监督分类和K-means聚类算法, 造成没有一个确立界定的提升总体目标,文中方式根据另外提升自标识和交叉熵损失为中下游每日任务服务项目,可以确保实体模型收敛性到(部分)最优解。
该方式实质是选用最佳运送来完成伪标识的获取(PS:而ECCV2018则是选用K-means对学习培训的表明实行聚类算法获得伪标识),并融合规范的交叉熵损失涵数具体指导深层神经元网络完成对初始图象数据信息的表示学习。
有关最佳运送基础理论的详细介绍提议参照:最佳运送(Optimal Transfort):从基础理论到弥补的运用
自监督学习的标识几率,及其其降到最低的交叉熵损失函数定义以下:

殊不知,在彻底无监管的状况下,选用公式计算(1)非常容易造成衰退的解决方法,其非常容易将全部数据信息点分派给单独或是随意的标识开展降到最低解决。为了更好地处理该难题,真奈美明确提出对伪标识选用一个后验遍布q设置,而且为了更好地防止在提升q的全过程中发生衰退的解决方法,对伪标识开展了根据簇数量和样版数量开展均值复位的管束解决,实际公式计算和界定以下:

交叉熵损失融合伪标识的后验遍布q实行提升时,难以开展优化算法的提升解决。殊不知,该难题能够被视作一个最佳运送难题,而且可以被高效率地处理。拟订的标识伪遍布Q,和实体模型实行无监督分类获得的预测分析結果P,大家的总体目标是使之无穷大,那麼在那样的情况下能够将其视作一个最佳运送难题(PS:这儿的观念,有点儿相近DEC调整中的P和Q的遍布解决)。文中根据最佳运送基础理论,对2个遍布P和Q的界定与计算,将以上公式计算3能够变为下列公式计算5和6,进而变成一个单纯的最佳运送难题:

针对公式计算(5)的计算,关键点能看下面的图的变换:
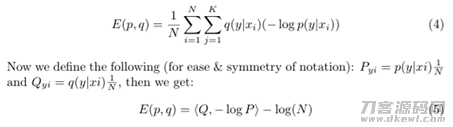
最佳运送难题的解能够视作一个线性规划问题难题,还可以在多项式时间内被处理。殊不知,文中的试验目标做到了百万计的图象数据。对于该难题,文中参照NIPS2013年明确提出的熵正则化观念,选用了一种迅速的Sinkhorn-Knopp优化算法,进而来求得有效的后验伪标识遍布Q。融合最佳运送求得Q的难题界定以下:

根据之上的公式计算计算,文中根据把界定的后验遍布Q和backbone学习培训的交叉熵中的预测分析遍布P协同一起的对策,进而做到表示学习和自标识提升的同歩全过程。操作步骤以下:

对以上的公式计算开展进一步的计算,能够得到下列结果:利润最大化标识和键入数据信息引导中间信息内容。


与独立降到最低熵对比,利润最大化信息内容防止了退解决,由于后面一种在标识y和数据库索引i中间沒有互信息。
此外,文中的关键总体目标是应用聚类算法来学习培训优良的数指Φ,因此 文中还考虑到一个多个任务设定,在其中同样的表明在好多个不一样的聚类算法每日任务中间共享资源,这很有可能会捕捉不一样的和相辅相成的聚类算法轴。
1.3 试验剖析
文中实体模型的关键目地是选用聚类算法的方式学习培训一个更强的数指,可是其最后的中下游每日任务并不一定是用以做聚类算法。因为这篇blog讨论和剖析聚类算法难题,因此 这里只释放文章内容中做聚类算法的无监督分类結果,实际试验結果以下:
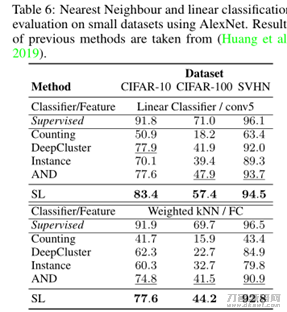

