摘要
大家平时操作实体模型时,都是用模型名加.objects方法。其实,这个.objects是一个空壳子,没有任何特性和方法。它的方法都是动态添加的,非常灵活。
正文
Django(19)QuerySet API
序言
大家一般做查看实际操作的情况下,全是根据实体模型名称.objects的方法开展实际操作。实际上实体模型名称.objects是一个django.db.models.manager.Manager目标,而Manager这一类是一个“空壳子”的类,他自身是沒有一切的特性和方式 的。他的方式 全是根据Python动态性加上的方法,从QuerySet类中复制回来的。实例图以下: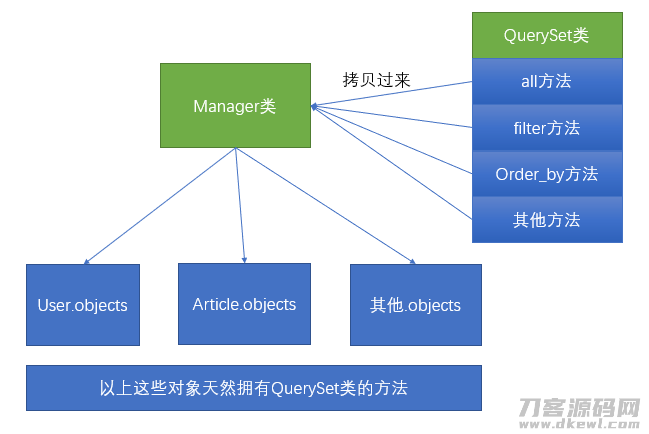
因此大家假如要想学习培训ORM实体模型的搜索实际操作,务必最先要学好QuerySet上的一些API的应用
QuerySet 21个常见的API
filter
filter:将符合条件的数据信息获取出去,回到一个新的QuerySet。实际详细信息可查询这篇:https://www.cnblogs.com/jiakecong/p/14780601.html
exclude
exclude:清除符合条件的数据信息,回到一个新的QuerySet。实例编码以下:
Article.objects.exclude(title__contains='hello')之上编码的意思是获取这些文章标题不包含hello的书籍。
annotate
annotate:给QuerySet中的每一个目标都加上一个应用查看关系式(聚合函数、F关系式、Q关系式、Func关系式等)的新字段。实例编码以下:
articles = Article.objects.annotate(author_age=F("author__age"))之上编码将在每一个目标上都加上一个author__age的字段名,用于表明这一文章内容的创作者的年纪。
order_by
order_by:特定将查看的結果依据某一字段名开展排列。假如要倒序排列,那麼能够在这个字段名的前边加一个负号。实例编码以下:
# 依据建立的時间正序排列
articles = Article.objects.order_by("create_time")
# 依据建立的時间倒序排列
articles = Article.objects.order_by("-create_time")
# 依据创作者的名称开展排列
articles = Article.objects.order_by("author__name")
# 最先依据建立的時间开展排列,假如時间同样,则依据创作者的名称开展排列
articles = Article.objects.order_by("create_time",'author__name')一定要留意的一点是,好几个order_by,会把前边排列的标准给弄乱,而应用后边的排列方法。例如下列编码:
articles = Article.objects.order_by("create_time").order_by("author__name")他会依据创作者的名称开展排列,而不是应用文章内容的建立時间。
values
values:用于特定在获取数据信息出去,必须获取什么字段名。默认设置状况下能把表格中所有的字段所有都获取出去,能够应用values来开展特定,而且应用了values方式 后,获取出的QuerySet中的基本数据类型并不是实体模型,只是在values方式 中特定的字段名合值产生的词典:
articles = Article.objects.values("title",'content')
for article in articles:
print(article)之上打印出出去的article是类似{"title":"abc","content":"xxx"}的方式。假如在values中沒有传送一切主要参数,那麼可能回到一个词典,词典中包括这一实体模型中全部的特性。
如果我们要想获取的是这一实体模型上关系目标的特性,那麼也是能够的,实例编码以下:
articles = Article.objects.values('title', 'content', 'author__name')之上可能获取author的name字段名,如果我们不要想这一名称,想自定名称,能够应用关键词主要参数,实例编码以下:
articles = Articles.objects.values('title', 'content', authorName=F('author__name'))留意:自定的名称不可以跟实体模型上自身有着的字段名一样,例如author__name名称改为author那麼会出错,由于Article实体模型上自身有着一个字段名称为author,会造成矛盾
values_list
values_list:类似values。只不过是回到的QuerySet中,储存的并不是词典,只是元组。实例编码以下:
articles = Article.objects.values_list("id","title")
print(articles)那麼在打印出articles后,結果为<QuerySet [(1,'abc'),(2,'xxx'),...]>等。
假如在values_list中只有一个字段名。那麼你能传送flat=True,那样回到的結果就没有是一个元组,只是全部字段名的值,实例编码以下:
articles2 = Article.objects.values_list("title",flat=True)那麼之上回到的結果是
abc
xxx
all
all:获得这一ORM实体模型的QuerySet目标。
select_related
select_related:在获取某一实体模型的数据信息的另外,也提早将关联的数据信息获取出去。例如获取文章内容数据信息,能够应用select_related将author特征提取出去,之后再度应用article.author的情况下就不用再度去浏览数据库查询了。能够降低数据库的频次。实例编码以下:
article = Article.objects.get(pk=1)
>> article.author # 再次实行一次查看句子
article = Article.objects.select_related("author").get(pk=2)
>> article.author # 不用再次执行查询句子了留意:selected_related只有用在一对多或是一对一中,不能用在多对多或是多对一中。例如能够提早获得文章内容的创作者,可是不可以根据创作者获得这一创作者的文章内容,或是是根据某一篇文章获得这一文章内容全部的标识。
prefetch_related
prefetch_related:这一方式 和select_related十分的相近,便是在浏览好几个表格中的数据信息的情况下,降低查看的频次。这一方式 是为了更好地处理多对一和多对多的关联的查看难题。例如要获得文章标题中含有hello字符串数组的文章内容及其他的全部标识,实例编码以下:
from django.db import connection
articles = Article.objects.prefetch_related("tag_set").filter(title__contains='hello')
print(articles.query) # 根据这条指令查询在最底层的SQL句子
for article in articles:
print("title:",article.title)
print(article.tag_set.all())
# 根据下列编码能够看得出之上代码执行的sql语句
for sql in connection.queries:
print(sql)可是假如在应用article.tag_set的情况下,假如又建立了一个新的QuerySet那麼会把以前的SQL提升给毁坏掉。例如下列编码:
tags = Tag.obejcts.prefetch_related("articles")
for tag in tags:
articles = tag.articles.filter(title__contains='hello') # 由于filter方水陆法会再次转化成一个QuerySet,因而会毁坏掉以前的sql优化
# 根据下列编码,我们可以见到在应用了filter的,他的sql查询会大量,而沒有应用filter的,仅有2次sql查询
for sql in connection.queries:
print(sql)那假如的确是要想在查看的情况下特定过虑标准该怎样做呢,此刻我们可以应用django.db.models.Prefetch来完成,Prefetch这一能够提早界定好queryset。实例编码以下:
tags = Tag.objects.prefetch_related(Prefetch("articles",queryset=Article.objects.filter(title__contains='hello'))).all()
for tag in tags:
articles = tag.articles.all()
for article in articles:
print(article)
for sql in connection.queries:
print('='*30)
print(sql)由于应用了Prefetch,即便在查看文章内容的情况下应用了filter,也总是产生2次查看实际操作
defer
defer:在一些表格中,很有可能存有许多 的字段名,可是一些字段名的信息量可能是较为巨大的,而这时你又不用,例如我们在获得文章列表的情况下,文章内容的內容我们都是不用的,因而此刻大家就可以应用defer来过虑掉一些字段名。这一字段名跟values有点儿相近,只不过是defer回到的并不是词典,只是实体模型。实例编码以下:
articles = Article.objects.defer("title")
for article in articles:
print('article.id')defer尽管能过虑字段名,可是有一些字段名是不可以过虑的,例如id,即便你过虑了,也会获取出去。
only
only:跟defer相近,只不过是defer是过虑掉特定的字段名,而only是只获取特定的字段名。
get
get:获得符合条件的数据信息。这一涵数只有回到一条数据信息,而且假如给的标准有好几条数据信息,那麼这一方式 会抛出去MultipleObjectsReturned不正确,假如给的标准沒有一切数据信息,那麼便会抛出去DoesNotExit不正确。因此这一方式 在读取数据,只有有且只有一条。
create
create:建立一条数据信息,而且储存到数据库查询中。这一方式 等同于先用特定的实体模型建立一个目标,随后再启用这一目标的save方式 。实例编码以下:
