摘要
RankIQA是一种无参考图像质量评估方法,通过从排名中学习来解决IQA数据集大小有限的问题。我们使用合成的已知相对图像质量排名的数据集来训练网络,并对图像进行排名,这样就不用主观方法去标注了。这种方法真是太棒了!
正文
论文笔记:RankIQA
0.Abstract
本文提出了一种从排名中学习的无参考图像质量评估方法(RankIQA)。为了解决IQA数据集大小有限的问题,本文训练了一个孪生网络,通过使用合成的已知相对图像质量排名的数据集来训练网络并对图像进行排名。这些具有排名的数据集可以不用主观方法去标注,而是自动生成(失真代码)。然后本文把训练好的孪生网络中表示的知识(生成的网络权重,其特征表示的是失真)微调(fine-tuning)到传统的CNN,以此来对单个图像进行图像质量评估的绝对分数的估算。本文还提出了如何通过单个网络向前传播一批图像并反向传播该批次的所有图像对(pairs of images)得出的梯度,从而使本文的方法比传统的孪生网络有效得多。在TID2013基准实验上,本文的方法优于现有的NR-IQA技术,甚至在无需高质量图像对照的情况下,本文的方法甚至全部领先于最新的技术。
1.Introduction
绝大多数可用的IQA数据集太小而无法有效的训练CNN。本文提出了一种解决大型数据集缺失的方法。虽然很难获得人工主观方法标记得到的数据集,但是可以方便的使用失真代码来生成没有绝对质量评估分数但是有相对质量评估等级的数据集。
本文使用孪生网络来学习根据图像质量对图像进行评估,然后将学到的模型权重微调到传统CNN中,提高IQA的准确性。
本文提出了一种在孪生网络中进行高效反向传播的方法。该方法通过单个网络转发一批图像(a batch of image),然后反向传播该批次中所有图像对(all pairs of images)得出的梯度。这种方法被证明能比其他训练方法(hard-negative mining)更好,更快的训练网络。
2. Related work
传统的NR-IQA方法
大多数传统的NRIQA可分为自然场景统计(NSS)方法和基于学习的方法。
在NSS方法中,假设不同质量的图像在对特定过滤器响应的统计中有所不同。
在基于学习的方法中,使用支持机器回归或神经网络提取局部特征并映射到 MOS。
