摘要
Horovod是一款神奇的分布式训练工具,它能让你的深度神经网络在多台机器上飞速训练。今天我们要介绍的是kubeflow tf-operator,它是Horovod的好搭档,让你的训练更加高效、稳定。让我们一起来探索吧!
正文
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (18) — kubeflow tf-operator
- [源代码分析] 深度神经网络分布式系统训炼架构 horovod (18) — kubeflow tf-operator
- 0x00 引言
- 0x01 情况专业知识
- 1.1 Kubernetes
- 1.2 器皿做为生产调度模块
- 1.3 Kubeflow
- 1.4 Tensorflow on Kubeflow
- 1.5 Operator
- 1.6 TF-Operator
- 0x02 TensorFlow 分布式系统
- 2.1 Parameter server构架
- 2.2 Tensorflow PS-Worker
- 2.2.1 构架
- 2.2.2 编码
- 0x03 TF-Operator
- 3.1 TF-Operator 设计理念
- 3.2 框架图
- 3.2.1 什么叫Pod
- 3.2.2 为何要有 service
- 3.2.3 什么叫 controller
- 3.3 Spec
- 3.4 TFJob
- 3.5 人物角色
- 3.5.1 界定
- 3.5.2 建立人物角色
- 3.5.3 如何区分 master
- 0x04 Contoller
- 4.1 K8S CRD重要定义
- 4.2 界定
- 4.3 通道
- 4.4 syncHandler
- 4.5 ReconcileJobs
- 4.6 解决 Pod
- 4.6.1 ReconcilePods
- 4.6.2 createNewPod
- 4.6.3 转化成配备信息内容
- 4.6.3.1 SetClusterSpec
- 4.6.3.2 genTFConfigJSONStr
- 4.6.3.3 genClusterSpec
- 4.6.4 CreatePodsWithControllerRef
- 4.6.5 createPods
- 4.7 解决服务项目
- 4.7.1 ReconcileServices
- 4.7.2 CreateNewService
- 4.7.3 CreateServicesWithControllerRef
- 4.7.4 createServices
- 0x05 与一般布署较为
- 5.1 运作
- 5.2 较为
- 5.2.1 一般 TF
- 5.2.2 TF-Operator
- 0x06 汇总
- 0xEE 私人信息
- 0xFF 参照
0x00 引言
Horovod 是一款根据 AllReduce 的分布式系统训炼架构。凭着其对 TensorFlow、PyTorch 等流行深度神经网络架构的适用,及其通讯提升等特性,Horovod 被广泛运用于数据信息并行处理的训炼中。
前边根据十几篇文章内容,大家一步一步剖析了 Horovod 的各个方面。下面便是应对 Horovod on K8S 这座高山。
文中及其后2~3篇文章内容目地是:趁着剖析学习培训 Horovod on K8S 作用,把有关定义整理一遍,期待能够 从这当中找到设计理念。因此成小短文方法是:梳理学了许多在网上文章内容,随后自身剖析编码。专此对诸位创作者深表谢谢。
文中是 horovod on k8s 的餐前甜品和必不可少前提条件,详细介绍有关定义及其kubeflow 小区的 tf-operator。
本系列产品别的文章内容连接以下:
[源代码分析] 深度神经网络分布式系统训炼架构 Horovod (1) — 基本知识
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (2) — 从使用人视角进入
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (3) — Horovodrun身后干了哪些
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (4) — 网络基础知识 & Driver
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (5) — 结合架构
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (6) — 后台管理进程构架
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (7) — DistributedOptimizer
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (8) — on spark
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (9) — 运行 on spark
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (10) — run on spark
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (11) — on spark — GLOO 计划方案
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (12) — 延展性训炼整体构架
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (13) — 延展性训炼之 Driver
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (14) — 延展性训炼发觉连接点 & State
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (15) — 广播节目 & 通告
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (16) — 延展性训炼之Worker生命期
[源代码分析] 深度神经网络分布式系统训炼架构 horovod (17) — 延展性训炼之容错机制
0x01 情况专业知识
1.1 Kubernetes
kubernetes,通称K8s,是用8替代八个标识符“ubernete”而成的简称。是一个开源系统的,用以管理云平台中好几个服务器上的容器化的运用,Kubernetes的总体目标是让布署容器化的运用简易而且高效率(powerful),Kubernetes给予了运用布署,整体规划,升级,维护保养的一种体制。
Kubernetes 是一种愈来愈受大家喜爱的深层神经元网络训炼选择项,因为它给予了根据器皿应用不一样深度学习架构的协调能力,及其按需拓展的灵敏性。
当遭遇较繁杂的实体模型训炼或是信息量大时,单机版的计算水平通常不能满足算率规定。根据应用阿里巴巴的 AiACC 或是小区的 horovod 等分布式系统训炼架构,仅需改动两行编码,就能将一个单机版的训练科目拓展为适用分布式系统的训练科目。
在 Kubernetes 上普遍的是 kubeflow 小区的 tf-operator 适用 Tensorflow PS 方式,或是 mpi-operator 适用 horovod 的 mpi allreduce 方式。
1.2 器皿做为生产调度模块
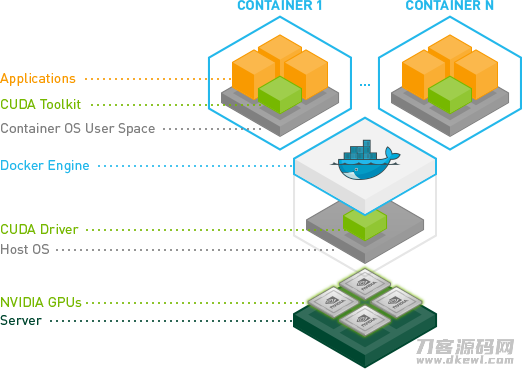
为何期待应用器皿来做为深度神经网络系统软件的生产调度模块?由于器皿获取/运行迅速。防护資源效果非常的好。抽象性看来,能够 将器皿的image做为job的一部分派发生产调度实行。自然容器化后会引进gpu,互联网等特性的成本。
例如 nvidia gpu 对docker给予了适用,nvidia-docker能够 替代docker实行create和run实际操作。下面的图便是nvidia-docker构架。
1.3 Kubeflow
Kubeflow 是一个开源系统的 Kubernetes 原生态服务平台,用以开发设计、编辑、布署和运作可拓展的携带式深度学习工作中负荷。Kubeflow 能够 在一切Kubernetes 群集上运作。
Kubeflow能够 非常好的管理方法多机每日任务,Kubeflow的名称非常简单,为Kubernetes TensorFlow,是一个深度学习工具箱,是运作在K8s以上的一套技术栈,这套技术栈包括了许多部件,部件中间的关联较为疏松,我们可以配合起来用,还可以独立用在其中的一部分。
Kubeflow 了解 Kubernetes 计划指标哪多台设备来运作一个分布式系统工作中的每个过程,接着告 知每一个过程,全部别的过程的 IP 详细地址和 port。进而确保一个工作里每个过程 中间相互之间了解另一方。
