摘要
最近要做一个邮件分类的工作,需要用到SVM的垃圾邮件分类模型。看到一篇博客(https://blog.csdn.net/qq_40186809/article/details/88354825),灵感涌现,决定用trec07c这个垃圾邮件词库(https://plg.uwaterloo.ca/~gvcormac/treccorpus06/)来训练模型。期待这个模型能够帮我轻松解决这个问题。
正文
一. 序言
因为近期有一个电子邮件归类的工作中必须进行,科学研究了一下根据SVM的垃圾短信分类模型。参考这名创作者的构思(https://blog.csdn.net/qq_40186809/article/details/88354825),应用trec07c这一公布的垃圾短信词库(https://plg.uwaterloo.ca/~gvcormac/treccorpus06/)做为数据信息开展模型。并对编码开展提升,提高训炼速率。
工作中全过程以下:
1,数据预处理,获取每一封电子邮件的內容,开展词性标注,数据预处理。
2,选择特点,将电子邮件內容变换为矩阵的特征值。
3,应用sklearn创建SVM实体模型。
4,编码调节及提升。
二.数据预处理
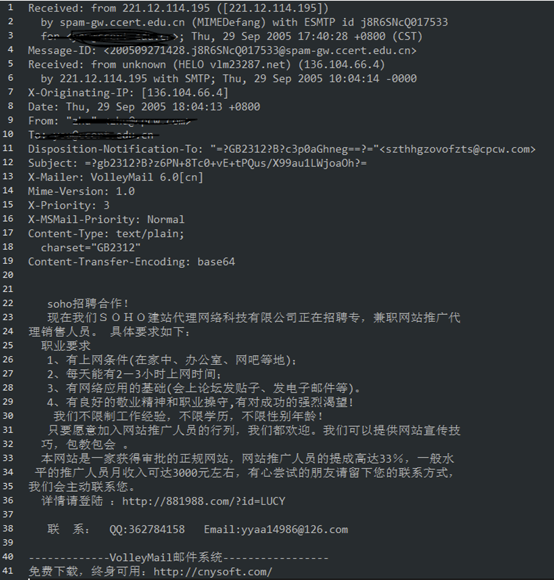
trec07c这一数据的数据信息较为独特,由215个文件夹名称构成,每一个文件夹名称下边包括300个编号为GBK的电子邮件文档,都为初始电子邮件数据信息。共21766个正样版,42854个负样版,其样版的正负极性由文件夹名称下的index文档所标志。下边便是一个垃圾短信(负样版)的实例:
最先依照自身的必须,将index文档开展解决,操纵正负极样版的总数占比差不多,获得新的数据库索引文档CN_index_ham、CN_index_spam,其內容为电子邮件的相对位置数据库索引: 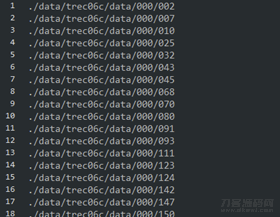
历经观查,各电子邮件文档的上半部分成其收取和发送、通讯的基本资料,后半一部分才算是电子邮件的主要内容,两一部分中间以一个空白行开展间距。因而电子邮件预备处理的构思为按行载入全部电子邮件,检索其第一个空白行,并将该空白行以后的每一行內容开展纪录、词性标注、挑选停用词等实际操作。
在预备处理全过程中还需处理下列两个小问题:
①编号难题,尽管说文档明确是GBK编码格式,但仍有一部分稀奇古怪的标识符没法恰当编解码,因而应用try实际操作将readline()实际操作开展包囊,碰到编号有什么问题的內容立即载入下一行。
②因为难题①应用try实际操作,在except中立即continue,促使在载入电子邮件內容时,假如电子邮件最终一行的编号有什么问题,立即continue进到下一次循环系统,而下一次循环系统已到文档结尾,沒有物品可读,程序流程会不断开展readline()实际操作并跳进except,深陷不断循环。为处理这个问题,设定一个tag,在每开展一次except实际操作时,将此tag = 1,假如持续循环系统20次仍无新內容读取,则完毕文档载入。
该一部分编码以下。
1 #coding:utf-8 2 import jieba 3 import pandas as pd 4 import numpy as np 5 6 from sklearn.feature_extraction.text import CountVectorizer 7 from sklearn.svm import SVC 8 from sklearn.model_selection import train_test_split 9 from sklearn.externals import joblib 10 11 path_list_spam = [] 12 with open('./data/CN_index_spam','r',encoding='utf-8') as fin: 13 for line in fin.readlines(): 14 path_list_spam.append(line.strip()) 15 16 path_list_ham = [] 17 with open('./data/CN_index_ham','r',encoding='utf-8') as fin: 18 for line in fin.readlines(): 19 path_list_ham.append(line.strip()) 20 21 stopWords = [] 22 with