摘要
MySQL就像一个人,有Server层和储存模块层两个部分。Server层是大脑和肌肉,负责处理各种任务,比如sql语句和触发器。而储存模块层则是身体,负责储存和载入数据。它们一起工作,才能让MySQL变得强大。
正文
MySQL构架
MySQL可分成Server和储存模块两一部分,如图所示1所显示。
Server层:包含手机客户端射频连接器、查看缓存文件、分析/预CPU、优化器、电动执行机构等,及其MySQL内嵌涵数和全部跨模块的作用都是在这一层完成,例如sql语句、触发器原理、主视图等。每一个一部分的作用参照
储存模块层:承担数据信息的储存和载入,为软件式构架,适用innoDB、MyISAM、Memory等好几个储存模块,InnoDB为默认设置储存模块。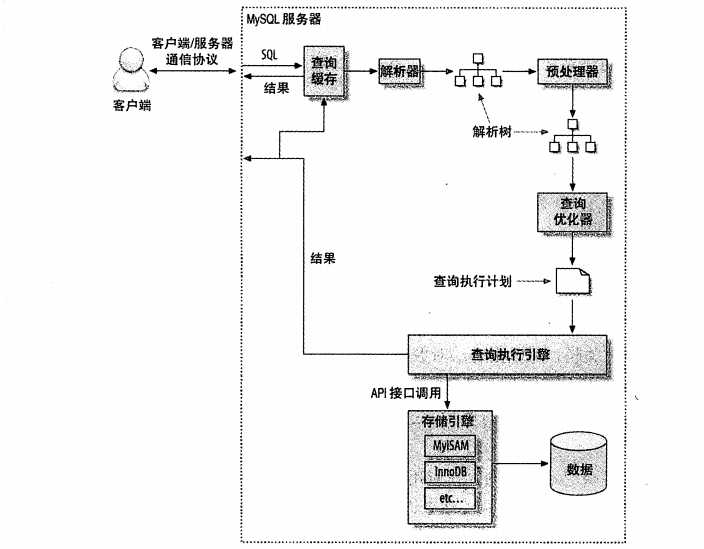
图1 MySQL逻辑性构架
表储存
表包括两一部分,表结构界定和数据信息。在MySQL中,表由储存模块承担储存,以InnoDB为例子:
- 表结构界定:在MySQL8.0以前,只有存有于.frm 后缀名文档中(MySQL Server层和InnoDB中都存有);以后容许将其放到系统软件数据分析表中。
- 表数据信息:包含数据信息段(外键约束数据库索引)和数据库索引段(二级数据库索引),由innodb_file_per_table主要参数操纵储存部位, 自5.6.6逐渐,默认设置配备为ON。
- OFF表明,储放在系统软件共享资源磁盘空间
- ON表明,独立储放在一个.ibd文档中
应用独立文档存储表数据信息,在删除表时立即删除文件夹能够回收利用室内空间。
而在共享资源磁盘空间中储存,即便将表删掉,室内空间也是不容易回收利用的。由于InnoDB 中数据以B 树形结构机构,删掉在其中一部分纪录,仅仅将其相对应的部位标识为删掉可重复使用(因为数据库索引排列,纪录只有被相对应的数据信息所重复使用);而当数据信息页上全部纪录都被删掉时,代表着数据信息页能够重复使用到随意部位。
在删掉数据信息以后而又不起作用重复使用时,便会导致数据信息裂缝;一样的,在增加时也很有可能造成数据信息裂缝,当一个数据信息页A早已写满了,但因为数据库索引的有序化,必须在A正中间再插进一条数据信息,这时候就必须开展页瓦解再申请办理一个数据信息页来储存数据信息(当今数据信息及其以后的数据库索引瓦解到新的数据信息页)。
在很多删改实际操作以后的表很有可能存有数据信息裂缝,即许多 部位没法重复使用。根据复建表能够完成室内空间收拢:
- recreate table: alter table t engine = InnoDB,能够完成线上复建表,短暂性拥有MDL写锁,以后拥有MDL读锁。应用一个rowlog储存复建表期内表数据信息的改动纪录,不容易堵塞别的事务管理的删改改。
- analyze table t 对表的数据库索引信息内容做再次统计分析,沒有改动数据信息,加MDL读锁。
- optimize table t 相当于recreate analyze。
日志
MySQL 中纪录日志的方法为WAL(Write-Ahead Logging),先预写日志再升级数据信息,针对非内存数据库而言,能够降低硬盘IO提升特性。
MySQL日志:
- binlog:在对数据信息开展删改改以后,都可能纪录一条binlog,可用以数据信息存档和备份数据,存有二种文件格式的binlog_format:
- statement纪录的是SQL句子,最终会出现COMMIT。
- row纪录的操作过程的数据信息纪录,最终会有一个XID event。
sync_binlog设定为1时,表明每一次事务管理实际操作的binlog都分布式锁到硬盘中,在MySQL出现异常重新启动后可确保binlog不遗失。
InnoDB日志:
- redolog:在对数据信息开展删改改以后,都可能纪录一条redolog。其为物理学日志,纪录的是在某一数据信息页上干了哪些改动,可用以奔溃后修复事务管理数据信息和降低升级数据信息时的硬盘IO浏览。innodb_flush_log_at_trx_commit这一基本参数成1的情况下,表明每一次事务管理的redo log都立即分布式锁到硬盘。
- undolog:在事务管理中对数据信息每开展一次改动便会纪录一次undolog,用以将全新数据修复到以前事务管理版本号。在长事务管理中很有可能占有很多储存空间。在系统软件判断undo-log没用时,会将其删掉,即在沒有比回退日志更早的Read View时。
binlog和redolog存有一个一同的数据字段XID,根据这一字段名能够将redolog和binlog关系起來,可用以事务管理修复。
数据库索引