为何必须 让全部过程相互之间了解另一方呢?它是 TensorFlow ps-based distribution 方法规定的。TensorFlow 1.x 原生态的遍布 式训炼作用让一个工作中全部过程都实行 TensorFlow 1.x runtime 程序流程。这种 过程相互之间通讯,相互之间融洽变成一个“分布式系统 runtime“,来表述实行表明深度神经网络 测算全过程的计算图(graph)。在逐渐分布式系统训炼之初,graph 被 TensorFlow runtime 拆卸成多个子图;每一个过程承担实行一个子图 —— 一切一个过程不成功 (可能是被高些优先工作占领),则全部高清大图的实行就失败了。因此 TensorFlow 原生态的分布式系统训炼工作能力并不是容错机制的(fault-tolerant)。但是, 它是能够 从不正确修复(fault-recoverable)—— TensorFlow API 给予 checkpoint 的工作能力;假如一个工作失败了,能够 重新启动工作,从近期的 checkpoint 逐渐执行。
1.4 Tensorflow on Kubeflow
Kubeflow 适用二种不一样的 Tensorflow 架构分布式系统训练法。
- 第一种是原生态 Tensorflow 构架,它取决于集中型主要参数网络服务器来完成工作中进程中间的融洽。
- 第二种是分散型方式,工作中进程根据 MPI AllReduce 原语立即互相通讯,不应用主要参数网络服务器。NVIDIA 的 NCCL 库早已在GPU 上合理地实行了绝大多数 MPI 原语,而 Uber 的Horovod 让应用 TensorFlow 实行多 GPU 和多节点训炼越来越易如反掌。与主要参数网络服务器对比,第二种方式能够 能够更好地提升网络带宽和能够更好地拓展。
1.5 Operator
Operator 是Kubernetes 当中的定义,主要是用于装包、布署及管理方法客户的每日任务。
Operator能够 简易了解为 CRD Controller。
- CRD(Custom Resource Definition)是 Kubernetes 的拓展种类,用于为客户自定資源提。
- Controller 用于让客户实际操作CRD。
假如用 Java 来形容,operator 便是 Class,CRD 便是类的成员函数,Controller 便是类组员方式。
1.6 TF-Operator
尽管KubeFlow给予了一大堆部件,包含了深度学习的各个方面,但实体模型训炼肯定是KubeFlow最重要的作用。 KubeFlow对于各式各样的深度学习架构给予了训炼的工作能力。方法是界定了各式各样的Operator,其主要是用于管理方法深度学习或是深度神经网络里边的每日任务,例如怎么管理维护保养一个每日任务的好几个连接点,怎么管理Pod及每日任务的生命期,怎样开展容错机制这些。
TF-Operator便是开源项目根据K8S给予的拓展API,给予了TensorFlow的训炼工作能力,从名称也可以看出去,这一完成是相近Job的一种方法,其特性以下:
- 给予TensorFlow原生态PS-worker构架 的多机训炼
- 强烈推荐将PS和worker一起运行
- 根据service做服务发现
- 在小区中最初期的Operator
由于 TF-Operator 是小区中最初期的Operator,因此大家必须先看一下。
0x02 TensorFlow 分布式系统
由于 TF-Operator 是为了更好地适用 Tensorflow PS 方式,因此大家最先介绍一下 TensorFlow 分布式系统。
2.1 Parameter server构架
在Parameter server构架(PS构架)中,群集中的连接点被分成两大类:主要参数网络服务器(parameter server)和工作中网络服务器(worker)。在其中主要参数网络服务器储放实体模型的主要参数,而工作中网络服务器承担测算主要参数的梯度方向。在每一个迭代更新全过程,工作中网络服务器从主要参数网络服务器中得到 主要参数,随后将测算的梯度方向回到给主要参数网络服务器,主要参数网络服务器汇聚从工作中网络服务器传到的梯度方向,随后升级主要参数,并将新的主要参数广播节目给工作中网络服务器。
PS-Worker 构架的梯度方向升级拥有 同歩升级 和 多线程升级 二种方法:
在同步练习中, 全部的Worker机器设备选用同一个Batch的不一样小批(mini-batch)数据信息来训炼,等候全部机器设备该批号的梯度方向测算进行后,实体模型才会依据全部的梯度方向开展一次主要参数升级,随后PS将升级后的实体模型下达到每个机器设备。
多线程训炼中,沒有机器设备必须 去等候别的机器设备的梯度方向测算和主要参数升级,全部机器设备单独算并与将梯度方向結果升级到管理中心连接点(PS)。多线程训炼整体会训炼速率会快许多,可是多线程训炼的一个很严重的难题是梯度方向无效难题(stale gradients),一开始全部机器设备选用同样的主要参数来训炼,可是多线程状况下,某一机器设备进行一步训炼后,很有可能发觉实体模型主要参数早已被其他机器设备升级过去了,这时这一机器设备测算出的梯度方向就到期了。
2.2 Tensorflow PS-Worker
2.2.1 构架
这儿仅仅大概介绍一下,主要是为了更好地和 TF-Operator 比照。
TF 把Job关键区划为Parameter Server和Worker(由于 TF 版本号不一样,因此有不一样环节的尤其界定,例如 master 或是 chief)。
- Parameter Job:实行实体模型有关的工作,包含实体模型主要参数储存,派发,归纳,升级;做为分布式系统训炼的服务器端,直到每个终端设备(supervisors)来联接。
- Worker Job: 在TensorFlow的代码注释中被称作supervisors,实行训炼有关的工作,包含逻辑推理测算和梯度方向测算。假如主要参数的总数很大,一台设备解决不上,这就需要必须 好几个Tasks(动态性上了解,服务器上的一个过程,从静态数据的视角了解,
Task便是大家写的编码)。 - Chief supervisors:在诸多计算终端设备中务必选定一个做为关键的计算终端设备。该终端设备是在计算终端设备中最开始运行的,它的作用是合拼每个终端设备计算后的学习培训主要参数,将其储存再载入。
- Cluster 是 Jobs 的结合: Cluster(群集) 便是群集系统软件。
每一个实际人物角色互联网标志全是唯一的,即遍布在不一样IP的设备上(或是同一服务器但不一样端口)。
在具体运作中,每个人物角色的互联网搭建一部分编码务必完全一致,Ps-worker 构架分布式系统实体模型的步骤大概以下:
-
pull : 每个worker依据数据流程图的网络拓扑结构,从PS获取全新的实体模型主要参数
-
feed: 各worker添充不一样的批数据信息
-
compute: 各worker依照同样的实体模型主要参数和不一样的批数据信息测算梯度方向,得到不一样的梯度方向值
-
push 各worker 将测算获得的梯度方向值上发送给PS
-
update: PS 搜集全部worker的梯度方向值,求平均值,升级实体模型主要参数。
2.2.2 编码
实际逻辑性以下:
Task必须 了解群集上都有哪些服务器,及其他们都监视哪些端口号。tf.train.ClusterSpec()便是用于叙述这一。- 这一
Cluster(群集)有两个Job(worker.ps),worker中有三个Task(即,有三个Task实行Tensorflow op实际操作) - 将
ClusterSpec作为主要参数传到到tf.train.Server()中,与此同时特定此Task的Job_name和task_index。 - 因为是同样的程序执行在不一样的服务器上,因此要传到
job_name和task_index多方面区别,而ps_hosts和worker_hosts针对全部服务器而言,全是一样的,用于叙述群集的。 - 一个tf.train.Server包含了当地机器设备(GPUs,CPUs)的结合,能够 联接到其他task的ip:port(储存在cluster中), 还有一个session target用于实行遍布实际操作。也有最重要的一点便是,它建立了一个网络服务器,监视port端口号,如果有数据信息传出去,他便会在当地实行(运行session target,启用当地机器设备实行计算),随后結果回到给入参。
- 为了更好地使ps_server可以一直处在监视情况,大家必须 应用server.join()。这时候,过程便会block在这儿.对于为何ps_server刚建立就join呢,缘故是由于下边的编码会将主要参数特定给ps_server存放,因此ps_server静静地监视就好了。
# To build a cluster with two ps jobs on hosts ps0 and ps1, and 3 worker
# jobs on hosts worker0, worker1 and worker2.
cluster_spec = {
"ps": ["ps0:2222", "ps1:2222"],
"worker": ["worker0:2222", "worker1:2222", "worker2:2222"]}
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
略微详细点的编码以下:
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# Create a cluster from the parameter server and worker hosts.
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# 找到worker的主连接点,即task_index为0的连接点
is_chief = (FLAGS.task_index == 0)