open('./data/CN_stopWord','r',encoding='utf-8') as fin: 23 for i in fin.readlines(): 24 stopWords.append(i.strip()) 25 26 # 界定一些超参数 27 MAX_EMAIL_LENGTH = 200 #最多电子邮件长短 28 THRESHOLD = len(path_list_ham)/50 # 超出那么数次的语汇,当选dict 29 30 path_list_spam = path_list_spam[:5000] # 将正例、负例样版取非空子集,先各取5000个做测验 31 path_list_ham = path_list_ham[:5000] 32 # 下边界定标值类字符串数组检验函数 ,预备处理时必须将标值信息内容清理掉 33 def is_number(s): 34 try: 35 float(s) 36 return True 37 except ValueError: 38 pass 39 try: 40 import unicodedata 41 unicodedata.numeric(s) 42 return True 43 except (TypeError, ValueError): 44 pass 45 return False
上边编码完成了载入正例、负例样版编码序列,载入停用词-stopword的工作中。而且界定了2个超参数,MAX_EMAIL_LENGTH为电子邮件载入语汇最烂长短,这儿设为200,防止载入到2/3每千字的较长电子邮件,占有过大运行内存;THRESHOLD是特征词当选阀值,如当THRESHOLD=20时,某一语汇在超出20封电子邮件中发生过,则将它列入特征词之一。界定is_number()涵数来分辨某一字符串数组是不是为数据,便于于将其清理出来。
1 def email_cut(path_list): 2 emali_str_list = [] 3 for i in range(len(path_list)): 4 print('====== ',i,' =======') 5 print(path_list[i]) 6 with open(path_list[i],'r',encoding='gbk') as fin: 7 words = [] 8 begin_tag = 0 9 wrong_tag = 0 10 while(True): 11 if wrong_tag > 20 or len(words)>MAX_EMAIL_LENGTH: 12 break 13 try: 14 line = fin.readline() 15 wrong_tag = 0 16 except: 17 wrong_tag = 1 18 continue 19 if (not line): 20 break 21 if(begin_tag == 0): 22 if(line=='\n'): 23 begin_tag = 1 24 continue 25 else: 26 l = jieba.cut(line.strip()) 27 ll = list(l) 28 for word in ll: 29 if word not in stopWords and word != '\n' and word != '\t' and word != ' ' and not is_number(word): # 30 words.append(word) 31 if len(words)>MAX_EMAIL_LENGTH: # 一封email较大 英语词汇量设定 32 break 33 wordStr = ' '.join(words) 34 emali_str_list.append(wordStr) 35 return emali_str_list
上边涵数email_cut() 的键入主要参数为 path_list_ham 及其 path_list_spam,该涵数依据这种电子邮件的path详细地址,将其信息内容按行开展载入,并应用jieba开展词性标注,清理掉转义字符及其标值类字符串数组,最后将全部电子邮件的数据信息存进 emali_str_list 开展回到。
三.特点选择
在这里一步中,应用 sklearn 中的 CountVectorizer 类輔助。统计分析全部电子邮件数据信息中发生的语汇,并对这种语汇开展挑选,选发生频次出超过 THRESHOLD 的一部分,构成词汇,并对电子邮件文字数据信息开展变换,以空间向量方式表明。
