摘要
DeepSeek官方正版是一款先进的AI生活助手,用户可以与DeepSeek-V3模型进行互动,支持手机号、微信和APPLE ID等多种登录方式。
deepseek官方正版是一款AI生活学习助手,通过这款软件可以体验到性能世界领先的交流模型,和DeepSeek-V3模型互动交流,支持手机号、微信、APPLE ID等多种登录方式。同账号的历史对话记录和网页端直接同步,功能也是全面对齐,软件最大的优点就是联网搜索和深度思考模式,你可以问任何想问的问题,随时随地为用户答疑解惑、实现高效学习办公。
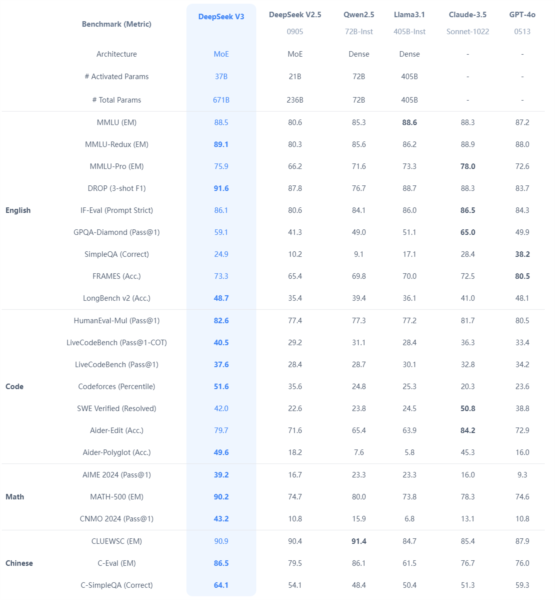
综合能力
DeepSeek-V3 在推理速度上相较历史模型有了大幅提升。
在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。
使用说明
首次调用 API
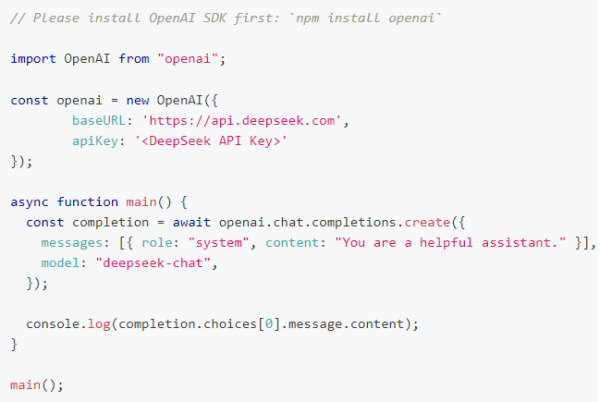
DeepSeek API 使用与 Open AI 兼容的 API 格式,通过修改配置,您可以使用 Open AI SDK 来访问 DeepSeek API,或使用与 Open AI API 兼容的软件。
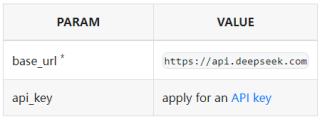
* 出于与 Open AI 兼容考虑,您也可以将 base_url 设置为 https://api.deepseek.com/v1 来使用,但注意,此处 v1 与模型版本无关。
* deepseek-ch at 模型已全面升级为 DeepSeek-V3,接口不变。 通过指定 model=’deepseek-ch at’ 即可调用 DeepSeek-V3。
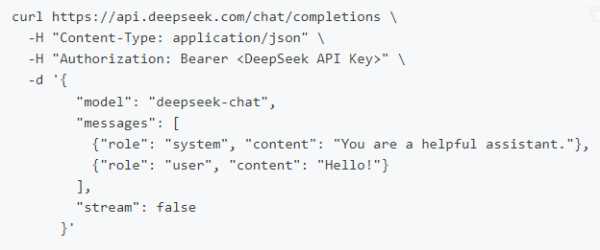
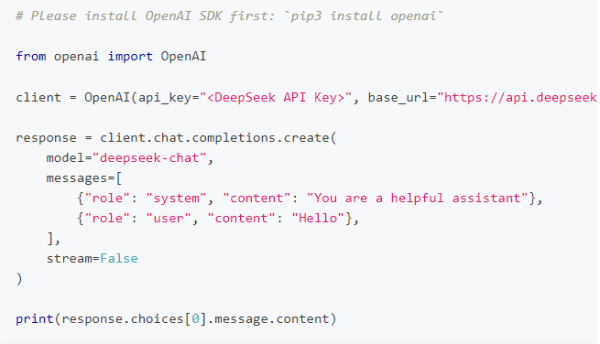
调用对话 API
在创建 API key 之后,你可以使用以下样例脚本的来访问 DeepSeek API。样例为非流式输出,您可以将 stream 设置为 true 来使用流式输出。
curl
python
nodejs
进步在哪里
V3模型和R1系列模型都是基于V3模型的更基础版本V3-Base开发的。相较于V3(类4o)模型,R1(类o1)系列模型进行了更多自我评估、自我奖励式的强化学习作为后训练。
在R1之前,业界大模型普遍依赖于RLHF(基于人类反馈的强化学习),这一强化学习模式使用了大量由人类撰写的高质量问答以了解「什么才是好的答案」,帮助模型在奖励不明确的情况下知道如何作困难的选择。正是这项技术的使用使得GPT-3进化成了更通人性的GPT-3.5,制造了2022年年底Ch atGPT上线时的惊喜体验。不过,GPT的不再进步也意味着这一模式已经到达瓶颈。
