摘要
RNN做翻译机器有缺陷,但Attention能解决。了解Attention需要知道两件事:RNN的缺陷和Attention的奇妙之处。让我们一起探索吧!
正文
RNN做翻译机器有它本身的缺点,Attention恰好是为了更好地摆脱这一缺点而发生的。因此,要了解Attention,就要搞搞清楚2件事:
-
RNN在做翻译机器时有哪些缺点
-
Attention是怎样摆脱这一缺点的
文中尝试从解释这两个难题的视角来了解Attention体制。
- 一、RNN做翻译机器的經典构思 encoder-decoder
- 二、encoder-decoder的缺陷在哪儿?
- 三、Attention是怎样运用正中间的輸出的
- 四、Attention中造成概率分布函数的二种方式
- 五、Attention体制的拓展
- 六、汇总
一、RNN做翻译机器的經典构思 encoder-decoder
用RNN做翻译机器时,一般 必须 2个RNN互联网,一个用于将接受待汉语翻译句子,对其开展编号,最终輸出一个vector,这一互联网叫encoder。随后,该vector会做为键入,发送给另一个RNN互联网,该互联网用于依据vector造成目标语言的汉语翻译句子,这一互联网称为decoder。如下图所显示:
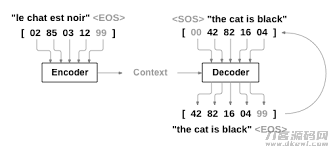
图中正中间的Context便是大家这儿说的第一个RNN造成的vector。
二、encoder-decoder的缺陷在哪儿?
encoder-decoder较大 的缺陷是,encoder接受了无论多久的句子,最终輸出的仅仅最后一个vector,当句子较长时,这一vector能不能合理地表明该句子是很非常值得猜疑的。
如何解决这个问题呢?大家很当然会想起,第一个RNN实际上 在中间会造成许多輸出,这种輸出都被大家抛下了,大家仅用了最终的一个。假如能运用上正中间的輸出,可能能够 解决困难。Attention恰好是运用上这种正中间的輸出。
三、Attention是怎样运用正中间的輸出的
先图中,再去表述:
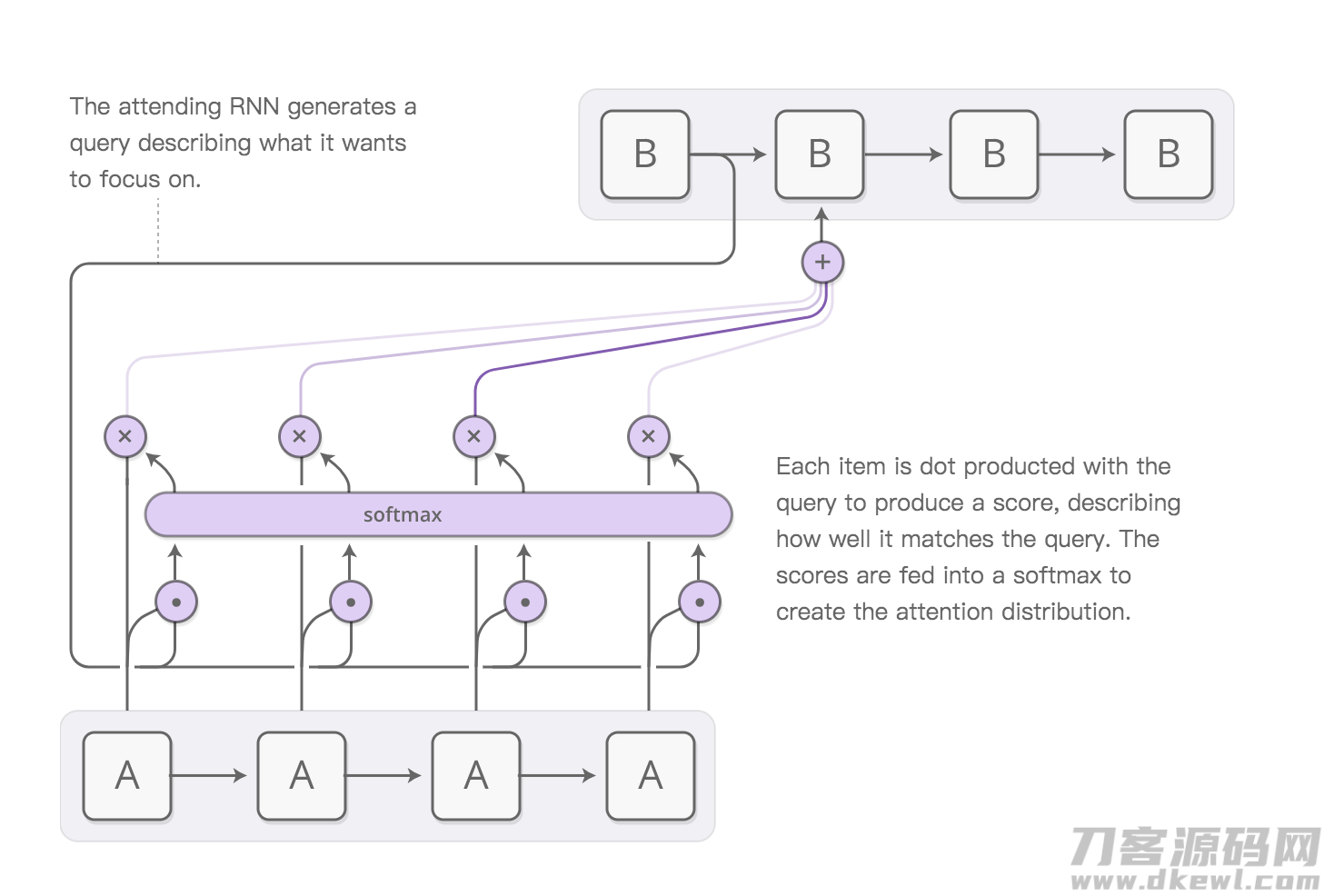
图中中的A是大家的encoder, B是大家的decoder。
能够 想像,A互联网接受了一个四个字的语句,对每一个字都造成了一个輸出(这种輸出全是一个vector),大家称其为s1,s2,s3,s4。
大家看图中的B互联网,在第一个B造成的hidden state(称其为h1)除开发送给下一个cell外,还传入了A互联网,这儿便是Attention充分发挥的地区,大家一起来看看发生什么事。
第一步:
h1 各自与s1,s2,s3,s4做点积,造成了四个数,称其为m1,m2,m3,m4(这种全是标量,并不是空间向量了!)