1 def textToMatrix(text): 2 cv = CountVectorizer() 3 cv.fit(text) 4 vocabulary = cv.vocabulary_ 5 vector = cv.transform(text) 6 result = pd.DataFrame(vector.toarray()) 7 del(vector) # 立即删掉以节约存储空间 8 features = []# 存储矩阵的特征值 9 for key, value in vocabulary.items(): # key, value 实例 '孟子', 23772 即 语汇,字符串数组 的方式 10 if result[value].sum() >= THRESHOLD: 11 features.append(key) # 添加词汇 12 result.rename(columns={value:key}, inplace=True) # 原本的字段名是数据库索引值value,如今改为key ('孟子'、'后代'、'故乡' ..等语汇) 13 return result[features] # 减缩特点引流矩阵经营规模,仅将特点词汇中的列留有
在上边涵数中,应用CountVectorizer()将电子邮件內容(即包括n条字符串数组的List,每一个字符串数组意味着一封电子邮件)开展统计分析,获得语汇目录,并将电子邮件內容开展变换,转化成一个稀疏矩阵,该电子邮件沒有发生过的语汇数据库索引下边相匹配的数值0,发生过的语汇数据库索引下边相匹配的数值本词在本电子邮件中发生过的频次。在for循环中,查询语汇在全部电子邮件中发生的频次是不是超过THRESHOLD ,如超过,则将该部位的列首数据库索引更换为该语汇自身(key为语汇,value为词句自身),最终对大的电子邮件特点引流矩阵开展精减,仅留有特征词隶属的列开展回到。最后回到的結果大约是下边这类款式:
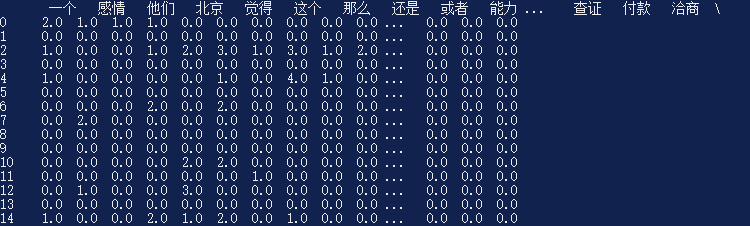
最上边一行汉语词汇为特点语汇,下边每一行数据信息意味着一封Email的內容,其标值意味着相匹配语汇在这个Email中的发生频次。能够看得出,SVM不可以对句子的次序关联开展学习培训,不一样的Email內容很有可能相匹配着一样的矩阵的特征值結果。比如:“我要吃大苹果” 与“吃水果要想大我” 相匹配的矩阵的特征值是一模一样的。但是一般来讲问题不大,终究研表究明,中国汉字的序顺并不可以影阅响读嘛。
四.创建SVM实体模型
最终,应用sklearn的SVC控制模块对全部电子邮件的矩阵的特征值开展模型训炼。
1 ham_str_all = email_cut(path_list_ham) 2 spam_str_all = email_cut(path_list_spam) 3 allWord = [] 4 allWord.extend(ham_str_all) 5 allWord.extend(spam_str_all) 6 labels = []#标识 7 labels.extend(np.ones(len(path_list_ham))) 8 labels.extend(np.zeros(len(path_list_spam))) 9 vector = textToMatrix(allWord)#获得矩阵的特征值 10 print(vector) 11 feature = list(vector.columns) 12 print("feature length: ",len(feature)) 13 with open('./model/CN_features.txt', 'w', encoding="UTF-8") as f: 14 s = ' '.join(feature) 15 f.write(s) 16 svm = SVC(kernel='linear', C=0.5, random_state=0) # 线形核,C的值较钟头能够容许一些不正确 可选择核: 'linear', 'poly', 'rbf', 'sigmoid', 'precomputed' 17 # 将数据信息分为检测集和训练集 18 X_train, X_test, y_train, y_test = train_test_split(vector, labels, test_size=0.3, random_state=0) 19 svm.fit(X_train, y_train) 20 print(svm.score(X_test, y_test)) 21 model = joblib.dump(svm,'./model/svm_model.m')