由以上的试验結果,文中明确提出选用最佳运送完成对界定的伪标识遍布Q和交叉熵损失中P开展提升,其在聚类算法特性涂药显著好于K-means。
1.4 我的想法
文中较大 的闪光点取决于把拟订的伪标识遍布Q和降到最低无监督分类交叉熵融合了起來,并证实其为一个基本上的最佳运送难题,这为深层聚类算法方位给予一个新的思索方位。此外,根据文中的解决,可以合理处理简易地选用K-means优化算法给予的伪标识具体指导深层神经元网络实行自监督分类非常容易造成中下游每日任务发生退解决的难题。
2 无标识的图像分类学习培训 (ECCV, 2020)
全文连接
编码
2.1 主观因素
在有监督分类每日任务中,根据真正标识可以具体指导CNN等backbone学习培训到更为具备辨别性的表明。殊不知,在实际情景中存有很多无标识的数据信息。那麼,大家能不能在沒有真正标识的状况下,根据图象的词义信息内容开展全自动排序呢?
另外,当今现有的根据端到端的深层聚类算法,一般选用预训炼 调整的观念。殊不知,这种方式在所难免在调整全过程中遭受低品质特点的危害,非常容易发生不平衡的簇,造成最后发生最优的聚类算法結果。
2.2 奉献
为了更好地处理当今端到端深层聚类算法非常容易发生最优結果的难题,文中明确提出了一种二步法的无监管图象随机森林算法。该方式运用了表明方式和端到端学习的方法的优势,另外也解决了他们的缺陷:
1) 选用一个自监管的pretext每日任务来获得一个更有意义的词义特点,并根据特点相似度发掘每一幅图象的近期邻,促使获取的词义特点更为合适词义聚类算法。比较之下,表征学习方式规定在学习培训特点表明后开展K-means聚类算法,这被觉得会造成聚类算法衰退。
2) 选用品质高的特点来具体指导聚类算法的学习培训,根据那样解决,可以促使聚类算法全过程中防止根据低品质特点来只需聚类算法,而那样的难题是在end-to-end方式中普遍的难题。
3) 此外,文中界定一种根据软标识分派的交叉熵损失涵数,文中将其称之为SCAN-loss,可以合理地对每一幅图象以及隔壁邻居数据信息开展归类,进而促使互联网可以造成一致或是具备鉴别性的预测分析結果。
SCAN-loss的界定以下:

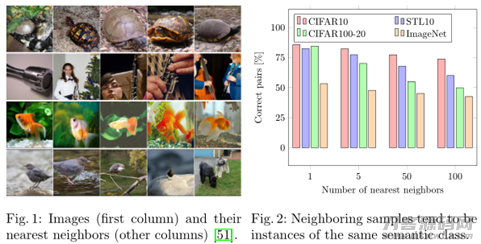
在其中X表明数据信息集中化的样版,k表明该样版的近期邻结合中的样版。以上公式计算第二项的目地是为了更好地防止Φη将全部样版分派给单独群集。假如概率分布函数在群集C中是提早了解的,此项就可以被KL-divergence所取代。有关近期邻的实例如下图所显示:
文中的优化算法关键分成三个流程:
1) 选用一个pretext每日任务,找寻针对数据信息的近期邻
2) 根据近期邻,融合SCAN-loss实行聚类算法
3) 选用聚类算法获得的伪标识,选择可预测性或是真实度较高的标识实行自监督学习,进而进一步提高最后的聚类算法实际效果
实际优化算法的伪代码以下:

2.3 试验剖析
选用K-means对初始的预训炼表明实行聚类算法,会发生簇管理中心不稳定的状况,表1的试验結果能够体现出该假定:聚类算法的ACC标准偏差较大 ,而且为5.7。
此外,能够发觉,根据选用SimCLR数据增强方式并融合SCAN-Loss可以合理提升聚类算法实际效果。除此之外,尽管SCAN-Loss在一些层面和K-means有很大关系,例如全是选用预训炼后获得的特点实行聚类算法。可是,文中明确提出的SCAN-Loss可以防止聚类算法衰退,即聚类算法很有可能会很不稳定的难题,假如选用K-means的簇管理中心开展复位便会造成该难题。此外,文中还讨论了在训炼全过程中,选用不一样的提高对策实行聚类算法的实际效果,试验结果显示,选用RA实行样版提高,可以合理提升聚类算法的实际效果,最大能够做到87.6的ACC。此外,根据伪标识来对聚类算法結果开展调整,可以合理地进一步提高最后的聚类算法实际效果。除此之外,文中根据图6说明,伪标识具体指导的自训炼全过程对设置的阀值主要参数不比较敏感,图7能够近期邻K设置为5就可以做到较平稳的准确度。