第二步:
m1,m2,m3,m4 传入一个softmax层,造成一个概率分布函数a1,a2,a3, a4。
第三步:
将a1,a2,a3, a4 与s1,s2,s3,s四分别乘积,再求和,获得获得一个vector,称其为Attention vector。
第四步:
Attention vector 将做为键入传入B互联网的第二个cell中,参加预测分析。
之上便是Attention体制的基本上观念了。大家见到,Attention vector 事实上结合了s1,s2,s3,s4的信息内容,实际的结合是用一个概率分布函数来做到的,而这一概率分布函数也是根据B互联网上一个cell的hidden state与s1,s2,s3,s4开展点乘获得的。
Attention vector事实上做到了让B互联网对焦于A互联网輸出的某一部分的功效。
四、Attention中造成概率分布函数的二种方式
在第三一部分中,大家的概率分布函数来自于h与s的点积再做softmax,这仅仅最基本上的方法。在具体中,我们可以有不一样的方式来造成这一概率分布函数,每一种方式都意味着了一种实际的Attention体制。
-
1 加减法Attention
在加减法Attention中,大家不会再让h与s做点积,只是做以下的计算: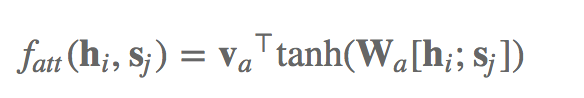
va和Wa全是能够 训炼的主要参数。h与s中间的分号表明将二者收到一起造成一个更长的vector。那样造成的数再送到softmax层,从而造成一个概率分布函数。
自然,大家还能够那么做:
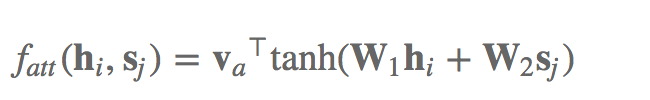
这儿仅仅不会再把h与s收到一起罢了,实质上没什么差别的。
-
2 加法Attention
加法Attention将h与s做以下的计算: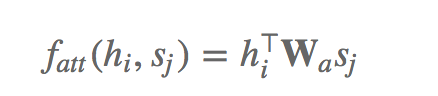
显而易见,加法Attention的主要参数更少,高效率当然也会高些一些。
五、Attention体制的拓展
Attention体制的关键取决于对一个编码序列数据信息开展对焦,这一对焦是根据一个概率分布函数来完成的。这类体制实际上 有较强的普遍意义,可以用在各个领域。
例如,依据照片造成叙述该照片的文本, 最先,照片会历经CNN开展特点的获取,获取的数据信息会键入到造成叙述文本的RNN中,这儿,我们可以引进Attention体制,使我们在造成下一个文本时,对焦于大家已经叙述的照片位置。
次之,在语句表明中,self Attention体制是取得成功拓展的Attention的案例。其基本概念以下:
倘若大家用一个RNN读取了一个语句,造成了h1, h2,h3,h4四个hidden state。
为了更好地获得该语句的引言,我们可以那样做:
对每一个h测算一个成绩:
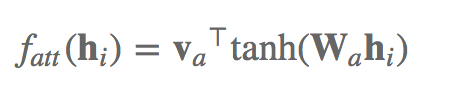
四个h共造成了4个成绩,将这四个成绩送进一个softmax层,造成一个概率分布函数,依据这一概率分布函数对四个h开展加和,获得语句引言的第一个vector。如下图所显示:
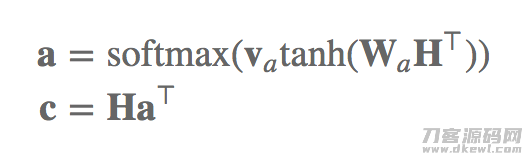
为了更好地获得大量的vector,我们可以把上边图上的小写字母va换为一个引流矩阵,随后,大家的a也就变成了好几个概率分布函数构成的引流矩阵,每一个概率分布函数都能够用于与h开展加和造成一个vector,那样大家就造成了引言的好几个vector,如下图所显示:
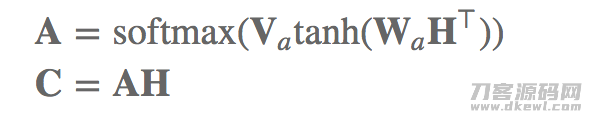
六、汇总
根据之上的內容,大家掌握到,Attention体制最开始用于摆脱RNN做翻译机器时的缺陷,随后,大家发觉,Attention体制具备普遍的适用范围,因此它又被拓展到造成照片叙述,做语句引言等每日任务上。
大家也清晰了,不一样的Attention体制的关键差别取决于造成概率分布函数的方式不一样。
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0