# Assigns ops to the local worker by default.
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# Compute
运作以下,能够 看得出,大家只必须 写一个程序流程,在不一样的服务器上,传到不一样的主要参数使其运作:
# On ps0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=0
# On ps1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=1
# On worker0.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=0
# On worker1.example.com:
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=1
0x03 TF-Operator
3.1 TF-Operator 设计理念
了解了 TF 分布式系统的大概运行,大家一起来看看 TF-Operator 设计理念。
下列是以 “Design Doc TFJob K8s CRD” 中翻译的。
总体目标是使在Kubernetes(K8s)上运作TensorFlow训炼(尤其是分布式系统训炼)越来越非常容易。我建议根据建立一个K8s自定資源ioctl(CRD)和关系的控制板来完成这一点。CRD部门管理运作学习培训工作需要的K8s資源。
Kubernetes根据给予一个步骤(而不是以VM为管理中心)的全球主视图,促使流程管理越来越更为非常容易。Kubernetes更为繁杂的分布式架构程序流程给予了基本上的搭建块。比如,K8s给予对DNS、健康体检、日志搜集、衡量搜集、储存等的内嵌适用。
在K8s中,控制板承担保证一套Pods是运作情况。Pod是K8s中的基本上搭建块,它叙述了一个或好几个应当开展共精准定位的过程(同样的ip)。K8s配置了很多内嵌控制板。能够 保证N个pod以特殊的标准运作。工作控制板能够 用于运作二进制文件。
内嵌控制板不能运作分布式系统TensorFlow工作。TensorFlow是一个有情况的应用软件;每一个主要参数网络服务器和工作人员都必须 具备唯一的可寻址方式性,以适用全部不一样的分布式系统学习培训方式。K8s有一个statefulset。 可是,有情况集用以永久性运作的有情况服务项目(如Redis这类的运行内存分块缓存文件服务项目),而不是用以运作到进行的工作。
因而,今日在K8s上运作分布式系统TF工作代表着从内嵌原语中拼奏一个解决方法。一般 ,这代表着手动式管理好几个資源。比如,客户能够 为主要参数网络服务器建立一个有情况集,为工作人员建立一个有情况集,为主导网络服务器建立一个工作。
为了更好地处理内嵌資源的限定,K8s适用自定資源(CRD)和控制板。应用CRD,能够 非常容易地为特殊工作中负荷建立具备所需词义的控制板,与此同时将客户掩藏在完成中。K8s小区迅速就选用了这类方式,奉献了很多的CRD用以各种各样工作中负荷。
开发设计crd和各种各样控制板的K8s精英团队的建议是,大部分控制板应用非分布式系统、线程同步设计方案,可扩展性并不是难题。
TFJob CRD为K8s界定了TFJob資源。
TFJob資源是 TfReplicas 的结合。每一个TfReplica相匹配一个在工作上饰演人物角色的一组 TensorFlow processes;
我作出了一个确立的决策,不尝试掩藏或更换K8s抽象性。比如,每一个TfReplica都包括一个规范的K8s PodTemplate 以特定要在每一个拷贝团本中运作的过程(包含TF)。我那样做是由于K8s早已给予了一个被普遍选用和了解的API。因而,引进新的定义来替代K8s的定义是令人费解的。除此之外,公布PodTemplate 使TFJob客户能够 轻轻松松地运用K8s特点。比如,TFJob客户能够 应用K8s将卷额外到其TF过程。这促使TF与K8s适用的一切分布式存储(如PDs、NFS等)融合应用越来越很容易。
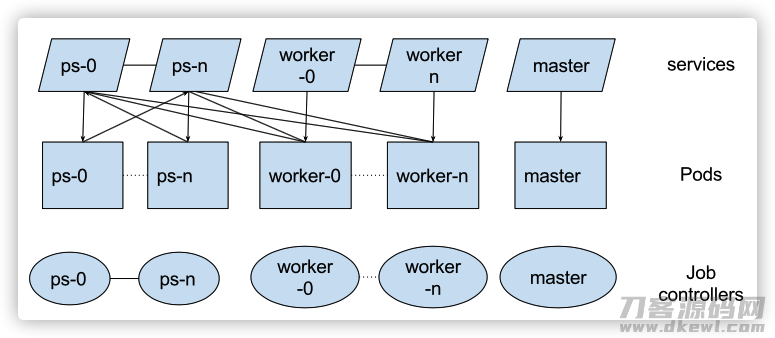
3.2 框架图
实际框架图以下:
3.2.1 什么叫Pod
大家从图上看来,首先看正中间的 pod 定义。
pod 是 k8s生产调度的最少模块。pod 能够 了解为:器皿组,与此同时pod等同于逻辑性服务器,进到pod后好像进到一个Linux服务器,指令都可以用(linux系统软件下),该“服务器”内又有很多器皿,进到后又好像是又进了一个linux服务器。默认设置状况下,每一个器皿的系统文件与别的器皿彻底防护。每一个pod都是有本机ip详细地址。pod内的器皿共享资源同样的ip和端口号室内空间。
3.2.2 为何要有 service
最先,每一个Pod都是会被分派一个独立的IP地址,并且每一个Pod都给予了一个单独的Endpoint(Pod IP ContainerPort)以被手机客户端浏览,但这类浏览仅限群集內部,外界无法浏览群集內部的IP地址,
次之,Pod的生命是比较有限的,假如Pod重新启动IP很有可能会产生变化。当 controller 用新 Pod 取代产生常见故障的 Pod 时,新 Pod 会分派到新的 IP 详细地址。那样就造成了一个难题:假如一组 Pod 对外开放给予服务项目(例如 HTTP),他们的 IP 很有可能产生变化,那麼手机客户端怎样寻找并浏览这一服务项目呢?
Kubernetes 得出的解决方法是 Service。
Service仅仅一个抽象化,Kubernetes Service 从逻辑性上意味着了一组 Pod,实际是什么 Pod 则是由 label 来选择。Service 在逻辑性上把一组pod(作用同样)给抽象性出去一个统一通道。能够 将他简易了解为干了一个服务项目的web服务。
Service 有自身 IP,并且这一 IP 是不会改变的。手机客户端只必须 浏览 Service 的 IP,Kubernetes 则承担创建和维护保养 Service 与 Pod 的投射关联。不管后面 Pod 怎样转变,对手机客户端不容易有一切危害,由于 Service 沒有变。因此一般会根据service来浏览pod。core-dns会给service分派一个內部的虚拟ip,因而內部服务项目能够 根据这一ip或是是serviceName来浏览到pod的服务项目。
大家得出一个源代码中的service 事例。
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/path: /metrics
prometheus.io/scrape: "true"
prometheus.io/port: "8443"
labels:
app: tf-job-operator
name: tf-job-operator
spec:
ports:
- name: monitoring-port
port: 8443
targetPort: 8443
selector:
name: tf-job-operator
type: ClusterIP
如今大家见到早已建立了名叫tf-job-operator的Service,会分派一个Cluster IP,该Service还会继续不断的监视selector下边的 Pod,会把这种Pod信息内容升级到一个名叫 tf-job-operator 的Endpoints目标上来,这一目标就类似大家上边说的Pod结合了。
3.2.3 什么叫 controller
由于 Kubernetes 目前的资源不能满足大家的要求,因而必须 根据 Custom Resource Definition 的体制开展拓展。
K8S中一切都是resource,例如Deployment,Service这些。
我们可以根据CRD(CustomResourceDefinitions)作用增加resource,例如我觉得自定一种Deployment資源,给予不一样的布署对策。
我们知道resource能够 根据k8s的RESTFUL API开展CURD实际操作,针对CRD建立的resource也是一样的。
CRD只是是界定一种resource,大家还必须 完成controller,类似deployment controller这些,监视相匹配資源的CURD事情,作出相匹配的解决,例如布署POD。
实际上 ,TF-Operator 关键便是一个 Controller 的完成,大家下边也关键便是解读这一 controller。
3.3 Spec
大家最先得出一个 Job Spec,那样大伙儿能够 在事后和编码中相匹配。样比如下,有着一个 master,2个 workers,一个 PS。
apiVersion: "kubeflow.org/v1alpha1" # 特定api版本号,此值务必在kubectl api-versions中
kind: "TFJob" # 特定建立資源的人物角色/种类
metadata: # 資源的数据库/特性
name: "example-job"
spec: # 資源规范字段
replicaSpecs: # 申明团本数量
- replicas: 1
tfReplicaType: MASTER
template: # 模板
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff # 器皿应用的镜像系统详细地址
name: tensorflow
args:
- --log_dir=gs://my-job/log-dir
restartPolicy: OnFailure
- replicas: 2
tfReplicaType: WORKER
template:
spec:
containers:
- image: gcr.io/tf-on-k8s-dogfood/tf_sample:dc944ff
name: tensorflow
args:
- --log_dir=gs://my-job/log-dir
restartPolicy: OnFailure
- replicas: 1
tfReplicaType: PS
下边大家逐渐进到代码世界。
3.4 TFJob
最先大家看一下 TFJob 的界定,大概能够 和上边的 Spec 中寻找对应关系,由于文中目地是掌握其大致,因此大家就只剖析这种就可以。
// TFJob represents a TFJob resource.
type TFJob struct {
// Standard Kubernetes type metadata.
metav1.TypeMeta `json:",inline"`
// Standard Kubernetes object's metadata.
// optional
metav1.ObjectMeta `json:"metadata,omitempty"`
// Specification of the desired state of the TFJob.
// optional
Spec TFJobSpec `json:"spec,omitempty"`
// Most recently observed status of the TFJob.
// Populated by the system.
// Read-only.
// optional
Status commonv1.JobStatus `json:"status,omitempty"`
}
// TFJobSpec is a desired state description of the TFJob.
type TFJobSpec struct {
// RunPolicy encapsulates various runtime policies of the distributed training
// job, for example how to clean up resources and how long the job can stay
// active.
RunPolicy commonv1.RunPolicy `json:"runPolicy,inline"`
// SuccessPolicy defines the policy to mark the TFJob as succeeded.
// Default to "", using the default rules.
// optional
SuccessPolicy *SuccessPolicy `json:"successPolicy,omitempty"`
// A map of TFReplicaType (type) to ReplicaSpec (value). Specifies the TF cluster configuration.
// For example,
// {
// "PS": ReplicaSpec,
// "Worker": ReplicaSpec,
// }
TFReplicaSpecs map[commonv1.ReplicaType]*commonv1.ReplicaSpec `json:"tfReplicaSpecs"`
// // A switch to enable dynamic worker
EnableDynamicWorker bool `json:"enableDynamicWorker,omitempty"`
}
3.5 人物角色
次之大家看一下 TF-Operator 当中,对 TF 人物角色的相匹配完成。
3.5.1 界定
最先是人物角色界定。这儿的人物角色基本上相匹配了 Tensorflow 的每个人物角色,包含许多为了更好地兼容而保存的人物角色。
// setTypeNamesToCamelCase sets the name of all replica types from any case to correct case.
func setTypeNamesToCamelCase(tfJob *TFJob) {
setTypeNameToCamelCase(tfJob, TFReplicaTypePS)
setTypeNameToCamelCase(tfJob, TFReplicaTypeWorker)
setTypeNameToCamelCase(tfJob, TFReplicaTypeChief)
setTypeNameToCamelCase(tfJob, TFReplicaTypeMaster)
setTypeNameToCamelCase(tfJob, TFReplicaTypeEval)
}
const (
// TFReplicaTypePS is the type for parameter servers of distributed TensorFlow.
