摘要
在了解了网络爬虫的有关定义后大家还要开展详细的操控了。而第一步就是以网页页面中得到对应的数据信息。 1. requests库详细介绍 在python中有很多适用推送的库。例如:urlib、requests、selenium、aiohttp……等。但大家当今最常见的或是requests库,这一库是根据urllib写的,英语的语法比较简单,实际操作起來十分便捷。下边咱们就直接进入主题风格,简易…
正文

1. requests库详细介绍
在python中有很多适用推送的库。例如:urlib、requests、selenium、aiohttp……等。但大家当今最常见的或是requests库,这一库是根据urllib写的,英语的语法比较简单,实际操作起來十分便捷。下边咱们就直接进入主题风格,简易介绍一下怎么使用requests库。
2. requests安裝及应用
2.1 安裝
应用简易易操控的pip的组装方法就可以了:
pip install requests
2.2 推送要求
下边先例举一个非常简单的get请求:
import requests
response = requests.get(url='http://zx529.xyz') # 最主要的GET要求
print(response.text) #打印出回到的html文本文档
根据上边这一段编码大家就可以基本得到要想要求的站点的网页源代码了。可是大部分状况都是会出现着一些反爬方式,此刻人们就必须对requests中的主要参数开展一些加上,例如Headers、cookies、refer……等。针对大多数网址,根据加上所须要的要求主要参数就可以对网址推送要求,并获得期待的回应。针对常用的要求,应用requests都能够获得处理,例如:
requests.get('https://GitHub.com/timeline.json') #GET要求
requests.post('http://httpbin.org/post') #POST要求
requests.put('http://httpbin.org/put') #PUT要求
requests.delete('http://httpbin.org/delete') #DELETE要求
requests.head('http://httpbin.org/get') #HEAD要求
requests.options('http://httpbin.org/get') #OPTIONS要求
而要求种类大家也能在控制板中开展查询,按住 f12 或是电脑鼠标右键查验,随意开启一个数据文件就可以查询该数据文件的要求方法,要是没有数据文件得话更新一下网页页面就可以了。
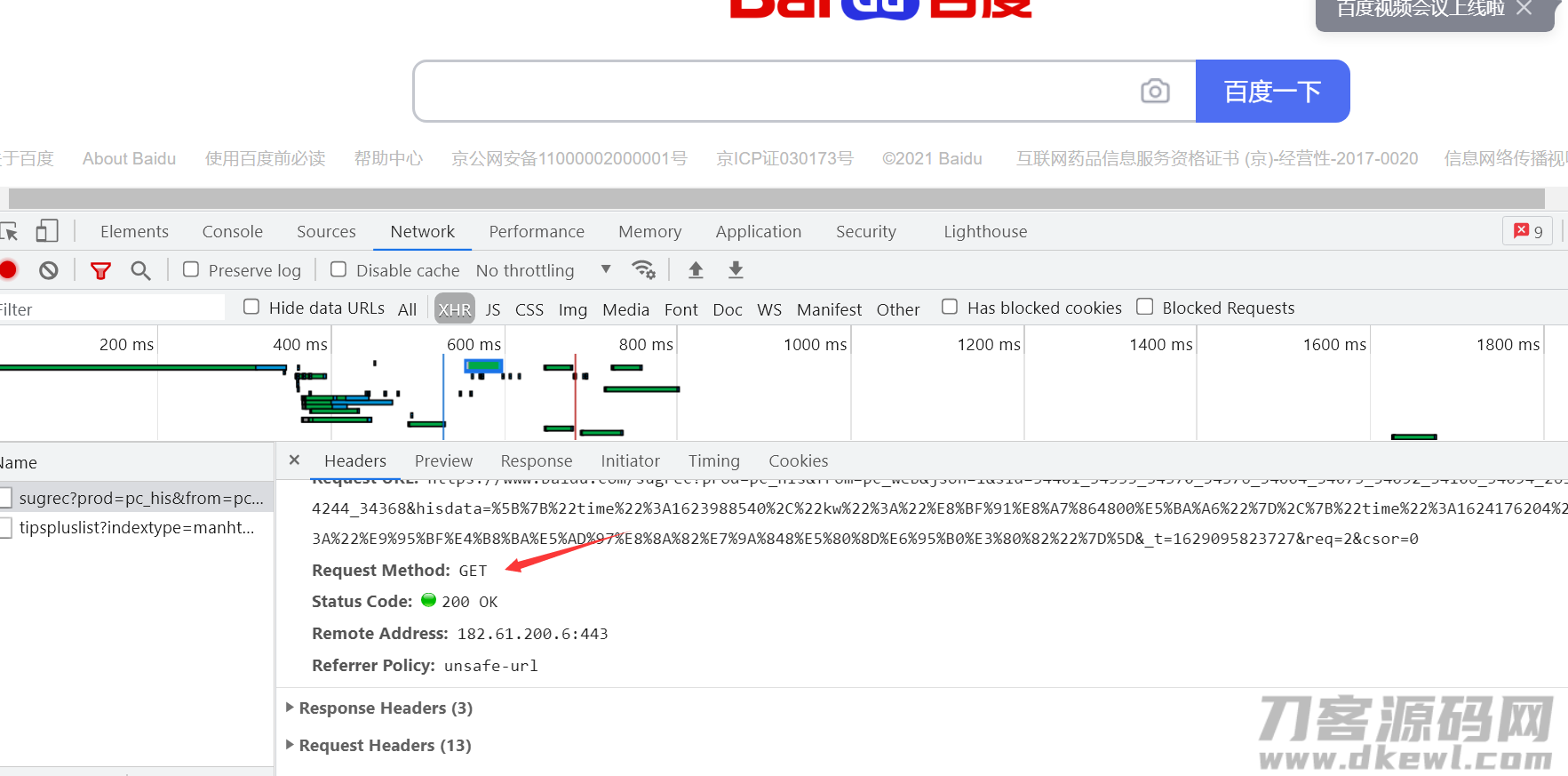
这就是非常简单的推送get请求,也就是若想要求的平台都没有所有的反扒方式时,只须要在get方式内加上url地址就可以了。可是很多网址具有着一些简洁的反爬,就必须加上一些相对应的主要参数。下边例举一些要求的主要参数:
method :要求方式get posturl:要求网站地址
params: (可选择的)查看主要参数
headers:(可选择的)词典请求头
cookies:(可选择的)词典.cookiejar目标,客户身份证信息proxies: (可选择的) ip代理
