摘要
读《Fast Network Embedding Enhancement via High Order Proximity Approximation》感触颇深,作者构思巧妙、解决难题、奉献精神可嘉。参考文献丰富,值得深入研究。
正文
[毕业论文阅读心得] Fast Network Embedding Enhancement via High Order Proximity Approximati
[毕业论文阅读心得] Fast Network Embedding Enhancement via High Order Proximity Approximation
文中构造
- 解决困难
- 关键奉献
- 具体内容
- 论文参考文献
(1) 解决困难
大部分此前的工作中,要不是沒有充分考虑互联网的高级相似性(如谱聚类,DeepWalk,LINE,Node2Vec),要不是考虑到了但却促使优化算法高效率很低,不可以扩展到规模性互联网(如GraRep)。
(2) 关键奉献
Contribution 1. 将很多目前的NRL优化算法构架汇总成一个统一的架构(相似性引流矩阵结构及其特征提取),而且得到一个结果,假如更高级的相似性信息内容被考虑到进相似性引流矩阵,那麼NRL优化算法的定性分析实际效果会提升 。
Contribution 2. 明确提出了NEU提高对策来提升 目前的NRL优化算法的定性分析实际效果,经过NEU优化算法解决过的定性分析引流矩阵R在理论上融进了连接点的更高级相似性(类似)。最终,在多标签分类和链接预测分析试验上证实了优化算法不但在時间上是合理的,并且在精密度上也是有非常大提高的。
(3) 具体内容
1. 准备专业知识
- K阶相似性: 一阶相似性能够表明为两连接点的边权,二阶相似性能够表明为两连接点的公共性隔壁邻居数,那麼营销推广到更高级的相似性呢?最先考虑到二阶相似性的另一种表述:连接点vi走两步抵达连接点vj的几率。将一阶二阶相似性简易营销推广到k阶相似性,即连接点vi走k步抵达连接点vj的几率。 假定A为归一化后的邻接矩阵(一阶相似性迁移几率引流矩阵),那麼k阶相似性迁移几率引流矩阵为Ak(k阶相似性转移矩阵),Akij表明连接点vi走k步抵达连接点vj的几率。
(本人了解: 高级相似性怎么会起功效?因为实际中的互联网通常全是稀少的,这代表着边的经营规模和连接点的经营规模通常是一样的。因而,真正互联网的一阶相似性引流矩阵一般是十分稀少的,光凭一阶相似性已不能反映连接点间的关联。因而,必须融合更高级的连接点相似性)
2. 统一架构
毕业论文明确提出了一个根据相似性引流矩阵的特征提取(矩阵分解)的统一架构,并将目前优化算法归结到该架构中。
根据相似性引流矩阵的特征提取(矩阵分解)统一架构包括2个流程:
- Step 1:相似性引流矩阵M的结构。(如邻接矩阵,拉普拉斯引流矩阵,k阶相似性引流矩阵等)
- Step 2:相似性引流矩阵的特征提取,即矩阵分解,如特征值分解或SVD溶解。
总体目标: 溶解引流矩阵 M=RCT,即找寻引流矩阵R和引流矩阵C来似引流矩阵M,引流矩阵M和引流矩阵RCT的离可以用差的矩阵范数来表。在其中,R为管理中心空间向量定性分析矩,C为前后文空间向量定性分析引流矩阵。
举例子优化算法合乎以上统一架构:
Example 1:Spectral Clustering(SC)
相似性引流矩阵M:归一化后的拉普拉斯引流矩阵(一阶相似性)
特征提取方式 :特征值分解。
Example 2:Graph Factorization (GF)
相似性引流矩阵M:归一化后的邻接矩阵(一阶相似性)特征提取方式 :SCD溶解。
Example 3:DeepWalk
相似性引流矩阵M:
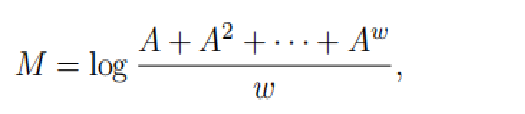