码本(codebook)方法结合了不同的功能,而不是直接使用局部特征。可以利用没有 MOS 的数据集通过无监督学习构建码本(codebook),由于现有数据集规模较小,这一点尤为重要。Saliency 特征可用于模拟人类视觉系统(HVS)并提高这些方法的精度。
深度学习的NR-IQA方法
近年来,一些作品将深度学习用于 NR-IQA。深度网络的主要缺点之一是需要大型标记数据集,这些数据集目前无法用于 NR-IQA 研究。
Kang考虑小32×32个补丁(patches)而不是图像,从而大大增加了训练样本的数量。
有人设计了一个多任务 CNN(multi-task CNN),以同时了解失真类型和图像质量。
Bianco 建议使用预先训练的网络来缓解培训数据的缺乏。他们从在IQA数据集中微调的预先训练的模型中提取特征。然后将这些特征用于训练 SVR 模型,以便将特征映射到 IQA 分数。
本文提出了一个完全不同的方法来解决缺乏训练数据的问题:使用大量自动生成的图像质量排名(合成失真的数据集)来训练深度网络。这使得能够训练比之前的深度学习NR-IQA 的方法中直接根据绝对 IQA 数据进行训练的其他方法更深入、更广的网络。
排名学习
这些方法通过将排名损失函数(rank loss)降至最低从标注的真实排名中学习排名特征。然后,此特征可用于对测试对象进行排名。
孪生网络架构结合了排名和 CNN 的想法,在人脸验证问题和图像补丁比较(comparing image patches)方面取得了巨大成功。
本文的方法并不是为了训练出一个可以得到排名的网络,而是用排名学习来作为一个数据增强技术。我们通过容易获得的排名好(图像质量评估分数)的图像数据集来训练一个大的网络,然后用来微调到NR-IQA任务中(得出无参考图像质量评估分数)。
孪生网络中的难例挖掘
难优劣挖掘策略( hard positive and hard-negative mining strategy),以向前传播一组对,并采样向后传播中损失最高的对(pairs),然而伴随着高昂的计算成本。
半硬对(semi-hard pair selection)被认为选择最难的对可能导致糟糕的局部收敛。
以一批对作为输入,并选择小批次(mini-batch)中的四个最难的负样本。为了解决不良的局部收敛,优化光滑的上界损失特征,以利用小批次(mini-batch)中所有可能的对。