data:(可选择的)词典.目录.元组.bytespost要求的时候会使用json:(可选择的)词典递交主要参数
verify:(可选择的)是不是认证资格证书,ca证书
timeout:(可选择的)设定响应速度,一旦超出,程序流程会出错
a7low_redirects:(可选择的)是不是容许跳转,布尔类型数据信息
之上的主要参数依照发生的次数排列,在我们对网址开展要求时假如不能够恰当发生预计的相应时就可以加上这种主要参数,最常见的是Headers、refer、cookies。一般状况下假如无需加上cookies就如果可以的话尽可能不必加上cookies,由于cookies很有可能包括着大家的个体数据信息。
2.3 本人工作经验
我汇总一下我本人开展网络爬虫的一些提前准备。
- 先查询所要获得的信息是不是在网页源代码中,假如在网页源代码中,那只需得到网页源代码,那大家立即获得网页源代码就可以了;假如没有网页源代码中,大家就需要开启操作面板,对数据文件开展爬取,从数据文件中读取数据。依据我本人工作经验,假如网页页面是一个静态页面,并且需要得到的信息非常少产生变化,那麼所要获取的数据信息非常大很有可能就在网页源代码中,例如一些常用的图片素材网站等;假如要想要求的信息会时常升级,那麼数据信息很有可能是以数据文件的方式推送回来的,例如大家一些新闻、天气网站等。自然这就是绝大多数状况,实际的状况还需要深入分析。再下一步便是明确它的要求方法,便于于大家要求的推送。
- 推送要求以后,实际信息以控制面板打印出的为标准,由于控制面板打印出的就是大家可以立即完成使用的。而网页页面有一些构造在历经前面的各种各样3D渲染以后就与人们所获取的网页源代码有一定的进出,因而在开展数据筛选以前都以大家控制面板获得到的信息为标准。