在InnoDB中,表数据信息全是依据外键约束次序以数据库索引的方式储放的,这类储存方法的表称之为数据库索引机构表。数据库索引的最底层算法设计为B 树,因此每一个数据库索引在InnoDB上都相匹配一颗B 树,InnoDB中存有有二种种类的数据库索引:
- 聚簇索引(外键约束)
聚簇索引的叶子结点存的是整行数据信息。 - 二级数据库索引
二级数据库索引分成唯一和一般数据库索引,叶子结点中存的是外键约束的值,假如必须获得整行数据信息,必须应用主键值再去聚簇索引中回表查看。
数据库索引维护保养:因为最底层算法设计为B 树,因此维护保养数据库索引便是在维护保养B 树;而B 树是井然有序的,插进升级数据信息时很有可能造成数据信息挪动而引进附加硬盘IO。而在数据库索引字段名反复时,又会页瓦解更新的数据信息页来储存反复Key。
建立性能卓越数据库索引
B 树的高和阶:阶由页尺寸(默认设置16K)和数据库索引尺寸而决策,而高又由阶和个数决策。
InnoDB 事务管理
数据库事务是数据库查询智能管理系统实行全过程中的一个逻辑性企业,由一个比较有限的数据库操作编码序列组成,具有四个基本上特性,原子性(Atomicity)、一致性(Consistency)、防护性(Isolation)、持续性(Duarbility)。
如何启动/回退事务管理:
- 手动式应用 BEGIN, ROLLBACK, COMMIT来完成;BEGIN 逐渐一个事务管理,ROLLBACK 事务管理回退,COMMIT 事务管理递交
- 立即用 SET AUTOCOMMIT = 0/1 来更改 MySQL 的全自动递交方式:
- 若主要参数autocommit=0(严禁全自动递交),事务管理则在客户此次对数据信息开展实际操作时全自动打开,在客户实行commit指令时递交,客户此次对数据库查询逐渐开展实际操作到客户实行commit指令中间的一系列实际操作为一个详细的事务管理周期时间。若不实行commit指令,系统软件则默认设置事务管理回退。总得来说,当前状况下事务管理的情况是全自动打开手动式递交。
- 若主要参数autocommit=1(系统软件初始值,打开全自动递交),事务管理的打开与递交又分成二种情况:
- 手动式打开手动式递交:当客户实行start transaction指令时(事务管理复位),一个事务管理打开,当实行commit指令时事务管理递交,若不实行commit指令,系统软件则默认设置事务管理回退。
- 全自动打开全自动递交:假如客户在当前状况下未实行start transaction指令而对数据库查询开展了实际操作,系统软件则默认设置客户对数据库查询的每一个实际操作为一个独立的事务管理,换句话说客户每开展一次实际操作系都是会及时递交或是及时回退。
事务管理递交:
InnoDB中事务管理分成两环节递交:
- 第一阶段是在升级完数据信息后,纪录redo-log,这时候redolog情况为prepare
- 第二阶段是在记完redo-log以后,纪录bin-log,将redolog情况置为commit
两环节递交常见于分布式架构中,InnoDB 中应用两环节递交能够确保在事务管理修复时,其binlog是恰当的;假如只纪录redolog,在修复事务管理以后便会造成数据信息与binlog不一致。
事务管理修复
归功于两环节递交,事务管理在修复以后能够确保数据与binlog的一致,事务管理修复时的分辨标准为:
- 假如redo log里边的事务管理是详细的,也就是有prepare、commit标志,则立即递交;
- 假如redo log里边的事务管理仅有详细的prepare,则分辨相匹配的事务管理binlog是不是存有而且详细的,如果是,则递交事务管理; 不然,回退事务管理。
完成事务管理防护
在InndDB中,根据MVCC(一致性主视图)完成事务管理的防护性,在InnoDB中,一行数据信息物理学上只储存全新值,但根据undolog能够回退到以前事务管理版本号,因此数据信息很有可能存有好几个版本号(事务管理Id作为区别)。MVCC就是应用事务管理Id、数据信息、undolog来完成一致性主视图(read-view),但在转化成一致性读时,可多次高三复读(Repeatable read)和读递交(read committed)的read view转化成对策不是一致的:
- 在可反复读等级下,全部事务管理存有期内都应用同一个主视图,只能获得不大于当今事务管理Id版本号数据信息,假如数据信息被升级了,就根据undolog计算获得相对应版本号的数据信息,解决了不能反复读难题。
- 在学递交等级下,主视图在每条SQL实行期内建立,只获得已提交的全新事务管理版本号数据信息,因此每条SQL见到的数据信息很有可能全是不一致的,存有不能反复读难题。
事务管理难题