R1系列模型放弃了RLHF中的HF(human feedback,人类反馈)部分,只留下纯粹的RL(强化学习)。在其首代版本R1-Zero中,DeepSeek相当激进地启动了如下强化学习过程:为模型设置两个奖励函数,一个用于奖励「结果正确」的答案(使用外部工具验证答案的最终正确性),另一个奖励「思考过程正确」的答案(通过一个小型验证模型评估推理步骤的逻辑连贯性);鼓励模型一次尝试几个不同的答案,然后根据两个奖励函数对它们进行评分。
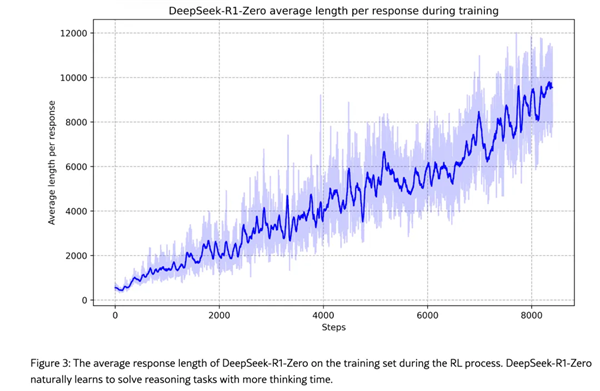
DeepSeek称,R系列模型在强化学习中涌现出了「反思」能力。
DeepSeek发现,由此进入强化学习过程的R1-Zero生成的答案可读性较差,语言也常常中英混合,但随着训练时间增加,R1-Zero能不断「自我进化」,开始出现诸如「反思」这样的复杂行为,并探索解决问题的替代方法。这些行为都未曾被明确编程。
DeepSeek称,这种「啊哈时刻」出现在模型训练的中间阶段。在此阶段,DeepSeek-R1-Zero通过重新评估其初始方法来学习分配更多的思考时间。「这一刻彰显了强化学习的力量和美妙——只要提供正确的激励,模型会自主开发高级解决问题的策略。」DeepSeek称,经过数千个这样的「纯强化学习」步骤,DeepSeek-R1-Zero在推理基准测试中的性能就与Open AI-o1-0912的性能相匹配了。
DeepSeek在论文中说,「这是第一个验证LLMs的推理能力可以纯粹通过RL(强化学习)来激励,而不需要SFT(supervised fine-tuning,基于监督的微调)的开放研究。」
不过,由于纯强化学习训练中模型过度聚焦答案正确性,忽视了语言流畅性等基础能力,导致生成文本中英混杂。为此DeepSeek又新增了冷启动阶段——用数千条链式思考(CoT)数据先微调V3-Base模型,这些数据包含规范的语言表达和多步推理示例,使模型初步掌握逻辑连贯的生成能力;再启动强化学习流程,生成了大约60万个推理相关的样本和大约20万个与推理无关的样本,将这80万个样本数据再次用于微调V3-Base后,就得到了R1——前面提到,DeepSeek还用这80万个以思维链为主的数据微调了阿里巴巴的Qwen系列开源模型,结果表明其推理能力也提升了。
更新内容
v1.0.9:
– 修复了一些已知问题
v1.0.7:
– 优化公式展示效果
– 修复部分已知问题



评论0