摘要
系统软件不听使唤,Redis操作出错,让人急得火冒三丈!小编赶紧上阵,一步步清查,终于找到了问题的根源。
正文
日常Bug清查-系统软件丧失回应-Redis错误操作
日常Bug清查-系统软件丧失回应-Redis错误操作
序言
日常Bug清查系列产品全是一些简易Bug清查,小编将在这儿详细介绍一些清查Bug的简易方法,另外顺带积累素材_。
Bug当场
开发设计反映网上系统软件发生丧失回应的状况,接到业务流程报警早已经常MarkAndSweep(Full GC)报警。因此寻找小编开展清查。
看基本监管
最先呢,自然是看大家的监管了,寻找相匹配丧失回应的系统软件的ip,看下大家的基本监管。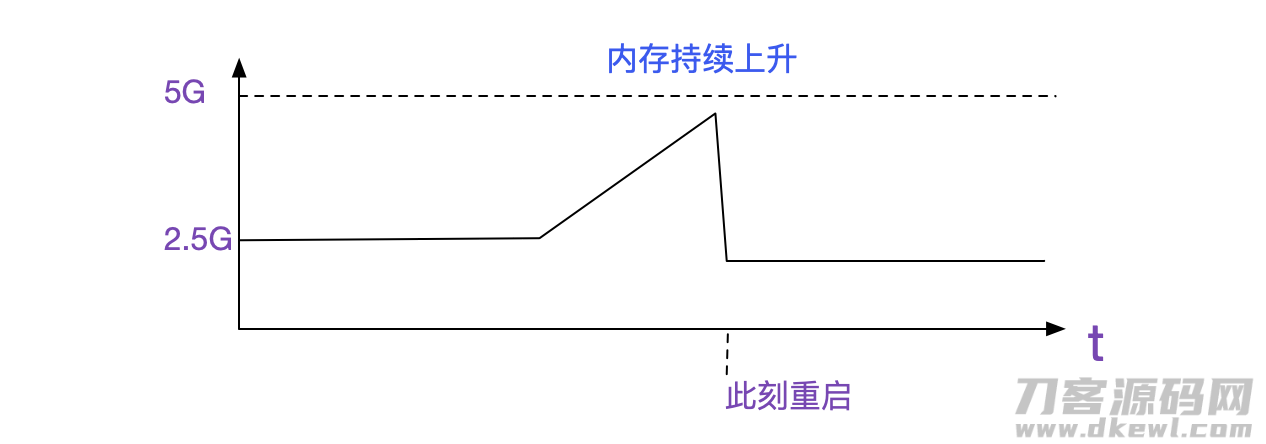
设备运行内存持续增长。由于我们都是java系统软件,堆的尺寸一开始早已设定了最高值。
--XX:Xms2g -Xmx2g
因此看起来像堆外内存泄露。而FullGC报警仅仅堆外运行内存后一些关系堆内目标开启。
看运用监管
第二步,自然便是观查大家的运用监管,这里小编用的是CAT。观查Cat中相匹配运用的状况,非常容易发觉,其ActiveThread展现异常的状况,居然做到了5000 好几个,另外和运行内存升高曲线图保持一致。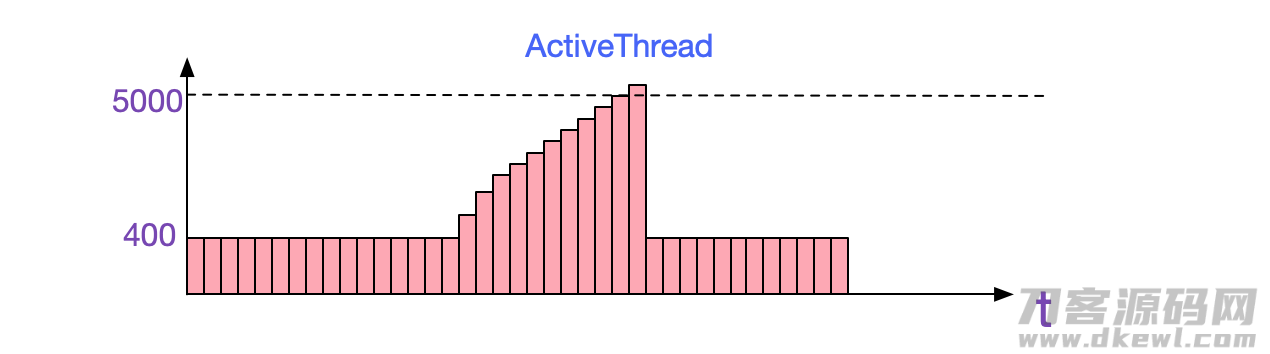
jstack
java运用中碰到线程数太多的状况,最先大家考虑到的是jstack,jstack出去相匹配的文档后。大家less一下,发觉很线程同步卡在下面的编码栈上。
"Thread-1234
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park
......
at org.apache.commons.pool2.impl.LinkedBlockingQueue.takeFirst
......
at redis.clients.util.Pool.getResource
很显著的,这一编码栈非常值得是沒有获得联接,进而卡死。对于为何卡那么长期而不释放出来,肯定是因为没设定请求超时時间。那麼是不是绝大多数进程都卡在这儿呢,这儿大家做一下统计分析。
cat jstack.txt | grep 'prio=' | wc -l
======> 5648
cat jstack.txt | grep 'redis.clients.util.Pool.getResource'
======> 5242
能够见到,一共564八个进程,有5242,也就是92%的进程卡在Redis getResource中。
看下redis状况
netstat -anp | grep 6379
tcp 0 0 1.2.3.4:111 3.4.5.6:6379 ESTABLISHED
......