- 在可反复读等级下,每条SQL应用到的锁必须直到事务管理递交或回退以后才释放出来,存有长事务时,很有可能会占有的大量的資源,如锁、undolog等,因此应防止长事务管理而且将資源占有较多的SQL放到事务管理后程开展。
- 在学递交等级下,每条SQL应用到的锁在SQL实行进行后便会释放出来,在多事务管理并行处理时,假如binlog_format=statement时很有可能导致数据信息和binlog的不一致,因此应将其设定为row。
InnoDB 行锁、空隙锁、临键锁
行锁(record lock):
InnoDB事务管理中,一条升级句子实行时,务必要得到其行写锁,而行锁分成读锁和写锁,在其中读锁中间兼容,读写锁、写锁中间相互独立,如 select id from table1 lock in share mode 当今读加读锁;select if from table1 for update 当今读加写锁。在RR级别下,行锁在必须的情况下才再加上,可是得直到事务管理完毕时才释放出来,这称为两环节锁协议书,两环节上锁协议书关键为了更好地确保事务管理的防护性(处理不能反复读)和一致性(数据信息情况一致)。
空隙锁(Gap Lock):
根据两环节锁协议书能够处理不能反复读和数据信息一致性难题,但幻读(2次当今读时,个数不一致)依然存有,就算将全部行都再加上行锁也没法处理幻读难题。空隙锁(Gap Lock)的引进便是为处理幻读难题,空隙锁锁住的纪录中间空隙,是一个区段范畴;在被空隙锁锁住的区段范畴内,不可以插进新的数据信息。
如数据库索引中存有三个聚簇连接点Id[1,3,6],事务管理A实行update table t1 set name = 'ss' where t1.id = 3,若沒有空隙锁,事务管理能够与此同时实行insert into table(id, name) values(4, 's4');但因为空隙锁的存有(1,6),事务管理B必须等候事务管理A释放出来空隙锁以后才可以增加取得成功。在当今读时,数据库索引扫描仪到的纪录都是会再加上空隙锁,区段为前开后开。
临键锁(next-key lock):
临键锁是上锁的基本要素,由行锁 空隙锁构成,区段范畴为前开后闭。在应用select * from table for update时,会将表格中全部纪录行锁和空隙都锁定,空隙锁区段为(-∞, ∞]。
上锁有两个基本准则,一是上锁基本要素为临键锁;二是数据库索引搜索全过程中浏览到的目标才会上锁。对于等价查看,有两个专业提升的点,一是在唯一索引上上锁时,临键锁衰退成形锁(唯一管束早已保证不可以增加同样数据信息);二是在一般数据库索引处时,临键锁衰退成空隙锁(空隙早已保证没法增加同样数据信息)。
InnoDB Buffer
InnoDB应用缓存池(buffer pool)管理方法运行内存,在缓存池里存有一个change buffer,用于对在数据信息开展增、删、改时开展提升,能够降低任意IO载入。innodb_change_buffer_max_size=50,表明change buffer数最多占有buffer bool的50%
InnoDB中查看纪录是一条一条的,可是载入时是以数据信息页为企业的,载入一条纪录的时候会将纪录所属的数据信息页全部载入到缓存池里。
Change Buffer的运用
数据信息的升级/插进/删掉都包含对聚簇索引和一般数据库索引的改动,这一全过程中分成二种状况:
- 假如相匹配数据信息页(聚簇和二级)早已存有于运行内存:立即升级运行内存中的数据信息页,纪录redo-log、binlog;
- 假如数据信息页没有运行内存当中,针对唯一索引(包含聚簇),必须将数据加载到运行内存中开展唯一性管束校检,校检根据再在运行内存中升级数据信息、纪录redolog;针对非唯一索引,立即将数据信息变更日志储存在change-buffer中(不写硬盘),纪录redolog、binlog。
针对一个唯一、非唯一索引皆存的表而言,针对数据信息的升级很有可能不是同歩的,外键约束、唯一索引数据信息早已在运行内存中变更、而一般数据库索引则是将变更先纪录在change buffer中,载入change buffer时也会纪录redolog、binlog,保证奔溃后修复。change buffer不但在运行内存中,也会被载入到系统软件磁盘空间中,change buffer载入硬盘的实际操作称为purge。在特殊時刻,change buffer中的实际操作会merge到原数据信息页中:一是浏览这一数据信息页时;二是后台管理进程维护保养;三是在系统软件一切正常关掉的全过程中。
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0