article = Article(title='abc')
article.save()
# 下边这行编码等同于之上二行编码
article = Article.objects.create(title='abc')
get_or_create
get_or_create:依据某一标准开展搜索,假如找到那麼就回到这条数据信息,要是没有搜索到,那麼就建立一个。实例编码以下:
obj,created= Category.objects.get_or_create(title='默认设置归类')如果有文章标题相当于默认设置归类的归类,那麼便会搜索出去,要是没有,则会建立而且储存到数据库查询中。这一方式 的传参是一个元组,元组的第一个主要参数obj是这一目标,第二个主要参数created意味着是不是建立的。
bulk_create
bulk_create:一次性建立好几个数据信息。实例编码以下:
Tag.objects.bulk_create([
Tag(name='111'),
Tag(name='222'),
])
count
获得获取的数据信息的数量。假如要想了解一共有多少条数据信息,那麼提议应用count,而不是应用len(articles)这类。由于count在最底层是应用select count(*)来完成的,这类方法比应用len涵数更为的高效率。
first和last
first和last:回到QuerySet中的第一条和最终一条数据信息
aggregate
aggregate:应用聚合函数。实际详细信息可参照这篇:https://www.cnblogs.com/jiakecong/p/14784109.html
exists
exists:分辨某一标准的数据信息是不是存有。假如要分辨某一标准的原素是不是存有,那麼提议应用exists,这比应用count或是断定QuerySet更合理得多。实例编码以下:
result = Book.objects.filter(name="三国演义").exists()
print(result)
distinct
distinct:去祛除这些反复的数据信息。这一方式 假如最底层数据库查询用的是MySQL,那麼不可以传送一切的主要参数。例如要想获取全部市场销售的价钱超出80元的书籍,而且删除这些反复的,那麼能够应用distinct来帮大家完成,实例编码以下:
books = Book.objects.filter(bookorder__price__gte=80).distinct()必须留意的是,假如在distinct以前应用了order_by,那麼由于order_by会获取order_by中特定的字段名,因而再应用distinct便会依据好几个字段名来开展唯一化,因此就不容易把这些反复的数据信息删除。实例编码以下:
orders = BookOrder.objects.order_by("create_time").values("book_id").distinct()那麼之上编码由于应用了order_by,即便应用了distinct,也会把反复的book_id获取出去。
update
update:实行升级实际操作,在SQL最底层走的也是update指令。例如要将全部category为空的article的article字段名都升级为默认设置的归类。实例编码以下:
Article.objects.filter(category__isnull=True).update(category_id=3)
delete
delete:删掉全部符合条件的数据信息。删掉数据信息的情况下,要留意on_delete特定的处理方法。
切成片
切成片实际操作:有时大家搜索数据信息,有可能只必须在其中的一部分。那麼此刻能够应用切成片实际操作来帮大家进行。QuerySet应用切成片实际操作就跟目录应用切成片实际操作是一样的。实例编码以下:
books = Book.objects.all()[1:3]
for book in books:
print(book)切成片实际操作并并不是把全部数据信息从数据库查询中获取出去再做切成片实际操作。只是在数据库查询方面应用LIMIE和OFFSET来帮大家进行。因此假如只必须取在其中一部分的数据信息的情况下,提议大伙儿应用切成片实际操作。
Django将QuerySet变换为SQL句子去实行的五种状况
- 迭代更新:在解析xml
QuerySet目标的情况下,会最先先实行这一SQL句子,随后再把这个結果回到开展迭代更新。例如下列编码便会变换为SQL句子:
for book in Book.objects.all():
print(book)- 应用步幅做切成片实际操作:
QuerySet能够类似目录一样做切成片实际操作。做切成片实际操作自身不容易实行SQL句子,可是假如在做切成片实际操作的情况下给予了步幅,那麼便会立刻实行SQL句子。必须留意的是,做切成片后不可以再实行filter方式 ,不然会出错。 - 启用len涵数:启用len涵数用于获得
QuerySet中一共有多少条数据信息也会实行SQL句子。 - 启用list涵数:启用list涵数用于将一个
QuerySet目标变换为list目标也会立刻实行SQL句子。 - 分辨:假如对某一
QuerySet开展分辨,也会立刻实行SQL句子。
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0