最先是载入正例电子邮件和典例电子邮件,并转化成其相匹配的label编码序列,将电子邮件转换为由矩阵的特征值构成的matrix(在本例中,特点语汇恰好有256个,换句话说矩阵的特征值的层面为256),储存特点语汇,应用SVC控制模块创建SVM实体模型,分离出来训练集与检测集,线性拟合训炼,对检测集开展测算得分后储存实体模型。
五.编码调节及提升
全部实践活动模型的全过程实际上到上边早已告一段落,但在具体应用的全过程中,发觉有下边两个难题。
①训炼速率超慢,5000个正样版 5000个负样版必须训炼两个钟头。这彻底并不是svm的训炼速率,只是神经元网络的训炼速率了。在参照的那篇blog中,创作者(Ning_wxh)也提及,他的设备只有各取600个正样版/反样版开展训炼,再多设备就受不了。
②运行内存耗费很大,我电脑上16GB的运行内存都被布满,不断的从虚拟内存设置中开展数据传输。下面的图内存占用图上,周期时间型的锯齿形起伏说明了实体线内存有与虚拟内存设置作互换。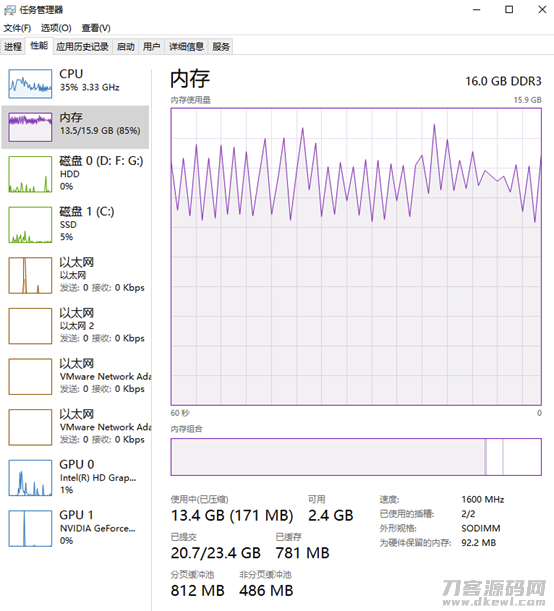
先说第②个难题。这个问题根据设定 MAX_EMAIL_LENGTH(电子邮件较大 语汇数量) 和 提升 THRESHOLD 的值来完成的。设定电子邮件较大 语汇数量为200,防止将好几千字的Email內容所有读取;而最初的THRESHOLD值设定为10,最后的矩阵的特征值层面为900 ,矩阵的特征值过度稀少,便将THRESHOLD设定为样版数量的50分之1,即100,将层面降为256。除此之外在textToMatrix()涵数中,将vector自变量立即删掉,清空内存花销。这3个流程,在正/负样版总数都为5000时,将运行内存耗费操纵在10GB下列。
再聊第①个难题。历经不断的ps钢笔调节,发觉時间耗费较大 的一步句子是textToMatrix()涵数中的: result.rename(columns={value:key}, inplace=True) 句子。这条句子的意思是将pd.DataFrame的某列字段名开展更换,由value更换为key。因为大家的初始语汇较多,造成 有40000两列数据信息,精准定位value列的全过程花销很大,造成 很大的時间花销。缘故早已寻找,处理这个问题的构思由2个:一是对字段名搭建数据库索引,便于迅速精准定位;二是再次搭建一个新的pd.DataFrame数据分析表,将更名实际操作大批量开展。
这儿挑选第二种构思,便是室内空间换時间嘛,调用textToMatrix()涵数以下:
1 def textToMatrix(text): 2 cv = CountVectorizer() 3 cv.fit(text) 4 vocabulary = cv.vocabulary_ 5 vector = cv.transform(text) 6 result = pd.DataFrame(vector.toarray()) 7 del(vector) 8 features = []# 存储矩阵的特征值 9 origin_data = np.zeros((len(result),1)) # 新创建的数据分析表 10 for key, value in vocabulary.items(): 11 if result[value].sum() >= THRESHOLD: 12 features.append(key) 13 origin_data = np.column_stack((origin_data,np.array(result[value]))) # 按列层叠到新数据分析表 14 origin_data = origin_data[:,1:] # 删除复位的第一列全0数据信息 15 print('origin_data shape: ',origin_data.shape) 16 origin_data = pd.DataFrame(origin_data) # 变换为DataFrame目标 17 origin_data.columns = features # 批量修改字段名 18 print('features length: ',len(features)) 19 return origin_data
最后,仅用时2分钟便进行SVM实体模型的训炼,比提升编码以前速率提升了60倍。在检测集在的预测分析精密度为0.93666,即93.6%的准确度,也算作较为好用了。
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0