TFReplicaTypePS commonv1.ReplicaType = "PS"
// TFReplicaTypeWorker is the type for workers of distributed TensorFlow.
// This is also used for non-distributed TensorFlow.
TFReplicaTypeWorker commonv1.ReplicaType = "Worker"
// TFReplicaTypeChief is the type for chief worker of distributed TensorFlow.
// If there is "chief" replica type, it's the "chief worker".
// Else, worker:0 is the chief worker.
TFReplicaTypeChief commonv1.ReplicaType = "Chief"
// TFReplicaTypeMaster is the type for master worker of distributed TensorFlow.
// This is similar to chief, and kept just for backwards compatibility.
TFReplicaTypeMaster commonv1.ReplicaType = "Master"
// TFReplicaTypeEval is the type for evaluation replica in TensorFlow.
TFReplicaTypeEval commonv1.ReplicaType = "Evaluator"
)
3.5.2 建立人物角色
NewTFJobV2 涵数便是根据配备的不一样,来建立不一样的人物角色。
这儿能够 见到,转化成 job 情况下,基本上便是依照 spec 的相匹配字段名来解决。
apiVersion: "kubeflow.org/v1alpha1"
kind: "TFJob"
metadata:
name: "example-job"
spec:
replicaSpecs:
下边是函数定义。
func NewTFJobV2(worker, ps, master, cheif, evaluator int) *tfv1.TFJob {
tfJob := &tfv1.TFJob{
TypeMeta: metav1.TypeMeta{
Kind: tfv1.Kind,
},
ObjectMeta: metav1.ObjectMeta{
Name: TestTFJobName,
Namespace: metav1.NamespaceDefault,
},
Spec: tfv1.TFJobSpec{
TFReplicaSpecs: make(map[commonv1.ReplicaType]*commonv1.ReplicaSpec),
},
}
tfv1.SetObjectDefaults_TFJob(tfJob)
if worker > 0 {
worker := int32(worker)
workerReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &worker,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeWorker] = workerReplicaSpec
}
if ps > 0 {
ps := int32(ps)
psReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &ps,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypePS] = psReplicaSpec
}
if master > 0 {
master := int32(master)
masterReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &master,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeMaster] = masterReplicaSpec
}
if cheif > 0 {
cheif := int32(cheif)
cheifReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &cheif,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeChief] = cheifReplicaSpec
}
if evaluator > 0 {
evaluator := int32(evaluator)
evaluatorReplicaSpec := &commonv1.ReplicaSpec{
Replicas: &evaluator,
Template: NewTFReplicaSpecTemplate(),
}
tfJob.Spec.TFReplicaSpecs[tfv1.TFReplicaTypeChief] = evaluatorReplicaSpec
}
return tfJob
}
3.5.3 如何区分 master
用以下方式区别 master。
func (tc *TFController) IsMasterRole(replicas map[commonv1.ReplicaType]*commonv1.ReplicaSpec, rtype commonv1.ReplicaType, index int) bool {
if ContainChieforMasterSpec(replicas) {
return rtype == tfv1.TFReplicaTypeChief || rtype == tfv1.TFReplicaTypeMaster
}
// else check if it is worker with index 0
return rtype == tfv1.TFReplicaTypeWorker && index == 0
}
0x04 Contoller
下边就进到主题,看一下 Controller 怎样完成。
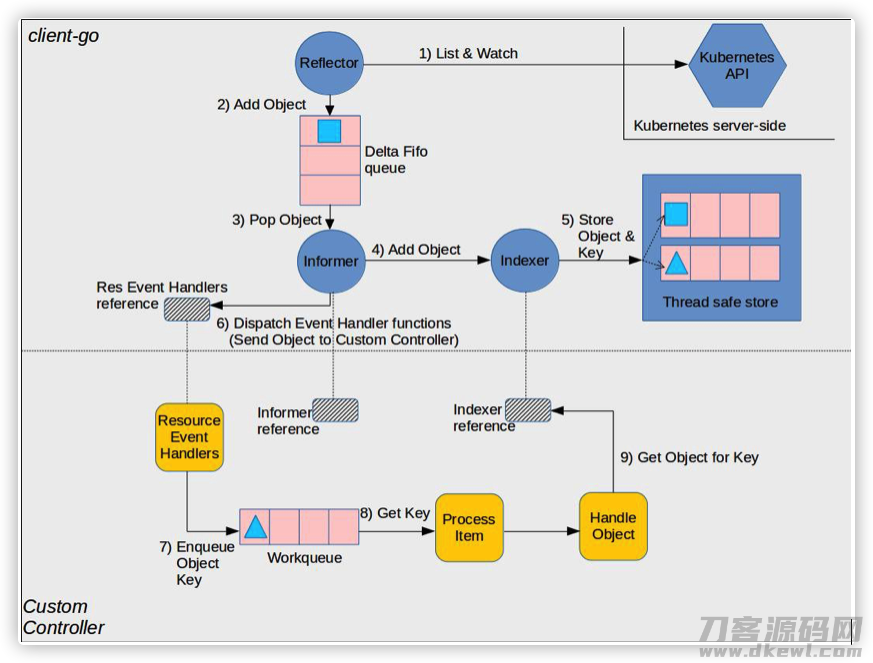
4.1 K8S CRD重要定义
最先大家必须 看一下 K8S CRD 的一些重要定义。
-
informer:监视apiserver中特殊資源转变,随后会储存到一个线程安全的local cache中,最终回调函数我们自己完成的event handler。
-
local cache:informer即时同歩apiserver(也就是etcd)中的数据信息到运行内存中储存,能够 合理减少apiserver的查看工作压力,但缺陷便是实用性不太好,当地会比远程控制的数据信息落伍一点点但会最后与etcd一致,因此必须 依据状况深入分析是走Local cache或是apiserver即时读取数据。
-
Lister:给予了CURD实际操作浏览local cache。
-
controller:一个逻辑性定义,是指生产调度某类資源的完成罢了,必须 我们自己开发设计。Controller做的事儿关键包含:
-
- 完成event handler解决資源的CURD实际操作
- 在event handler,能够 应用workqueue类库完成同样資源目标的持续event的去重复,及其event解决出现异常后的不成功再试,一般 是提议应用的。
-
Workqueue:一个独立的类库,是可选择应用的,但一般 都是会应用,缘故上边讲了。大家必须 在完成event handler的情况下把产生变化的資源标志放进workqueue,供下边的processor消費。
-
Clientset:默认设置clientset只有CRUD k8s给予的资源,例如deployments,daemonset等;转化成的编码为大家自定的資源(CRD)转化成了独立的clientset,进而使我们应用结构型的编码CURD自定資源。换句话说,想实际操作内建資源就用k8s内置的clientset,想实际操作CRD就用转化成编码里的clientset。
-
Processor:大家完成的go协同程序,消費workqueue中的事情,workqueue给予了按資源标志的去重复。
4.2 界定
TFController 的界定以下,能看出去好多个成员函数都有常用,就各自采用了以上的一部分部件。
// TFController is the type for TFJob Controller, which manages
// the lifecycle of TFJobs.
type TFController struct {
common.JobController
// tfJobClientSet is a clientset for CRD TFJob.
tfJobClientSet tfjobclientset.Interface
// To allow injection of sync functions for testing.
syncHandler func(string) (bool, error)
// tfJobInformer is a temporary field for unstructured informer support.
tfJobInformer cache.SharedIndexInformer
// Listers for TFJob, Pod and Service
// tfJobLister can list/get tfjobs from the shared informer's store.
tfJobLister tfjoblisters.TFJobLister
// tfJobInformerSynced returns true if the tfjob store has been synced at least once.
tfJobInformerSynced cache.InformerSynced
}
4.3 通道
TF-Operator 逻辑性编码的通道是 runWorker,实际上 便是循环系统启用 processNextWorkItem。
func (tc *TFController) runWorker() {
for tc.processNextWorkItem() {
}
}
processNextWorkItem将从WorkQueue中载入单独工作中项,并试着根据启用syncHandler来解决它。
// processNextWorkItem will read a single work item off the workqueue and
// attempt to process it, by calling the syncHandler.
func (tc *TFController) processNextWorkItem() bool {
obj, quit := tc.WorkQueue.Get()
if key, ok = obj.(string); !ok {
tc.WorkQueue.Forget(obj)
return true
}
tfJob, err := tc.getTFJobFromKey(key)
// 同歩TFJob以将具体情况配对到需要的情况。
// Sync TFJob to match the actual state to this desired state.
forget, err := tc.syncHandler(key)
}
4.4 syncHandler
syncHandler 的功效是根据 key 来同歩 Job,就是以 WorkQueue 当中弄出一个 job,当地解决。
以前设定有 tc.syncHandler = tc.syncTFJob,因此大家具体赶到了 syncTFJob。
- 假如
tfjob的期待值早已完成,那麼syncTFJob便会用给出的key来同歩tfjob,这代表着它不期待大量的pod/service被建立或删掉: - EnableDynamicWorker 这儿会依据不一样种类设定。
- 随后会启用 ReconcileJobs 对实际 job 开展解决。
// syncTFJob syncs the tfjob with the given key if it has had its expectations fulfilled, meaning
// it did not expect to see any more of its pods/services created or deleted.