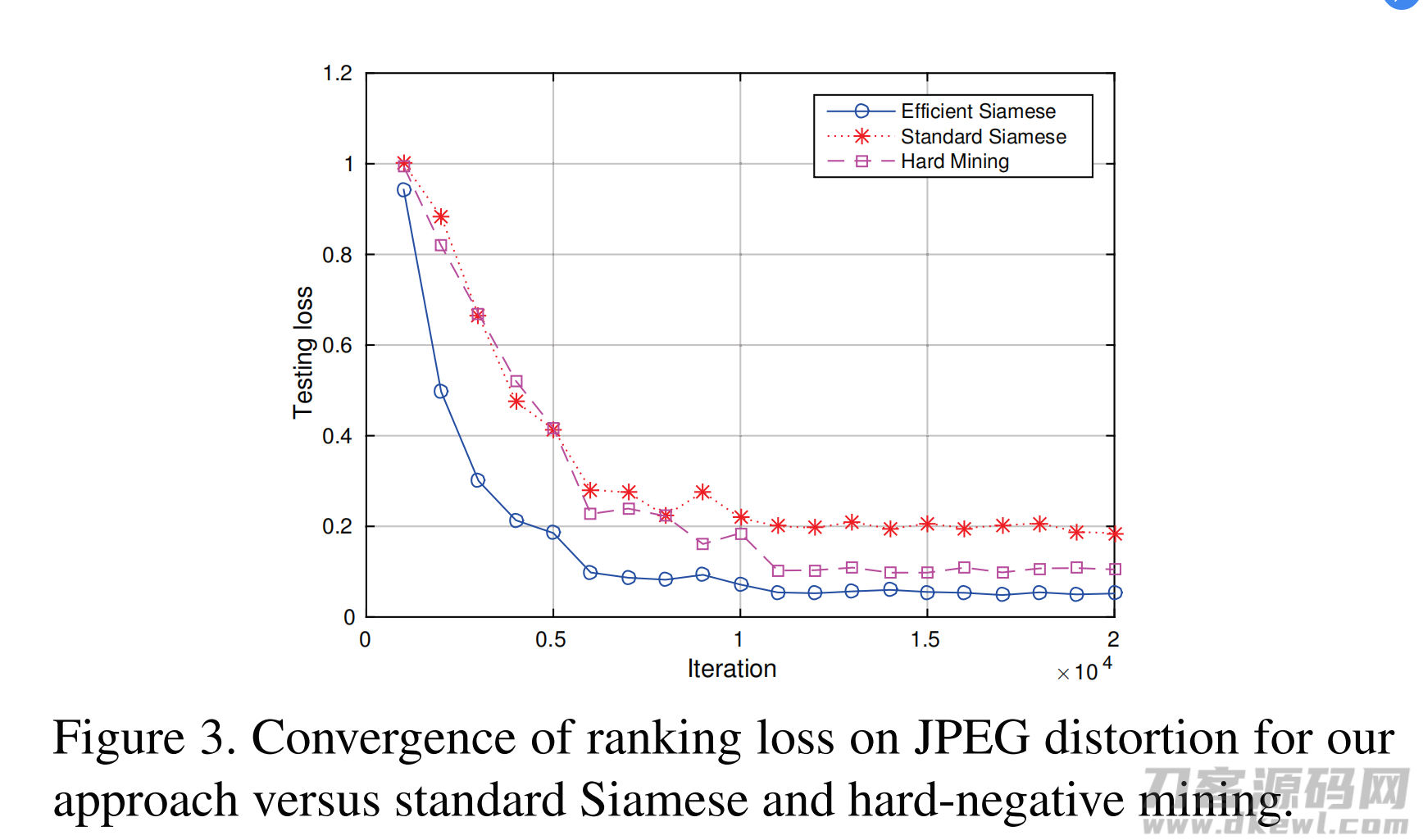
本文提出了一种高效的孪生网络向后传播方法,它不依赖于难例选择。而是考虑了小批次(mini-batch)中所有可能的对。这有利于优化利用训练深网的主要计算瓶颈,即通过网络对图像的前向传播。
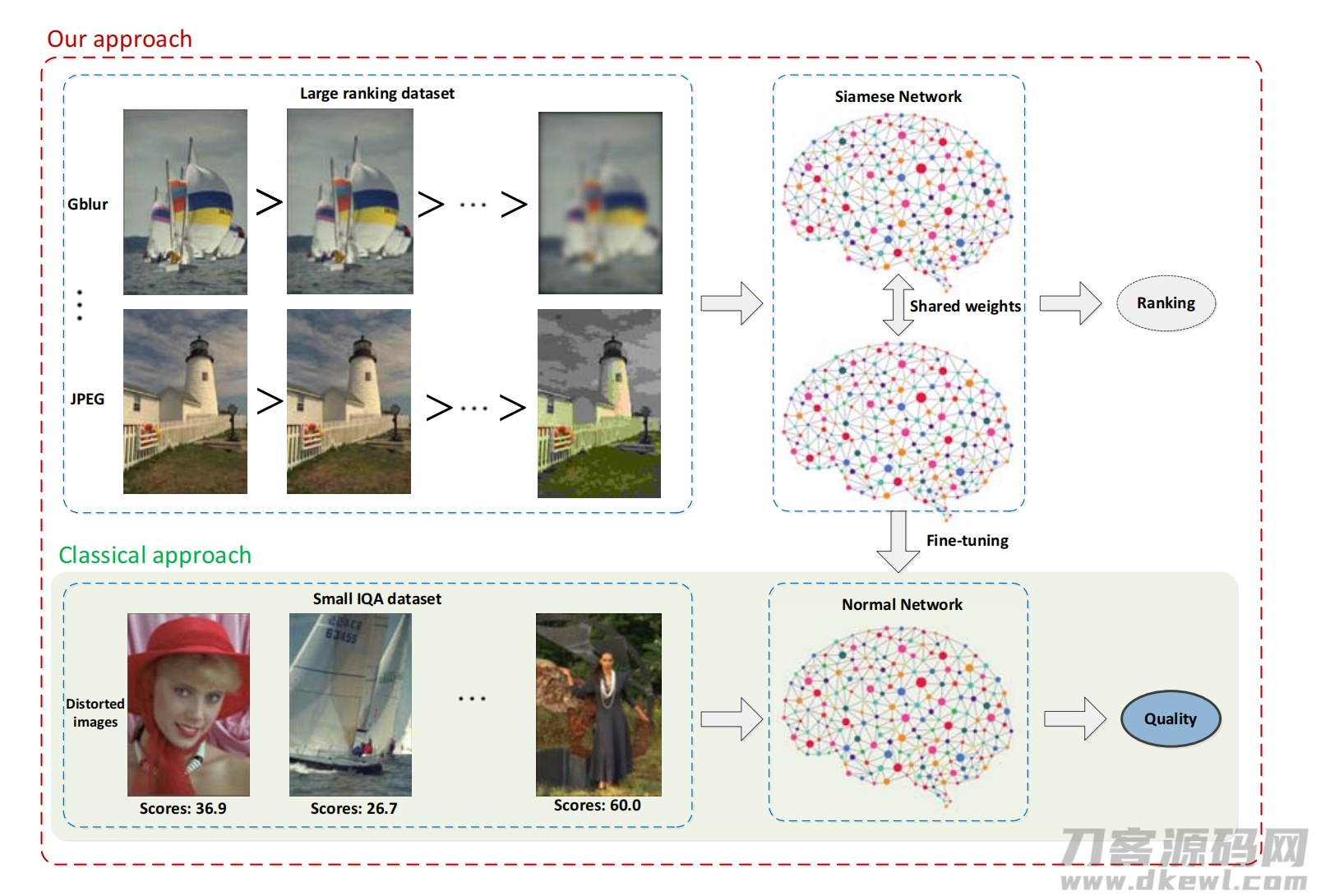
3. Learning from rankings for NR-IQA
3.1 本文方法架构
本文的步骤:
- 合成排名图像。 使用任意的数据集,通过一系列失真程度合成这些图像的合成失真数据集。每个图像的绝对失真量不用于后续步骤,而是在知道的每个失真类型中,用于任何质量较高的图像对。
- 培训孪生网络进行排名。 这里用到高效的孪生网络向后传播方法。
- 使用IQA数据集训练网络进行微调。 首先提取孪生网络的一个分支(此时对在网络中学到的特征感兴趣,而不是在排名本身的结果中感兴趣),并根据可获得IQA数据集进行微调继续训练网络,这有效地校准了网络以输出 IQA 分数。
3.2 使用孪生网络来进行排名训练
使用孪生网络来进行图像质量评估排名学习,孪生网络是有两个相同的分支网络,和一个损失函数。两个分支网络共享权重(在实际的训练中可以认为是相同的网络,只用实现一个即可)。图像对 (Pairs of images )和标签(labels)是输入,产生两个输出传递给损失函数。损失函数与所有模型参数的梯度通过随机梯度下降来向后传播并计算。
具体来说,如果将图像 x 作为网络输入,以 f(x; θ)表示输出。这里θ是网络参数,用y来表示图像的标签真实值。本文希望f(x; θ)输出值能指示图像质量。
\[L\left(x_{1}, x_{2} ; \theta\right)=\max \left(0, f\left(x_{2} ; \theta\right)-f\left(x_{1} ; \theta\right)+\varepsilon\right)
\]
ε是边缘。本文假设x1的排名高于x2。
当网络的结果与排名一致时,梯度为零。
当网络的结果不一致时,我们降低较高的梯度并添加较低分数的梯度。
给定L关于模型参数θ的梯度,可以使用随机梯度下降(SGD)训练孪生网络。
\[\nabla_{\theta} L=\left\{\begin{array}{lr}