- 要求主要参数层面假如不可以获得到就试着加上一些主要参数。先加上headers,refer,假如确实不行了再加上cookies。针对get请求,url中的要求主要参数大家可以以词典的方式放进params相匹配的技术参数中。而针对post要求,相匹配的要求数据信息则会以词典的方式放进data主要参数中。
下边大家对飞卢小说网站的具体内容实现获得,网站链接:
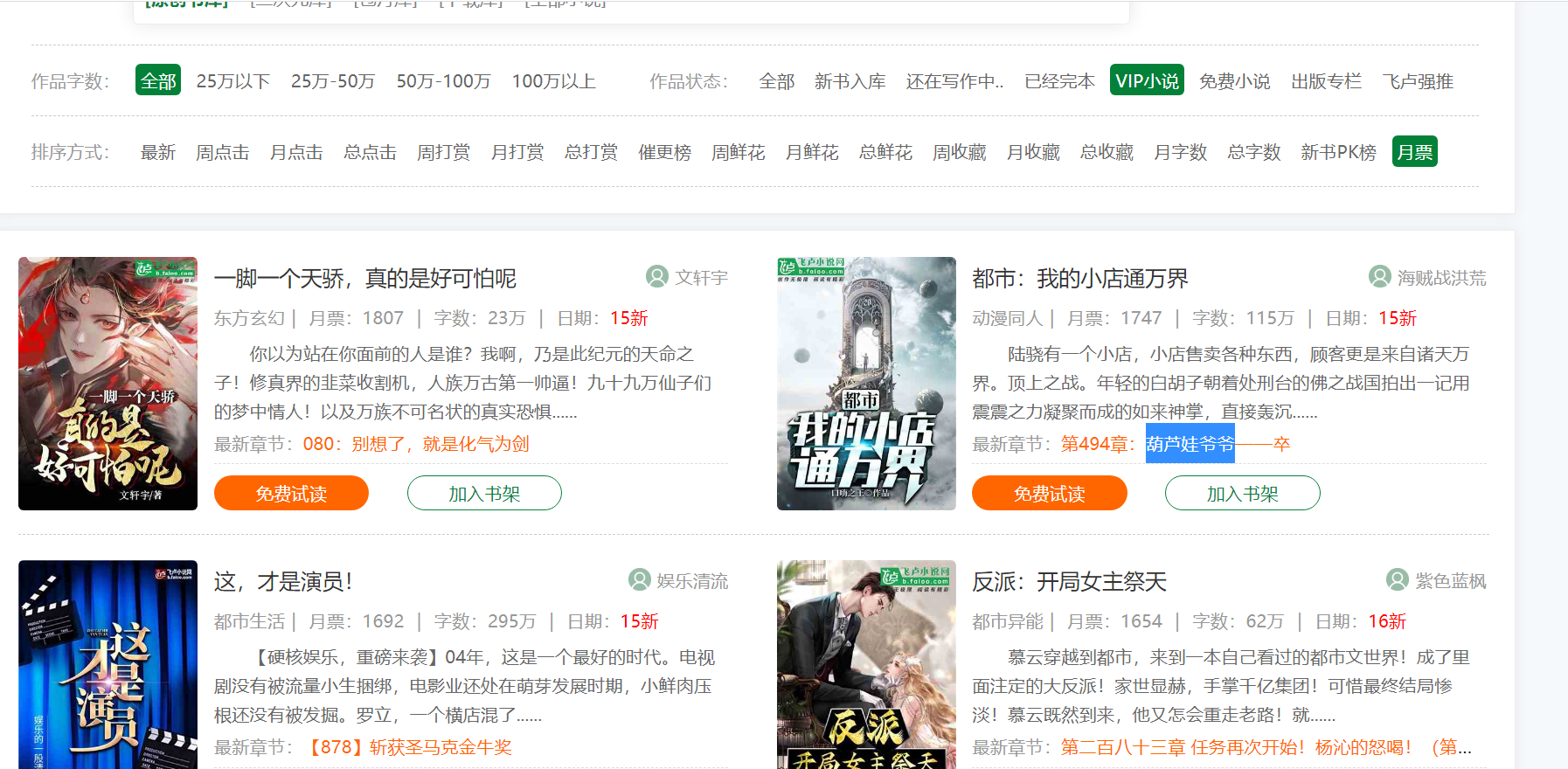
import requests
url='https://b.faloo.com/y_0_0_0_0_3_15_1.html'
response=requests.get(url).text
print(response)
根据控制面板打印出的內容,这时我们可以拷贝一段网页页面中的內容,随后到控制面板中按住 Ctrl F 开展搜索,例如我重复了一本小说的名称,在控制面板能够获得到,那麼就表明大家获得到期待的內容。
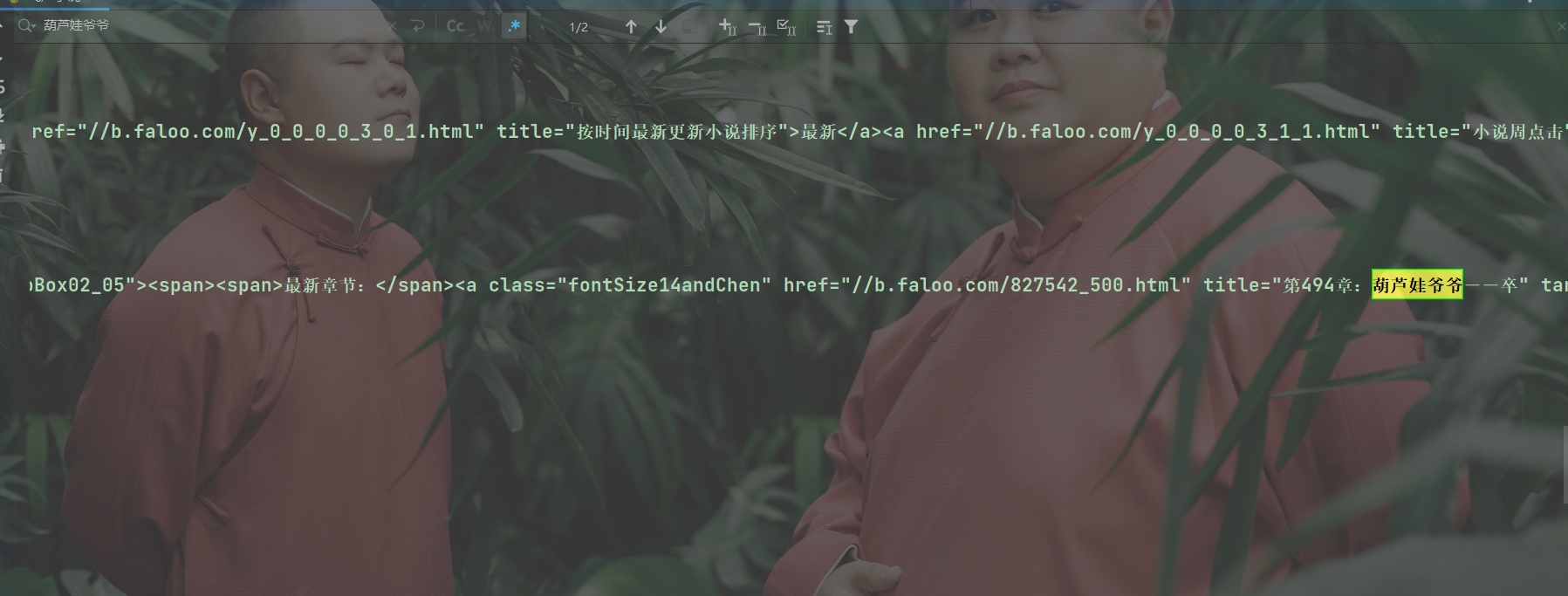
能够获得到相应的內容,表明数据信息早已被大家获得到,下一次会给我们梳理数据筛选有关的专业知识。有关requests库的有关常识我们还可以参照相应文本文档:
汉语文本文档: http://docs.python-requests.org/zh CN/latest/index.html
github详细地址: https://github.com/requests/requests
关注不迷路
扫码下方二维码,关注宇凡盒子公众号,免费获取最新技术内幕!








评论0