// This function is not meant to be invoked concurrently with the same key.
// 这一涵数不可以与同一个key与此同时启用
func (tc *TFController) syncTFJob(key string) (bool, error) {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
sharedTFJob, err := tc.getTFJobFromName(namespace, name)
tfjob := sharedTFJob.DeepCopy()
// Sync tfjob every time if EnableDynamicWorker is true
tfjobNeedsSync := tfjob.Spec.EnableDynamicWorker || tc.satisfiedExpectations(tfjob)
// 为新tfjob设定初始值。
// Set default for the new tfjob.
scheme.Scheme.Default(tfjob)
if tfjobNeedsSync && tfjob.DeletionTimestamp == nil {
// 启用reconcileTFJobs来运行TFJobs
reconcileTFJobsErr = tc.ReconcileJobs(tfjob, tfjob.Spec.TFReplicaSpecs, tfjob.Status, &tfjob.Spec.RunPolicy)
}
return true, err
}
4.5 ReconcileJobs
reconcileTFJobs查验并升级每一个给出TFReplicaSpec的replicas,而且做相对应解决,能够 觉得这儿是主控芯片逻辑性。
- 假如 job 完毕,则做相对应解决,delete全部pod和service。
- 假如TFJob超出了backofflimit或超出了active deadline,删掉全部pod和service,随后将情况设定为failed。
- 不然 解析xml环境变量的TFReplicaSpecs一部分,
- 各自为不一样种类的连接点运行相对应的Pod。
- 在运行Pod以后,还需要为其运行一个Service。
// 假如在建立/删掉 pods/services时产生不正确,它将要求tfjob。// ReconcileJobs checks and updates replicas for each given ReplicaSpec.
// It will requeue the job in case of an error while creating/deleting pods/services.
func (jc *JobController) ReconcileJobs(
job interface{},
replicas map[apiv1.ReplicaType]*apiv1.ReplicaSpec,
jobStatus apiv1.JobStatus,
runPolicy *apiv1.RunPolicy) error {
metaObject, ok := job.(metav1.Object)
jobName := metaObject.GetName()
runtimeObject, ok := job.(runtime.Object)
jobKey, err := KeyFunc(job)
pods, err := jc.Controller.GetPodsForJob(job)
services, err := jc.Controller.GetServicesForJob(job)
oldStatus := jobStatus.DeepCopy()
// 假如TFJob terminated,则delete全部pod和service。
if commonutil.IsSucceeded(jobStatus) || commonutil.IsFailed(jobStatus) {
// If the Job is succeed or failed, delete all pods and services.
jc.DeletePodsAndServices(runPolicy, job, pods)
jc.CleanupJob(runPolicy, jobStatus, job)
return nil
}
// 查找之前的再试频次
// retrieve the previous number of retry
previousRetry := jc.WorkQueue.NumRequeues(jobKey)
activePods := k8sutil.FilterActivePods(pods)
jc.recordAbnormalPods(activePods, runtimeObject)
active := int32(len(activePods))
failed := k8sutil.FilterPodCount(pods, v1.PodFailed)
totalReplicas := k8sutil.GetTotalReplicas(replicas)
prevReplicasFailedNum := k8sutil.GetTotalFailedReplicas(jobStatus.ReplicaStatuses)
if jobExceedsLimit {
// If the Job exceeds backoff limit or is past active deadline
// delete all pods and services, then set the status to failed
jc.DeletePodsAndServices(runPolicy, job, pods); err != nil {
jc.CleanupJob(runPolicy, jobStatus, job); err != nil {
jc.Recorder.Event(runtimeObject, v1.EventTypeNormal, commonutil.JobFailedReason, failureMessage)
commonutil.UpdateJobConditions(&jobStatus, apiv1.JobFailed, commonutil.JobFailedReason, failureMessage)
return jc.Controller.UpdateJobStatusInApiServer(job, &jobStatus)
} else {
// General cases which need to reconcile
if jc.Config.EnableGangScheduling {
minAvailableReplicas := totalReplicas
_, err := jc.SyncPodGroup(metaObject, minAvailableReplicas)
}
// 解析xml环境变量的TFReplicaSpecs一部分,各自为不一样种类的连接点运行相对应的Pod。
// 在运行Pod以后,还需要为其运行一个Service。
// Diff current active pods/services with replicas.
for rtype, spec := range replicas {
err := jc.Controller.ReconcilePods(metaObject, &jobStatus, pods, rtype, spec, replicas)
err = jc.Controller.ReconcileServices(metaObject, services, rtype, spec)
}
}
err = jc.Controller.UpdateJobStatus(job, replicas, &jobStatus)
// No need to update the job status if the status hasn't changed since last time.
if !reflect.DeepEqual(*oldStatus, jobStatus) {
return jc.Controller.UpdateJobStatusInApiServer(job, &jobStatus)
}
return nil
}
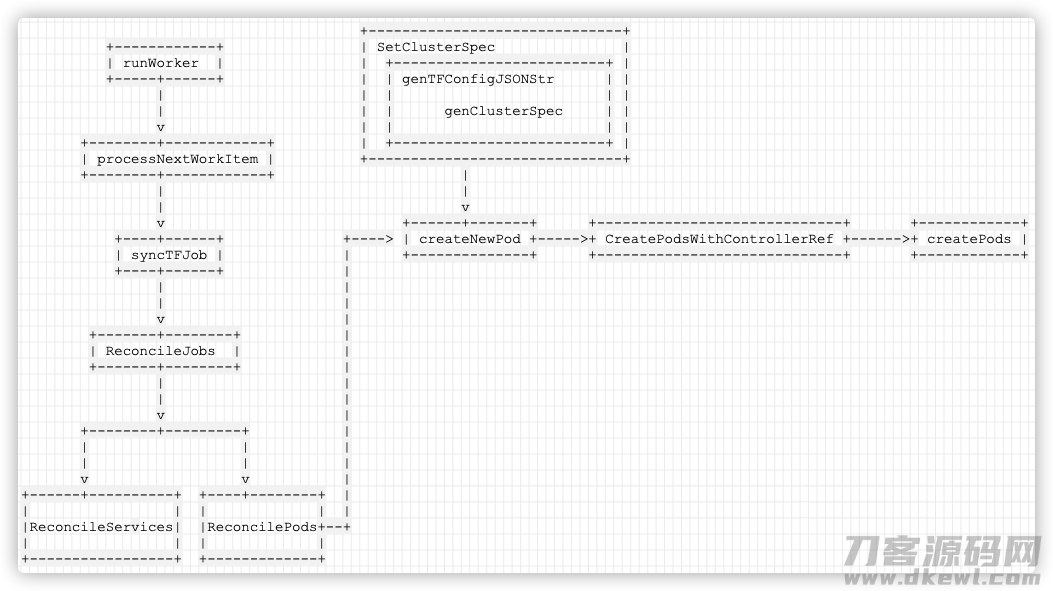
现阶段逻辑性以下:
------------
| runWorker |
----- ------
|
|
v
-------- ------------
| processNextWorkItem |
-------- ------------
|
|
v
---- ------
| syncTFJob |
---- ------
|
|
v
------- --------
| ReconcileJobs |
------- --------
|
|
v
-------- ---------
| |
| |
v v
--------- --------- ----- --------
| | | |
| ReconcileServices | |ReconcilePods |
| | | |
------------------- --------------
下边大家各自详细介绍解决 Pod 和 解决 Service。
4.6 解决 Pod
4.6.1 ReconcilePods
reconcilePods为每一个给出的TFReplicaSpec定期检查升级pod。
实际例如:
- 复位 replica 的情况;
- 假如master pod存有,挑选master pod,要是没有master,第一个worker pod评为master;
- createNewPod 来建立新的 pod;
- 或是删掉 pod;
// reconcilePods checks and updates pods for each given TFReplicaSpec.
// It will requeue the tfjob in case of an error while creating/deleting pods.
func (tc *TFController) ReconcilePods(
job interface{},
jobStatus *commonv1.JobStatus,
pods []*v1.Pod,
rtype commonv1.ReplicaType,
spec *commonv1.ReplicaSpec,
replicas map[commonv1.ReplicaType]*commonv1.ReplicaSpec,
) error {
tfJob, ok := job.(*tfv1.TFJob)
// Convert ReplicaType to lower string.
rt := strings.ToLower(string(rtype))
// 获得rtype种类的全部pod。
pods, err := tc.FilterPodsForReplicaType(pods, rt)
numReplicas := int(*spec.Replicas)
masterRole := false
initializeReplicaStatuses(jobStatus, rtype)
// GetPodSlices will return enough information here to make decision to add/remove/update resources.