0 & \text { if } f\left(x_{2} ; \theta\right)-f\left(x_{1} ; \theta\right)+\varepsilon \leq 0 \\
\nabla_{\theta} f\left(x_{2} ; \theta\right)-\nabla_{\theta} f\left(x_{1} ; \theta\right) & \text { otherwise }
\end{array}\right.
\]
3.3 高效的孪生网络向后传播方法
后续更新…
3.4 微调到NR-IQA任务中
训练一个孪生对失真图像进行排序后,再从网络中提取单个分支进行微调。给定带有主观标注的的小批量M幅图像,将第i幅图像的真值质量分数记为\(y_i\),从网络中预测的分数记为\(\hat{y}_{i}\)。用平方欧氏距离(squared Euclidean distance)作为损失函数对网络进行微调,代替孪生网络中使用的排名损失:
\[L\left(y_{i}, \hat{y}_{i}\right)=\frac{1}{M} \sum_{i=1}^{M}\left(y_{i}-\hat{y}_{i}\right)^{2}
\]
4. Experimental results
4.1 数据集
IQA数据集。
LIVE [28]包含从29张原始图像生成的808张图像,这些图像通过五种畸变进行失真:高斯模糊(GB),高斯噪声(GN),JPEG压缩(JPEG),JPEG2000压缩(JP2K)和快速衰落( FF)。
TID2013[22]数据集由25张参考图像和3000种来自24种不同失真类型的失真图像组成。
用于生成排名对的数据集。
为了在LIVE数据库上进行测试,我们生成了四种类型的失真,这些失真被广泛使用和常见:GB,GN,JPEG和JP2K。
为了在TID2013上进行测试,我们在总共24种失真中生成了17种(除了#3,#4,\#12,#13,#20,#21,#24)。
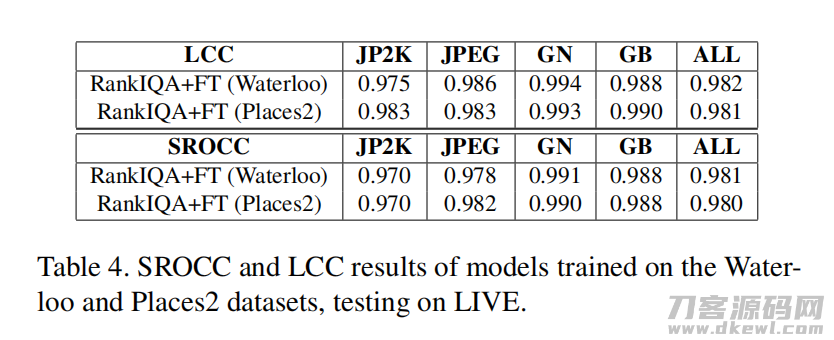
滑铁卢数据集包含从互联网上精心挑选的4,744张高质量自然图像。使用此数据集的目的是证明可以使用并非专门为IQA问题设计的数据集来学习高质量的排名嵌入。
4.2 实验标准