一共五个,并且联接情况为ESTABLISHED,一切正常。不难看出她们配备的最大连接数是5(由于其他进程已经获得获得Redis資源)。
Redis联接泄漏
那麼很当然的想起,Redis联接泄漏了,即运用得到Redis联接后沒有还回来。这类泄漏有下边几类很有可能:
状况1: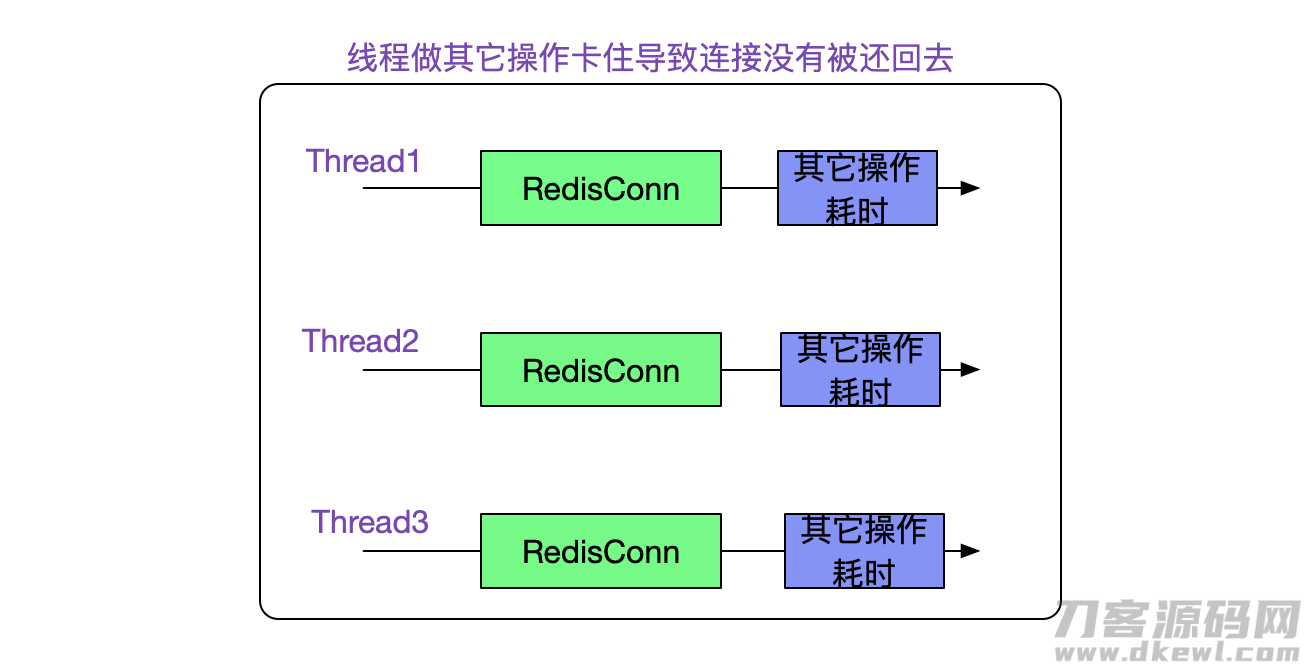
状况2:
状况3:
启用Redis卡死,因为其他设备是好的,故清除这类状况。
如何区分
大家做一个简易的逻辑推理:
如果是状况1,那麼这一RedisConn毫无疑问能够根据运行内存可进入性剖析和Thread关系上,并且这一关联方交易毫无疑问会关系到某一业务流程实际操作实体线(比如code stack or 业务流程bean)。那麼大家只需观查其在堆内的关系线路是不是和业务流程有关就可以,要是没有一切关系,那麼基本上判断是状况2了。
可进入性剖析
我们可以根据jmap dump出运用运行内存,随后根据MAT(Memory Analysis Tool)来开展可进入性剖析。
最先寻找RedisConn
将dump文档在MAT中开启,随后运作OQL:
select * from redis.clients.jedis.Jedis (RedisConn的dao层)
检索到一堆Jedis类,随后大家实行
Path To GCRoots->with all references
能够见到以下結果:
redis.clients.jedis.Jedis
|->object
|->item
|->first
|->...
|->java.util.TimerThread
|->internalPool
不难看出,大家的联接只是被TimerThread和internalPool(Jedis自身的数据库连接池)拥有。因此我们可以分辨出大概率是状况2,即忘记了偿还联接。翻阅业务流程编码:
伪代码
void lock(){
conn = jedis.getResource()
conn.setNx()
// 完毕,这里应当有finally{returnResource()}或是选用RedisTemplate
}
最终便是非常简单的,业务流程开发设计在实行setNx实际操作后,忘记了将联接还回来。造成联接泄漏。
如果是状况1怎样定位卡死的编码
到这里,这个问题时解决了。可是如果是状况1得话,大家又该怎样剖析下来呢?非常简单,大家假如找到jedis被哪一个业务流程进程有着,立即从heap dump寻找其进程号,随后取Jstack中检索就可以了解其卡死的编码栈。
jmap:
redis.clients.jedis.Jedis
|->Thread-123
jstack:
Thread-123 prio=...
at xxx.xxx.xxx.blocked
汇总
这是一个非常简单的难题,了解招数以后清查起來彻底不费劲。尽管最终清查出去是个很低等的编码,可是这类统计分析方法非常值得参考。

关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0