DeepWalk优化算法以根据马尔可夫链转化成的取样来类似高级相似性,而沒有事实上去精准测算k阶相似性引流矩阵。
特征提取方式 :以目标函数提升的方法,SkipGram的总体目标提升(SGD),找寻引流矩阵R和引流矩阵C促使RCT类似M。
Example 4:GraRep
优化算法基本原理:
GraRep精准测算1,…k阶,k个相似性引流矩阵,而且为每一个相似性矩阵运算一个特殊的表 征(运用SVD溶解),最终将这k个定性分析相互连接。
实质上也是根据相似性矩阵分解,归属于明确提出的统一架构可是,GraRep不可以合理适用规模性互联网,测算高效率太低。
3. 优化算法基本原理
依据之上优化算法存在的不足:本毕业论文科学研究怎样从类似高级相似性引流矩阵中合理的网络营销知识定性分析(促使优化算法不仅有高效率又有实际效果)。
假定大家早已用以上NRL架构中的某一算法学习了相对性较为低级的相似性引流矩阵f(A)的类似RCT。在这个基本以上,大家的总体目标是去学习一个更强的R’和C’,其R’C’T类似一个更高级的引流矩阵g(A),其度比f(A)高些。
f(A)的界定(相似性引流矩阵):表明由A的1…k次幂构成的代数式。f(A)的度k表明代数式中充分考虑的较大 阶的相似性,即A的较大 次幂,参照之上DeepWalk的相似性引流矩阵,f(A)=M。
注意到NEU优化算法主要是为了更好地提高别的表示学习实体模型获得的置入結果,即在带有低级信息内容的置入空间向量的基本上,结合更高级的信息内容转化成品质更强的置入空间向量。该优化算法基本原理非常简单,即对别的优化算法获得的表明空间向量置入引流矩阵做一个后处理工艺实际操作,其迭代更新公式计算以下:
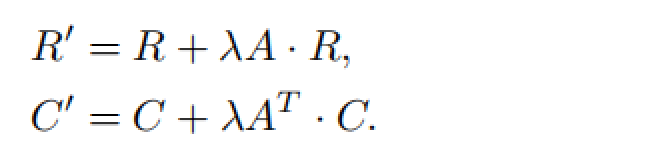
一个疑惑:这一R和C的迭代更新是怎么考虑到进了更高级的相似性的?
Theorem:
给出互联网定性分析引流矩阵R和向下面空间向量定性分析引流矩阵C(可由别的定性分析算法学习而得),假定RCT类似相似性引流矩阵M=f(A),类似差值限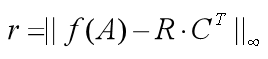
且f(A)的度为K。经过以上迭代更新公式计算(3)升级而得的R’和C’的积R’C’T近似于引流矩阵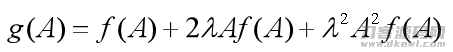
g(A)具备K 2的度,且类似差值限为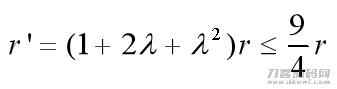
由之上定律能够下结论: 即每迭代更新一次,溶解的类似相似性引流矩阵的度提高2,可是相对应的差值限制会提高2.25倍,因而务必衡量融进的高级连接点相似性信息内容及其相对应的差值。
一个变异的迭代更新公式计算: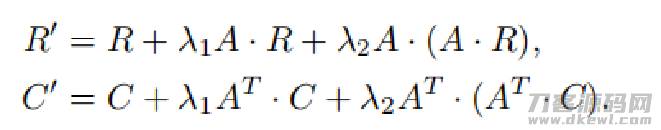
能够推得变异迭代更新公式计算在一次迭代更新中能够得到更高级的相似性(第一个迭代更新公式计算一次迭代更新仅仅多了2阶)。(自然比变异迭代更新公式计算更繁杂的在一次迭代更新中得到更高级的相似性的迭代更新公式计算能够相近营销推广)
汇总:讲了那么多便是对别的表示学习优化算法获得的置入引流矩阵开展之上迭代更新,就可以在置入空间向量中融进更高级的信息内容。
(4) 论文参考文献
Yang C , Sun M , Liu Z , et al. Fast Network Embedding Enhancement via High Order Proximity Approximation[C]// International Joint Conference on Artificial Intelligence. AAAI Press, 2017.
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0