Network architectures.
浅层网络具有四个卷积层和一个完全连接的层。 对于AlexNet和VGG-16,仅更改输出数量,目标是为每个失真的图像输出一个分数。
Strategy for training and testing.
从原始的高分辨率图像中随机采样子图像。这样做而不是缩放,以避免引入由插值或滤波引起的失真。
采样图像的大小由每个网络确定。但是,输入图像的大尺寸很重要,因为输入子图像应至少为原始图像的1/3,以便捕获上下文信息。
在训练期间,从每个时期的每个训练图像中采样单个子图像。
In our experiments, we sample \(227 \times 227\) and \(224 \times 224\) pixel images, depending on the network. We use the Caffe framework and train using mini-batch Stochastic Gradient Descent (SGD) with an initial learning rate of \(1 \mathrm{e}-4\) for efficient Siamese network training and \(1 \mathrm{e}-6\) for fine-tuning. Training rates are decreased by a factor of \(0.1\) every \(10 \mathrm{~K}\) iterations for a total of \(50 \mathrm{~K}\) iterations. For both training phases we use \(\ell_{2}\) weight decay (weight 5e-4).
测试时,从原始图像中随机抽取了30个子图像。子区域的输出平均值是每个图像的最终分数。
Evaluation protocols.
使用LCC(算法预测的准确性)和SROCC(算法预测的单调性)进行算法评估。
4.3 从排名中学习NR-IQA(细节)
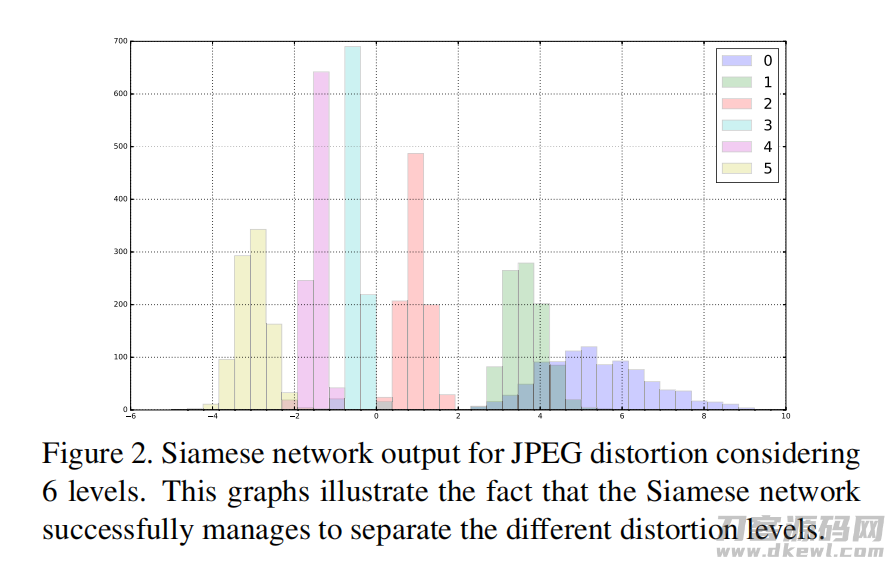
Siamese networks and IQA discrimination.