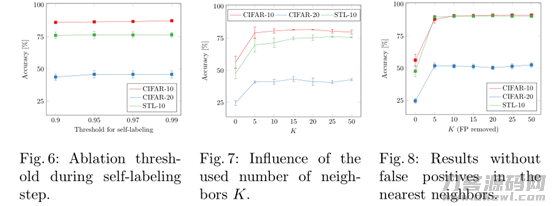
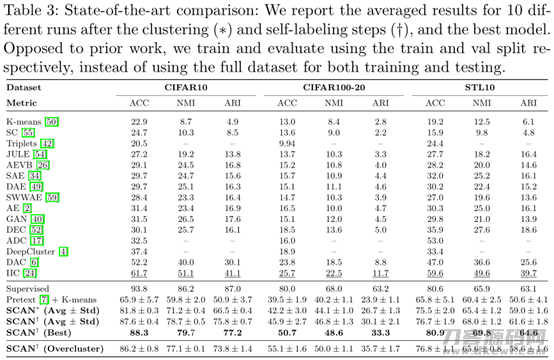
除此之外,文中将簇的数量设置为20而不是10的情况下,文中的聚类算法准确度依然较高,反映出了文中聚类算法实体模型的可靠性。即证实了一点:文中的聚类算法实体模型并不一定至今初始聚类算法簇数量的真正信息内容。文中优化算法在CIFAR100-20选用过度聚类算法的簇数量,其特性提升的一个缘故取决于高的类内标准差。(有关超类的聚类算法特性点评,是一个多对一的投射,其测算的关键点,文中有独立考虑到和解决)
文中选用两台法:预训炼 聚类算法 伪标识实行自监管训炼,的两环节方式,与当今的SOTA的端到端方式不一样。
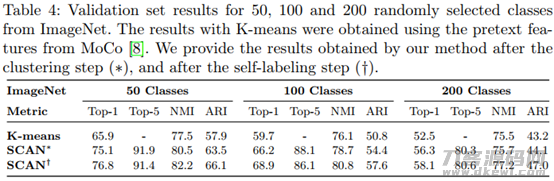
以上的结果显示,选用SCAN-loss实行聚类算法,其在图象上边的聚类算法实际效果要显著好于选用K-means实行聚类算法的結果。除此之外,根据Self-label的自监督学习可以进一步提高最后的聚类算法实际效果。
2.4 我的想法
文中较大 的闪光点取决于沒有一味地追求完美端到端的深层聚类算法实体模型,并强调了当今的端到端深层聚类算法实体模型存有没法解决低品质特点依靠造成最后非常容易发生最优結果的难题。对于以上难题,文中根据近期邻的观念明确提出了SCAN-loss实行聚类算法,可以合理防止立即选用K-means实行聚类算法造成最后发生退解决的难题。除此之外,根据加上Self-Labeling的自监督学习流程,对聚类算法流程中的自监管支持向量机实行进一步的学习培训提升,可以合理提升最后的聚类算法实际效果。
3 根据词义伪标识的图象聚类算法 (arXiv, 2021)
全文连接
编码
3.1 主观因素
以上SCAN聚类算法中选用样版的近期邻来测算SCAN-loss存有下列难题:在具体的样本空间中,并非是全部样版的近期邻都具备同样的词义,例如当样版坐落于不一样簇的界限时,那样的难题会越来越更为比较严重,进而造成最后的聚类算法結果造成差值积累。实际的部分样本空间的词义不一致能够参照下面的图:

除此之外,SCAN优化算法的特性伴随着更替的运作,造成界限的近期邻样版在聚类算法的更替全过程中造成差值积累的难题,而且其在大中型数据信息的线上聚类算法全过程中会遭受特性的限定。
3.2 奉献
对于SCAN优化算法非常容易发生词义不一致的近期邻样版,造成聚类算法結果造成差值积累的难题,文中明确提出了一种根据图象词义伪标识的图象聚类算法架构(SPICE)。该架构的关键奉献以下:
1) 设计方案了一种联级softmax交叉熵损失涵数,可以合理提高实体模型选择伪标识的真实度,进而提升实体模型的聚类算法特性;
2) 融合图象的弱提高和强提高解决,融合归类交叉熵损失涵数来训炼归类互联网,并根据伪标识来融洽样版词义在聚类算法全过程中的差别及其案例样版中间的相似度;
3) 设计方案了一种伪标识获得方式,在网络模型的训炼全过程中可以运用词义相似性衡量来降低样版在界限周边的词义不一致性;
4) 设计方案的部分一致性标准根据将原聚类算法难题转换为半监督学习方式,可以合理降低词义的不一致性,进而提升最后的聚类算法特性。
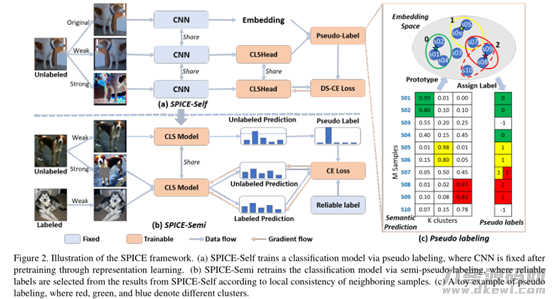
拟议的SPICE架构包含三个学习培训环节。
最先,训炼了一个无监管的表征学习实体模型,该实体模型是在SCAN中应用的;
随后,锁定预训练模型的CNN主杆,各自开展SPICE-Self和SPICE-Semi两个阶段获取置入特点,如上图所述所显示。
SPICE-Self有三个支系:第一个支系以初始图象为I/O置入特点,第二个支系以弱转换图象为I/O词义标识,第三个支系以强转换图象为键入预测分析聚类算法标识。给出前2个支系的結果,根据词义相似性的伪标识优化算法转化成伪标识来监管第三个支系。结合实际,SPICE-Self只必须训炼第三支系的轻量归类头。
SPICE-Semi最先分辨一组靠谱的根据当地词义一致性伪标识,例如SPICE-Self获得的聚类算法結果, 随后选用半监督学习再次训炼分类模型cls Model。
最终,训炼后的分类模型可以预测分析含标识图象和没有标识图象样版的聚类算法标识。
对比SCAN简易地选择每一个样版的近期邻词义样版解决方式,文中明确提出在一个batchsize里边选择在其中超过给出阀值的最自信心的前i个样版做为伪标识。其解决基本原理以下:


留意,在不一样的群集中间很有可能存有重合的样版(PS:实际能够见上图的c中的toy example),因此 有二种方式来解决这种标识:
1) 一个是重合分派,一个样版很有可能有一个之上的类标识,如图所示中淡黄色和鲜红色的圆形所显示。
2) 另一种是是非非重合分派,即全部样版只有一个簇标识,如菜盘鲜红色圆形所显示。
文中试验说明,如第4.5.2小标题所剖析,发觉重合取值更强。
文中明确提出的联级softmax交叉熵损失涵数其立足点是激励实体模型輸出有信心的预测分析,进而有利于对未标识的数据信息学习培训,实际界定以下:

这一联级softmax交叉熵损失函数的概念和第一篇ICLR中界定的后验遍布P融合交叉熵损失涵数的公式计算很像,实际差别待研究(PS:文中并沒有运用和剖析第一篇ICLR2020文章内容)。
除此之外,文中根据选择部分中一部分靠谱的伪标识样版的近期邻,来减轻部分样版词义不一致的难题。在其中部分一致性的界定以下:

在半自监管的学习培训实体模型中,选用SPICE-self流程中获得的真实度高的伪标识,融合未给予伪标识的数据信息开展半监督学习,并融合数据增强和归类交叉熵损失涵数,完成对clshead的学习培训。在其中选用的半监管交叉熵损失函数定义以下:

3.3 试验剖析
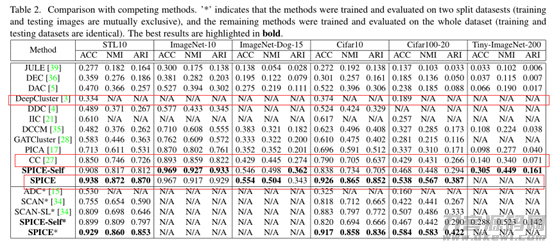
根据以上的试验結果能够发觉,文中融合可预测性高的近期邻样版选择对策及其半自监督学习对策,能够合理提升实体模型的聚类算法实际效果,可以比SCAN聚类方法高大概20%,比全新的AAAI2021文章内容的CC实体模型高10%。
3.4 我的想法
文中是arXiv上公布的全新毕业论文,现阶段应当都还没被有关大会或是刊物接受。文中主要是处理SCAN优化算法中近期邻样版非常容易发生不一致词义的难题,而且在试验实际效果上应比SCAN优化算法强许多 。殊不知,文中的创作并不是很清楚,尤其是引言的创作觉得有点儿长,重要的问题分析有点儿模模糊糊,尤其是创新点的描述不清楚。除此之外,文中的实体模型看起来好繁杂,实际的可扩展性待研究。
最终,文中的可预测性标识的挑选构思能够参照和参考,此外其联级softmax交叉熵损失涵数能够参考和学习培训。
4 比照聚类算法 (AAAI, 2021)
全文
编码
4.1 主观因素
Deep Cluster (ECCV, 2018)选用K-means对每一次epoch完毕后的描述实行聚类算法,随后运用聚类算法获得的伪标识来具体指导深层神经元网络的主要参数升级。这类更替学习的方法会在表示学习和聚类算法中间的更替全过程中累积差值,造成聚类算法特性最优。除此之外,以上方式只有解决线下每日任务,即聚类算法是根据全部数据的,这限定了他们在规模性网上学习情景中的运用。
4.2 奉献
对于Deep Cluster模型更替提升造成聚类算法特性最优的难题,文中明确提出了名叫比照聚类算法(CC)的单环节线上聚类方法,它确立地实行案例级和群集级的比照学习培训。具体地说,针对给出的数据,根据数据信息扩大来结构正案例对和负案例对,随后投射到特点室内空间中。根据另外提升案例级和群集级的比照损害,该实体模型以端到端方法协同学习培训表明和群集分派。文中的实际奉献能够分成下列三点:
1) 大家为当今的深层聚类算法科学研究给予了一种新的看法,即案例表明和聚类算法类型预测分析各自相匹配于可学习培训特点引流矩阵的列和行。因而,深层聚类算法能够雅致地统一到表示学习的架构中;
2) 据大家孰知,这可能是聚类算法特殊比照学习培训的第一个工作中。与目前的比照学习培训科学研究不一样,文中明确提出的方式不但在案例层级上开展比照学习培训,并且在聚类算法层级上开展比照学习培训。试验证实,这类双向比照学习培训架构能够造成聚类算法喜好定性分析;
3) 该实体模型选用单环节、端到端方式,只必须大批量提升,可运用于规模性线上情景。
文中的实体模型的比照观念如下图1所显示:
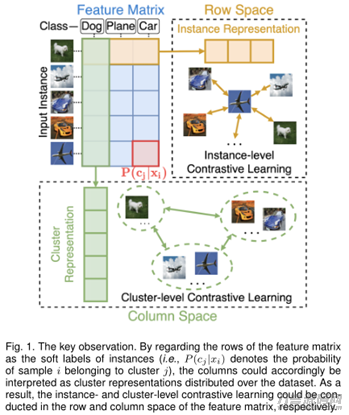
文中实体模型的总体框架图以下:
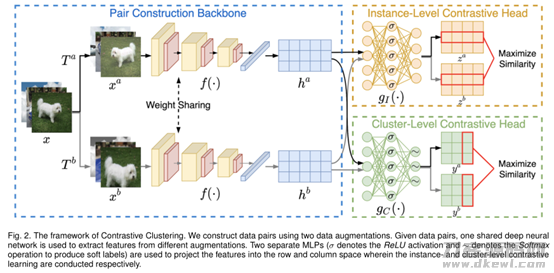
案例级的比照损害测算基本原理以下:

聚类算法层级的比照损害测算方法和案例级类似,差别取决于把行数据信息换为了列数据信息,并加上了熵偏项对策,实际关键点能够参照全文。
本人思索:文中较大 实用价值取决于表明了在深层聚类算法研究领域,图象的数据增强和获得表明的backbone对中下游的聚类算法每日任务特性会出现非常大的危害。除此之外,比照学习培训初次运用到深层聚类算法行业,也表明了比照学习培训观念在积极主动更替提升聚类算法实体模型中可以合理减轻差值积累的难题。
5 根据系统分区利润最大化信度的深层词义聚类算法 (CVPR, 2020)
全文
编码
5.1 主观因素
目前的深层聚类方法一般取决于根据样版间关联或自可能伪标识的部分学习培训管束方式,
这难以避免地遭受的遍布在邻域的差值危害,并在训炼全过程中造成差值散播的积累难题。尽管应用可学习培训表明开展聚类很有可能有益于对无标识数据信息开展聚类算法,但如何提高这种聚类算法的词义合理化依然是一个挑戰(PS:这里的主观因素和第三篇arXiv2021的主观因素相近,可是文中是2020年发布,此外发觉arXiv2021文章内容引入了该一篇文章,而且在试验中关键比照了通篇明确提出的实体模型)。实际的行业差值难题如下图:
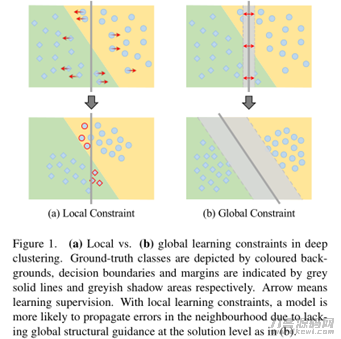
如上图所述所显示,DEC这种方式遭遇着训炼全过程中因为邻域可能不一致而造成的更比较严重的差值散播积累难题。除此之外,因为训炼监管和聚类算法总体目标中间的模糊不清联络,当欠缺全局性解决方法级具体指导时,这类方法通常造成语义上不太可靠的聚类算法解决方法。
5.2 奉献
为了更好地防止行业可变性造成聚类算法的差值积累难题,引进了一种新的深层聚类方法,称之为系统分区置信度利润最大化(PICA),根据从全部很有可能的簇分离出来计划方案中学习培训最靠谱的聚类算法计划方案来处理这个问题。文中的奉献关键分成下列三点:
1) 明确提出了根据较大 切分相信来学习培训语义上最有效的聚类算法解的观念,将經典的较大 边界聚类算法观念拓展到深度神经网络方式。该方式对部分样版间关联和聚类算法簇結果做为标识沒有较强的假定,这一般会造成差值散播和最优的聚类算法解。
2) 引进了一种新的深层聚类方法,称之为系统分区置信度利润最大化(PICA)。PICA是创建在一个新引进的区划可变性指标值的基本上,该指标值设计方案得很雅致,能够量化分析聚类算法解决方法的全局性置信度。
3)引进切分可变性指数值的任意类似,将其与总体目标图象的全部结合解耦,进而能够便捷地选用规范的小批量生产实体模型训炼。
文中的实体模型如下图:
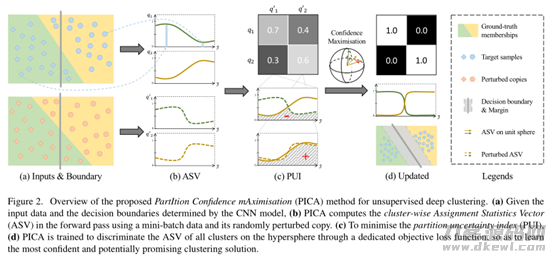
理想化状况下,群集的全部样版将共享资源同样的总体目标类标识。换句话说,文中实体模型的总体目标是立即从原始记录样版中发觉潜在性的词义类管理决策界限(PS:即簇管理中心)。
此外,在聚类算法中,一般发生将绝大多数样版分派到极少数的聚类算法中。为了更好地防止这类状况,文中引进了一个附加的管束,使簇尺寸遍布的负熵降到最低。该对策自己在好几篇文章内容上都有见到那样的解决体制,应当能够做为聚类算法提升挑戰的一个对策。实际的负熵降到最低的对策以下:

本人思索:文中选用余弦相似度测算ASV和PUI的编码和观念,及其其在聚类算法全过程中的运用能够参考和学习培训。此外,能够试着选用文中的观念,融合选用余弦相似度来考量和测算的构思,去思索怎样选择可预测性很大的标识。此外,文中的创作真的是有点儿难以相信,而且引言写的太过技术专业细化,难以让阅读者看懂。
论文参考文献
[1] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised Deep Embedding for Clustering Analysis,” arXiv:1511.06335 [cs], May 2016, Accessed: May 18, 2021. [Online]. Available: http://arxiv.org/abs/1511.06335
[2] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep Clustering for Unsupervised Learning of Visual Features,” arXiv:1807.05520 [cs], Mar. 2019, Accessed: May 18, 2021. [Online]. Available: http://arxiv.org/abs/1807.05520
[3] W. Van Gansbeke, S. Vandenhende, S. Georgoulis, M. Proesmans, and L. Van Gool, “SCAN: Learning to Classify Images without Labels,” arXiv:2005.12320 [cs], Jul. 2020, Accessed: May 16, 2021. [Online]. Available: http://arxiv.org/abs/2005.12320
[4] C. Niu and G. Wang, “SPICE: Semantic Pseudo-labeling for Image Clustering,” arXiv:2103.09382 [cs], Mar. 2021, Accessed: May 16, 2021. [Online]. Available: http://arxiv.org/abs/2103.09382
[5] Y. Li, P. Hu, Z. Liu, D. Peng, J. T. Zhou, and X. Peng, “Contrastive Clustering,” arXiv:2009.09687 [cs, stat], Sep. 2020, Accessed: May 16, 2021. [Online]. Available: http://arxiv.org/abs/2009.09687
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0