// For example, let's assume we have pods with replica-index 0, 1, 2
// If replica is 4, return a slice with size 4. [[0],[1],[2],[]], a pod with replica-index 3 will be created.
// If replica is 1, return a slice with size 3. [[0],[1],[2]], pod with replica-index 1 and 2 are out of range and will be deleted.
podSlices := tc.GetPodSlices(pods, numReplicas, logger)
for index, podSlice := range podSlices {
if len(podSlice) > 1 {
logger.Warningf("We have too many pods for %s %d", rt, index)
} else if len(podSlice) == 0 {
// 假如master pod存有,挑选master pod
// 要是没有master,第一个worker pod评为master。 // check if this replica is the master role
masterRole = tc.IsMasterRole(replicas, rtype, index)
// TODO: [should change to CreateNewPod]
err = tc.createNewPod(tfJob, rt, strconv.Itoa(index), spec, masterRole, replicas)
} else {
// Check the status of the current pod.
pod := podSlice[0]
// 现阶段只容许减缩workers
// check if the index is in the valid range, if not, we should kill the pod
if index < 0 || index >= numReplicas {
err = tc.PodControl.DeletePod(pod.Namespace, pod.Name, tfJob)
}
// Check if the pod is retryable.
if spec.RestartPolicy == commonv1.RestartPolicyExitCode {
if pod.Status.Phase == v1.PodFailed && train_util.IsRetryableExitCode(exitCode) {
tc.Recorder.Event(tfJob, corev1.EventTypeWarning, tfJobRestartingReason, msg)
err := commonutil.UpdateJobConditions(jobStatus, commonv1.JobRestarting, tfJobRestartingReason, msg)
tfJobsRestartCount.Inc()
}
}
updateJobReplicaStatuses(jobStatus, rtype, pod)
}
}
return nil
}
4.6.2 createNewPod
createNewPod为给出的index和type建立一个新的pod:
// createNewPod creates a new pod for the given index and type.
func (tc *TFController) createNewPod(tfjob *tfv1.TFJob, rt, index string, spec *commonv1.ReplicaSpec, masterRole bool,
replicas map[commonv1.ReplicaType]*commonv1.ReplicaSpec) error {
tfjobKey, err := KeyFunc(tfjob)
expectationPodsKey := expectation.GenExpectationPodsKey(tfjobKey, rt)
// Create OwnerReference.
controllerRef := tc.GenOwnerReference(tfjob)
// Set type and index for the worker.
labels := tc.GenLabels(tfjob.Name)
labels[tfReplicaTypeLabel] = rt
labels[tfReplicaIndexLabel] = index
podTemplate := spec.Template.DeepCopy()
// Set name for the template.
podTemplate.Name = common.GenGeneralName(tfjob.Name, rt, index)
if podTemplate.Labels == nil {
podTemplate.Labels = make(map[string]string)
}
for key, value := range labels {
podTemplate.Labels[key] = value
}
// 转化成群集的配备信息内容,这儿最重要,看一下完成
if err := tc.SetClusterSpec(tfjob, podTemplate, rt, index); err != nil {
return err
}
// if gang-scheduling is enabled:
// 1. if user has specified other scheduler, we report a warning without overriding any fields.
// 2. if no SchedulerName is set for pods, then we set the SchedulerName to "kube-batch".
if tc.Config.EnableGangScheduling {
if isNonGangSchedulerSet(replicas) {
tc.Recorder.Event(tfjob, v1.EventTypeWarning, podTemplateSchedulerNameReason, errMsg)
} else {
podTemplate.Spec.SchedulerName = gangSchedulerName
}
if podTemplate.Annotations == nil {
podTemplate.Annotations = map[string]string{}
}
podTemplate.Annotations[gangSchedulingPodGroupAnnotation] = tfjob.GetName()
podTemplate.Annotations[volcanoTaskSpecKey] = rt
}
// 应用上边的配备信息内容,真真正正运行Pod的建立
err = tc.PodControl.CreatePodsWithControllerRef(tfjob.Namespace, podTemplate, tfjob, controllerRef)
return nil
}
4.6.3 转化成配备信息内容
4.6.3.1 SetClusterSpec
上边涵数中的转化成配备信息内容较为关键,因此大家独立分离出来说一下。
setClusterSpec为给出的podTemplateSpec转化成并设定TF_CONFIG:
// SetClusterSpec generates and sets TF_CONFIG for the given podTemplateSpec.
func (tc *TFController) SetClusterSpec(job interface{}, podTemplate *v1.PodTemplateSpec, rtype, index string) error {
tfjob, ok := job.(*tfv1.TFJob)
// Generate TF_CONFIG JSON string.
tfConfigStr, err := genTFConfigJSONStr(tfjob, rtype, index)
// Add TF_CONFIG environment variable to tensorflow container in the pod.
for i := range podTemplate.Spec.Containers {
if podTemplate.Spec.Containers[i].Name == tfv1.DefaultContainerName {
if len(podTemplate.Spec.Containers[i].Env) == 0 {
podTemplate.Spec.Containers[i].Env = make([]v1.EnvVar, 0)
}
podTemplate.Spec.Containers[i].Env = append(podTemplate.Spec.Containers[i].Env, v1.EnvVar{
Name: tfConfig,
Value: tfConfigStr,
})
break
}
}
return nil
}
4.6.3.2 genTFConfigJSONStr
genTFConfigJSONStr 会转化成 json 数据信息。
// genTFConfig will generate the environment variable TF_CONFIG
// {
// "cluster": {
// "ps": ["ps1:2222", "ps2:2222"],
// "worker": ["worker1:2222", "worker2:2222", "worker3:2222"]
// },
// "task": {
// "type": "ps",
// "index": 1
// },
// }
// }
func genTFConfigJSONStr(tfjob *tfv1.TFJob, rtype, index string) (string, error) {
// Configure the TFCONFIG environment variable.
i, err := strconv.ParseInt(index, 0, 32)
if err != nil {
return "", err
}
cluster, err := genClusterSpec(tfjob)
if err != nil {
return "", err
}
var tfConfigJSONByteSlice []byte
if tfjob.Spec.EnableDynamicWorker {
sparseCluster := convertClusterSpecToSparseClusterSpec(cluster, strings.ToLower(rtype), int32(i))
sparseTFConfig := SparseTFConfig{
Cluster: sparseCluster,
Task: TaskSpec{
Type: strings.ToLower(rtype),
Index: int(i),
},
}
tfConfigJSONByteSlice, err = json.Marshal(sparseTFConfig)
} else {
tfConfig := TFConfig{
Cluster: cluster,
Task: TaskSpec{
Type: strings.ToLower(rtype),
Index: int(i),
},
// We need to set environment to cloud otherwise it will default to local which isn't what we want.
// Environment is used by tensorflow.contrib.learn.python.learn in versions <= 1.3
// TODO(jlewi): I don't think it is used in versions TF >- 1.4. So we can eventually get rid of it.
// 大家必须 设定自然环境为cloud,不然它会默认设置为local,这不是大家要想的。
Environment: "cloud",
}
tfConfigJSONByteSlice, err = json.Marshal(tfConfig)
}
if err != nil {
return "", err
}
return string(tfConfigJSONByteSlice), nil
}
4.6.3.3 genClusterSpec
这儿就是以群集信息内容中得到 cluster 信息内容。
// genClusterSpec will generate ClusterSpec.
func genClusterSpec(tfjob *tfv1.TFJob) (ClusterSpec, error) {
clusterSpec := make(ClusterSpec)
for rtype, spec := range tfjob.Spec.TFReplicaSpecs {
rt := strings.ToLower(string(rtype))
replicaNames := make([]string, 0, *spec.Replicas)
port, err := GetPortFromTFJob(tfjob, rtype)
// 这儿循环系统转化成了TF_CONFIG里边的Cluster信息内容。留意看注解,应用DNS相互配合Service,处理的或是每个连接点IP不固定不动的难题
for i := int32(0); i < *spec.Replicas; i {
// As described here: https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#a-records.
// Headless service assigned a DNS A record for a name of the form "my-svc.my-namespace.svc.cluster.local".
// And the last part "svc.cluster.local" is called cluster domain
// which maybe different between kubernetes clusters.