为了展示排名网络区分图像质量的能力,在Places2验证集(未对IQA数据应用微调)上训练了孪生网络,该验证集被分为了五个级别的单个失真。即使两个数据集的采集过程和场景完全不同,该模型也可以区分滑铁卢上不同程度的失真。
Effificient Siamese backpropagation.
本实验的目的是评估我们的暹罗反向传播方法的效率。
Network performance analysis.
\[\begin{array}{c|ccc}
\hline & \text { Shallow } & \text { AlexNet } & \text { VGG-16 } \\
\hline \text { LCC } & 0.930 & 0.945 & 0.973 \\
\text { SROCC } & 0.937 & 0.949 & 0.974 \\
\hline
\end{array}
\]
从排名中学习可以有效地训练非常深的网络而不会过度拟合。
这些结果是通过从头开始进行训练而获得的,但是使用ImageNet上预先训练的网络初始化权重可以进一步改善结果。因此,在其余的实验中,将使用预先训练的权重初始化的VGG16网络。
Baseline performance analysis.
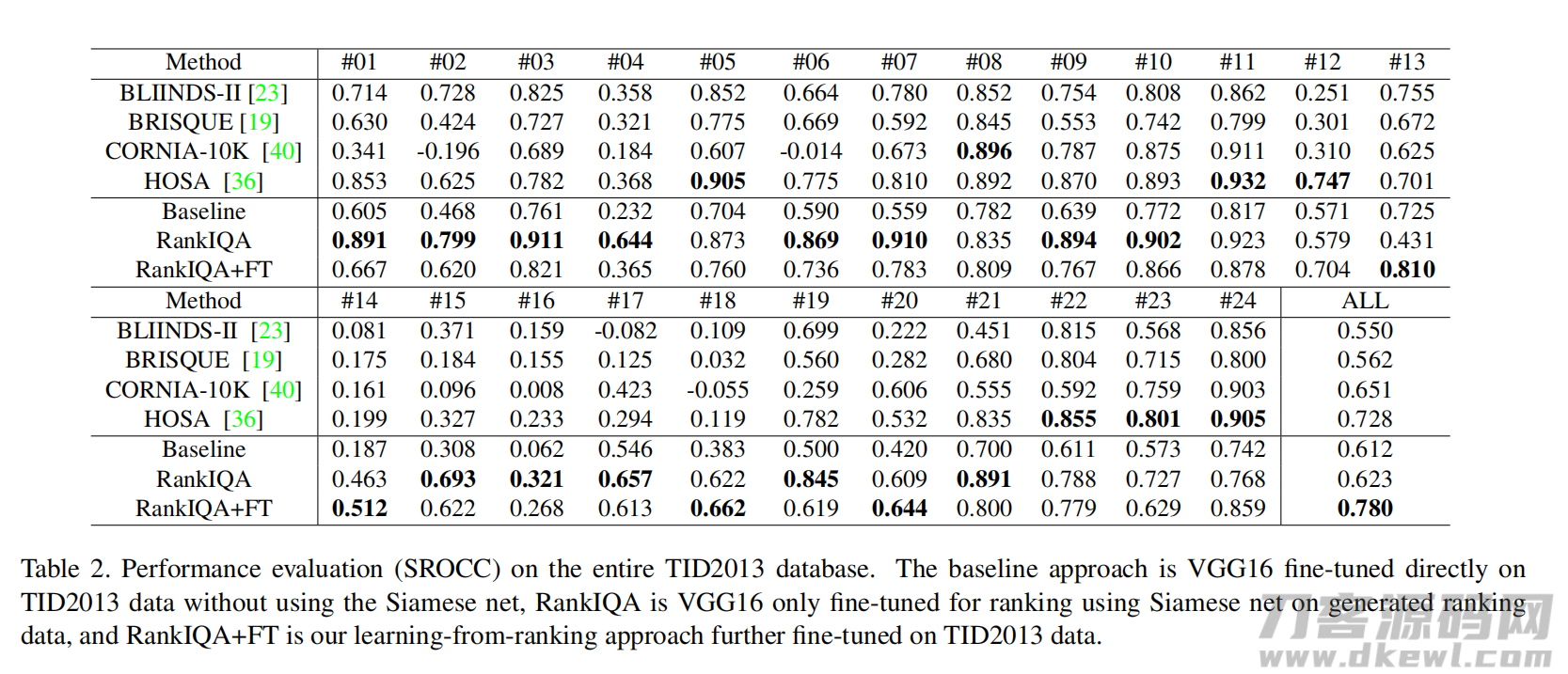
4.4 与最新技术比较
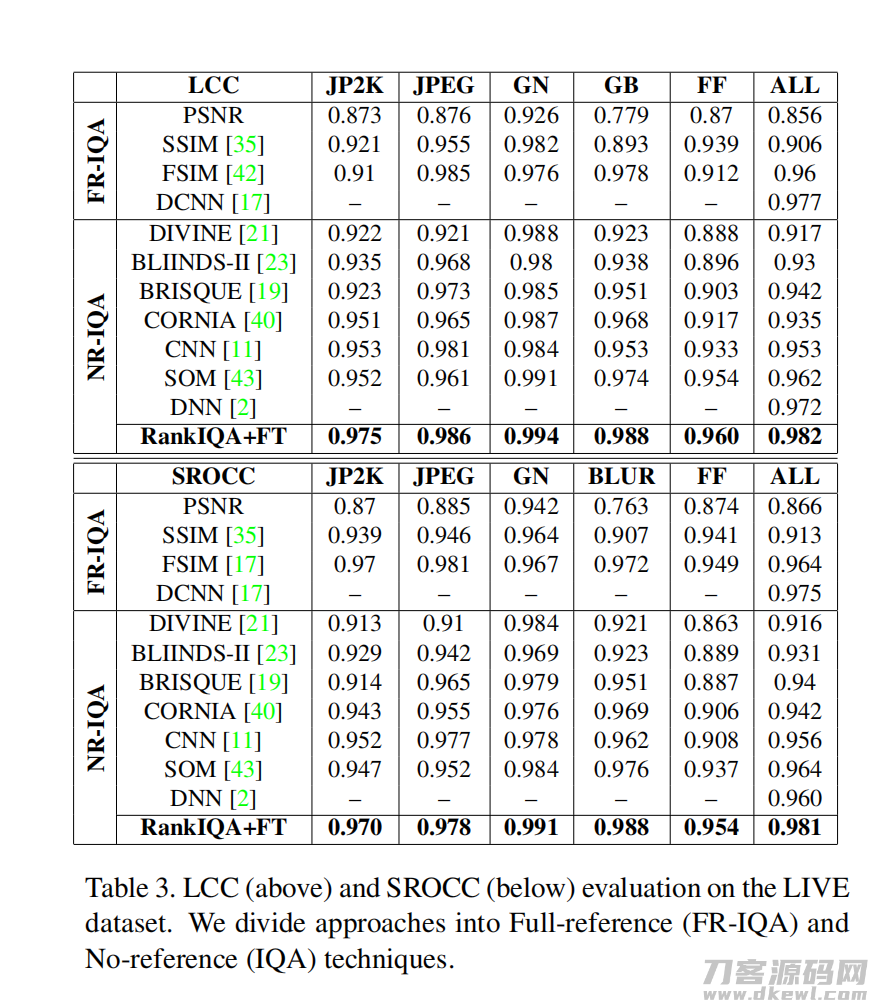
4.5 从IQA数据集上独立(算法泛化性)
5. Conclusions
和摘要一样,不看了!(不会有人周六还在看论文吧…)
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0