// 以下上述:https://kubernetes.io/docs/concepts/services-networking/dns-pos-service/#a-records。
// Headless service为"my-svc.my-namespace.svc.cluster.local"的名字分派一个DNS纪录。
// 最终一部分是"svc.cluster.local"被称作cluster domain,在不一样的kubernetes集群中间很有可能存有差别。
hostName := common.GenGeneralName(tfjob.Name, rt, fmt.Sprintf("%d", i))
svcName := hostName "." tfjob.Namespace "." "svc"
clusterDomain := os.Getenv(EnvCustomClusterDomain)
if len(clusterDomain) > 0 {
svcName = "." clusterDomain
}
endpoint := fmt.Sprintf("%s:%d", svcName, port)
replicaNames = append(replicaNames, endpoint)
}
clusterSpec[rt] = replicaNames
}
return clusterSpec, nil
}
4.6.4 CreatePodsWithControllerRef
获得了群集配备信息内容以后,就应用群集的配备信息内容,开展真真正正运行Pod的建立:
func (r RealPodControl) CreatePods(namespace string, template *v1.PodTemplateSpec, object runtime.Object) error {
return r.createPods("", namespace, template, object, nil)
}
func (r RealPodControl) CreatePodsWithControllerRef(namespace string, template *v1.PodTemplateSpec, controllerObject runtime.Object, controllerRef *metav1.OwnerReference) error {
if err := ValidateControllerRef(controllerRef); err != nil {
return err
}
return r.createPods("", namespace, template, controllerObject, controllerRef)
}
4.6.5 createPods
这儿才真真正正启用K8S插口建立pod
func (r RealPodControl) createPods(nodeName, namespace string, template *v1.PodTemplateSpec, object runtime.Object, controllerRef *metav1.OwnerReference) error {
pod, err := GetPodFromTemplate(template, object, controllerRef)
if len(nodeName) != 0 {
pod.Spec.NodeName = nodeName
}
if labels.Set(pod.Labels).AsSelectorPreValidated().Empty() {
return fmt.Errorf("unable to create pods, no labels")
}
if newPod, err := r.KubeClient.CoreV1().Pods(namespace).Create(pod); err != nil {
return err
} else {
accessor, err := meta.Accessor(object)
}
return nil
}
这时逻辑性以下:
------------------------------
------------ | SetClusterSpec |
| runWorker | | ------------------------- |
----- ------ | | genTFConfigJSONStr | |
| | | | |
| | | genClusterSpec | |
v | | | |
-------- ------------ | ------------------------- |
| processNextWorkItem | ------------------------------
-------- ------------ |
| |
| v
v ------ ------- ----------------------------- ------------
---- ------ ----> | createNewPod -----> CreatePodsWithControllerRef ------> createPods |
| syncTFJob | | -------------- ----------------------------- ------------
---- ------ |
| |
| |
v |
------- -------- |
| ReconcileJobs | |
------- -------- |
| |
| |
v |
-------- --------- |
| | |
| | |
v v |
------ ---------- ---- -------- |
| | | | |
|ReconcileServices| |ReconcilePods --
| | | |
----------------- -------------
手机上以下:
4.7 解决服务项目
4.7.1 ReconcileServices
ReconcileServices 为每一个给出的TFReplicaSpec定期检查升级service,大概以下:
- 将在建立/删除服务时产生不正确时要求tfjob。
- 获得rt种类的全部service。
- 或是创建新服务项目;
- 或是删掉旧服务项目,现阶段只容许变小worker的service范畴;
// reconcileServices checks and updates services for each given ReplicaSpec.
// It will requeue the job in case of an error while creating/deleting services.
func (jc *JobController) ReconcileServices(
job metav1.Object,
services []*v1.Service,
rtype apiv1.ReplicaType,
spec *apiv1.ReplicaSpec) error {
// Convert ReplicaType to lower string.
rt := strings.ToLower(string(rtype))
replicas := int(*spec.Replicas)
// Get all services for the type rt.
services, err := jc.FilterServicesForReplicaType(services, rt)
// GetServiceSlices will return enough information here to make decision to add/remove/update resources.
//
// For example, let's assume we have services with replica-index 0, 1, 2
// If replica is 4, return a slice with size 4. [[0],[1],[2],[]], a svc with replica-index 3 will be created.
//
// If replica is 1, return a slice with size 3. [[0],[1],[2]], svc with replica-index 1 and 2 are out of range and will be deleted.
serviceSlices := jc.GetServiceSlices(services, replicas, commonutil.LoggerForReplica(job, rt))
for index, serviceSlice := range serviceSlices {
if len(serviceSlice) > 1 {
} else if len(serviceSlice) == 0 {
err = jc.CreateNewService(job, rtype, spec, strconv.Itoa(index))
} else {
// Check the status of the current svc.
svc := serviceSlice[0]
// check if the index is in the valid range, if not, we should kill the svc
if index < 0 || index >= replicas {
err = jc.ServiceControl.DeleteService(svc.Namespace, svc.Name, job.(runtime.Object))
}
}
}
return nil
}
4.7.2 CreateNewService
为给出的index和type建立一个新service:
// createNewService creates a new service for the given index and type.
func (jc *JobController) CreateNewService(job metav1.Object, rtype apiv1.ReplicaType,
spec *apiv1.ReplicaSpec, index string) error {
jobKey, err := KeyFunc(job)
// Convert ReplicaType to lower string.
rt := strings.ToLower(string(rtype))
expectationServicesKey := expectation.GenExpectationServicesKey(jobKey, rt)
err = jc.Expectations.ExpectCreations(expectationServicesKey, 1)
if err != nil {
return err
}
// Append ReplicaTypeLabel and ReplicaIndexLabel labels.
labels := jc.GenLabels(job.GetName())
labels[apiv1.ReplicaTypeLabel] = rt
labels[apiv1.ReplicaIndexLabel] = index
port, err := jc.GetPortFromJob(spec)
if err != nil {
return err
}
service := &v1.Service{
Spec: v1.ServiceSpec{
ClusterIP: "None",
Selector: labels,
Ports: []v1.ServicePort{},
},
}
// Add service port to headless service only if port is set from controller implementation
if port != nil {
svcPort := v1.ServicePort{Name: jc.Controller.GetDefaultContainerPortName(), Port: *port}
service.Spec.Ports = append(service.Spec.Ports, svcPort)
}
service.Name = GenGeneralName(job.GetName(), rt, index)
service.Labels = labels
// Create OwnerReference.
controllerRef := jc.GenOwnerReference(job)
err = jc.ServiceControl.CreateServicesWithControllerRef(job.GetNamespace(), service, job.(runtime.Object), controllerRef)
if err != nil && errors.IsTimeout(err) {
succeededServiceCreationCount.Inc()
return nil
} else if err != nil {
failedServiceCreationCount.Inc()
return err
}
succeededServiceCreationCount.Inc()
return nil
}
4.7.3 CreateServicesWithControllerRef
应用群集的配备信息内容,真真正正运行Service的建立:
func (r RealServiceControl) CreateServicesWithControllerRef(namespace string, service *v1.Service, controllerObject runtime.Object, controllerRef *metav1.OwnerReference) error {
if err := ValidateControllerRef(controllerRef); err != nil {
return err
}
return r.createServices(namespace, service, controllerObject, controllerRef)
}
4.7.4 createServices
这时才真真正正启用K8S插口建立service:
func (r RealServiceControl) createServices(namespace string, service *v1.Service, object runtime.Object, controllerRef *metav1.OwnerReference) error {
if labels.Set(service.Labels).AsSelectorPreValidated().Empty() {
return fmt.Errorf("unable to create Services, no labels")
}
serviceWithOwner, err := GetServiceFromTemplate(service, object, controllerRef)
newService, err := r.KubeClient.CoreV1().Services(namespace).Create(serviceWithOwner)
accessor, err := meta.Accessor(object)
}
这时逻辑性扩展以下:
------------------------------
------------ | SetClusterSpec |
| runWorker | | ------------------------- |
----- ------ | | genTFConfigJSONStr | |
| | | | |
| | | genClusterSpec | |
v | | | |
-------- ------------ | ------------------------- |
| processNextWorkItem | ------------------------------
-------- ------------ |
| |
| v
v ------ ------- ----------------------------- ------------
---- ------ ----> | createNewPod -----> CreatePodsWithControllerRef ------> createPods |
| syncTFJob | | -------------- ----------------------------- ------------
---- ------ |
| |
| |
v | ------------------ --------------------------------- ----------------
------- -------- | ----> | CreateNewService ----> CreateServicesWithControllerRef ---> createServices |
| ReconcileJobs | | | ------------------ --------------------------------- ----------------
------- -------- | |
| | |
| | |
v | |
-------- --------- | |
| | | |
| | | |
v v | |
------ ---------- ---- -------- | |
| | | | | |
|ReconcileServices| |ReconcilePods -- |
| | | | |
------ ---------- ------------- |
| |
---------------------------------->
手机上以下:
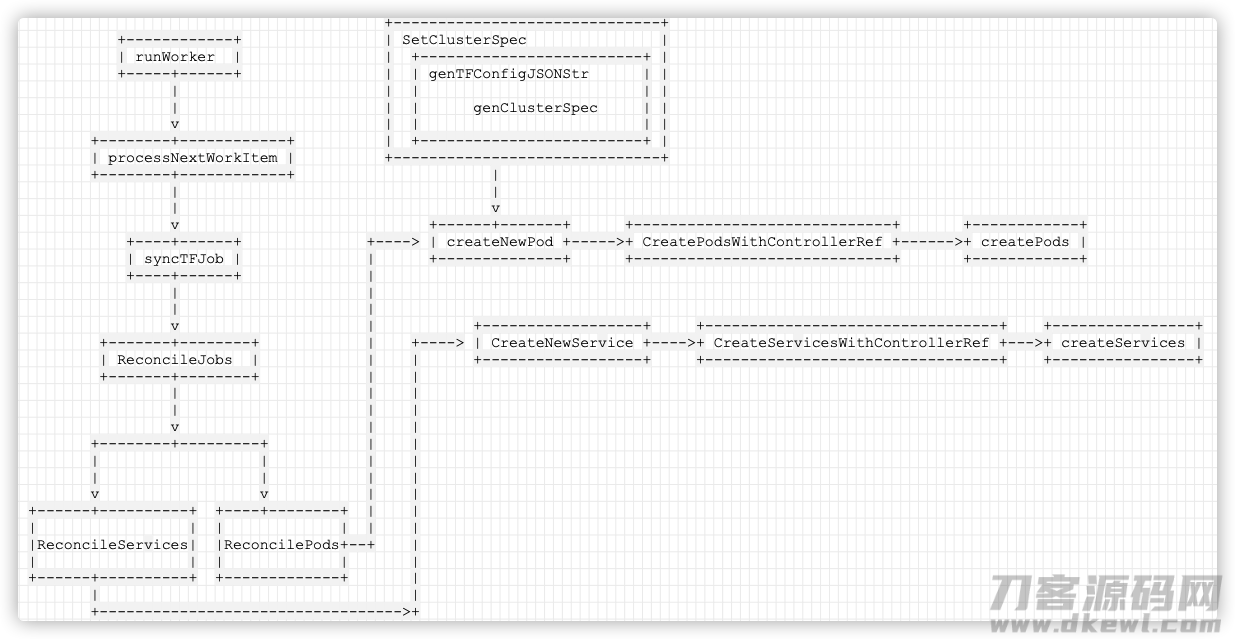
因此大家大概得知,TF-Operator 实质上便是:
- 根据 TF-Operator 的这类自定資源目标来叙述分布式系统深度学习的训练科目;
- 与此同时完成了 TFJob 的 Controller 来操纵器皿的生死轮回,给用户管理系统好几个过程中间的关联;
0x05 与一般布署较为
剖析到这儿,大伙儿很有可能也有点儿疑虑,到底 TF on K8s 和 一般布署有啥差别,优点哪里呢?大家下边就深入分析下。
5.1 运作
大家最先看源代码中的Dockerfile內容
FROM tensorflow/tensorflow:1.5.0
ADD . /var/tf_dist_mnist
ENTRYPOINT ["python", "/var/tf_dist_mnist/dist_mnist.py"]
随后看一下相匹配的 spec,各自有两个 PS,4个 Worker。
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "dist-mnist-for-e2e-test"
spec:
tfReplicaSpecs:
PS:
replicas: 2
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubeflow/tf-dist-mnist-test:1.0
Worker:
replicas: 4
restartPolicy: Never
template:
spec:
containers:
- name: tensorflow
image: kubeflow/tf-dist-mnist-test:1.0
随后再安裝example,跑一个分布式系统的 mnist 训练科目。
cd ./examples/v1/dist-mnist
docker build -f Dockerfile -t kubeflow/tf-dist-mnist-test:1.0 .
kubectl create -f ./tf_job_mnist.yaml
5.2 较为
大家就简易从训炼编码看一下。
5.2.1 一般 TF
各种各样host 的配备是根据脚本制作主要参数来设定的,下边便是载入主要参数的配备运行。
# 载入主要参数
ps_spec = FLAGS.ps_hosts.split(',')
worker_spec = FLAGS.worker_hosts.split(',')
# 建立群集
num_worker = len(worker_spec)
cluster = tf.train.ClusterSpec({'ps': ps_spec, 'worker': worker_spec})
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
5.2.2 TF-Operator
最先,dist_mnist.py中有以下方法获得 cluster 信息内容。
# If not explicitly specified in the constructor and the TF_CONFIG
# environment variable is present, load cluster_spec from TF_CONFIG.
tf_config = json.loads(os.environ.get('TF_CONFIG') or '{}')
次之,在 TF-Operator 当中有以下,表明 cluster 信息内容是以这儿设定:
tfConfig = "TF_CONFIG"
随后,在 SetClusterSpec 中有以下,便是启用 K8S 插口动态性获得配备:
// SetClusterSpec generates and sets TF_CONFIG for the given podTemplateSpec.
func (tc *TFController) SetClusterSpec(job interface{}, podTemplate *v1.PodTemplateSpec, rtype, index string) error {
tfjob, ok := job.(*tfv1.TFJob)
// Do not set TF_CONFIG for local training jobs.
if !isDistributed(tfjob) {
return nil
}
// Generate TF_CONFIG JSON string.
tfConfigStr, err := genTFConfigJSONStr(tfjob, rtype, index)
// Add TF_CONFIG environment variable to tensorflow container in the pod.
for i := range podTemplate.Spec.Containers {
if podTemplate.Spec.Containers[i].Name == tfv1.DefaultContainerName {
if len(podTemplate.Spec.Containers[i].Env) == 0 {
podTemplate.Spec.Containers[i].Env = make([]v1.EnvVar, 0)
}
podTemplate.Spec.Containers[i].Env = append(podTemplate.Spec.Containers[i].Env, v1.EnvVar{
Name: tfConfig,
Value: tfConfigStr,
})
break
}
}
return nil
}
因而能够 了解,从客户角度观察,就改动了一点编码就可以。对于布署服务项目等,全是由 K8S 对接了。
客户只需在 spec 当中设置必须 是多少 worker,ps 就成。那样客户就可以把活力集中化在实体模型以上。而devops 则施展才能给你拿下一切。
0x06 汇总
综合性以前的我们可以得到 TF-Operator 以下优点:
- 根据 TF-Operator 的这类自定資源目标来叙述分布式系统深度学习的训练科目;
- 与此同时完成了 TFJob 的 Controller 来操纵器皿的生死轮回,给用户管理系统好几个过程中间的关联;
- 针对客户,只需建立一个 TFJob 的自定資源目标,在 Template 配备好有关信息,就等同于叙述好一个分布式系统训炼程序流程的实行全过程了。
- 客户能够 把活力集中化在实体模型以上。而devops 则施展才能给你拿下一切;
kubeflow/tf-operator 尽管能够 运行,可是仍然有很多缺点。
- Kubeflow 能够 在 Kubernetes 上运行根据 TensorFlow 原生态的分布式计算工作能力的工作。可是 由于后面一种并不可以容错机制,因此 Kubeflow 并不可以胡编乱造。不可以容错机制,也代表着不 能延展性生产调度。
- 应用 kubeflow/tf-operator 实行分布式系统 TensorFlow 工作,实体模型迭代更新务必等候申请办理的过程所有运行后才可以逐渐。假如群集資源不能运行全部过程,则当今工作只有等候别的工作释放出来資源。为了更好地减少資源等待的时间,能够 给工作配备特有资源池。
- 因为資源不共享资源,群集資源使用率会很低。因此 kubeflow/tf-operator 难以与此同时兼具产品研发高效率和群集使用率。
并且,最重要的是:沒有和 horovod 联络起來,沒有安裝 MPI 等手机软件,因此下面大家看一下 MPI-Operator。
0xEE 私人信息
★★★★★★生活中和技术性的思索★★★★★★
微信平台账户:罗西的思索
假如您想立即获得本人编写文章内容的消息提醒,或是想看看本人强烈推荐的技术文档,敬请期待。

0xFF 参照
tensorflow学习心得(十九):分布式系统Tensorflow
在 Kubernetes 上延展性深度神经网络训炼神器-Elastic Training Operator
在阿里云服务器上构建Kubeflow Pipelines
开发设计你的深度学习工作流引擎
像Google一样搭建深度学习系统软件3 – 运用MPIJob运作ResNet101
揭密|一探腾讯官方根据Kubeflow创建的多租户训炼服务平台身后的技术架构
https://blog.csdn.net/weixin_43970890/article/details/113863716
[KubeFlow] MPI-Operator 深层讲解
在 Amazon EKS 上提升分布式系统深度神经网络特性的最佳实践
云原生AI服务平台的加快与实践活动
云原生的延展性 AI 训炼系列产品之一:根据 AllReduce 的延展性分布式系统训炼实践活动
MPI on Kubernetes
Kubeflow/tf-operator源代码剖析
MPI,OpenMPI 与深度神经网络
根据shell实行kubectl exec并在相匹配pod器皿内实行shell命令
k8s系列 – CRD自定資源与Controller完成(完结)
TensorFlow分布式系统整套(基本原理,布署,案例)
Kubernetes Operator最佳实践
ElasticDL:蚂蚁金融开源系统根据 TensorFlow 的延展性分布式系统深度神经网络系统软件
分布式系统深度神经网络系统软件-容器化資源生产调度
根据 K8S 搭建 AI 服务平台计划方案分析
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0